面试之关系型数据库
Posted yunche
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试之关系型数据库相关的知识,希望对你有一定的参考价值。
零、关系型数据库考点
- 架构
- 索引
- 锁
- 语法
- 理论范式
一、架构
面:如何设计一个关系型数据库?
这主要考察我们对关系型数据库整体架构的把握,相当于让我们自己编写一个RDBMS(关系型数据库管理系统)。设计架构图如下,可以从下图中的各个模块进行回答。

二、索引
面:为什么要使用索引?
答:为了在数据库中记录较多的时候避免每次查询都用全表扫描的方式,我们需要一种更高效的机制,那就是索引类似与字典中的目录,用来快速查询数据。
面:什么样的信息能成为索引?
答:能将某个记录限定在一定查找范围内的字段,就是一些关键信息,如主键、唯一键以及普通键等。
索引的数据结构
为了提高索引的性能,就要采取一些数据结构来加快索引的查询。索引可以采用的数据结构主要有以下几种:
- 建立二叉查找树进行二分查找
- 建立B-Tree结构进行查找
- 建立B+-Tree结构进行查找
- 建立Hash结构进行查找
二叉查找树的弊端:当对索引的数据结构进行修改后,可能会退化成链表,即时间复杂度从O(logn)降低到O(n)。即使通过旋转等方式使此树能够保证二叉查找树的结构,那么还有一个影响性能的关键因素:I/O读写。深度过深的话,I/O读写次数也会变多,效率还是很低。所以二叉查找树不适用于建立索引。
B-Tree:通过分析二叉查找树的弊端,我们可以降低树的高度来减少I/O的次数。那么B-Tree就可以派上用场了。先看下什么是B-Tree,这里的B表示balance(平衡),B-Tree是一种多路自平衡的搜索树。它类似于普通的平衡二叉树,不同的一点是B-Tree允许每个节点有更多的子节点。下图是B-Tree的简化图:
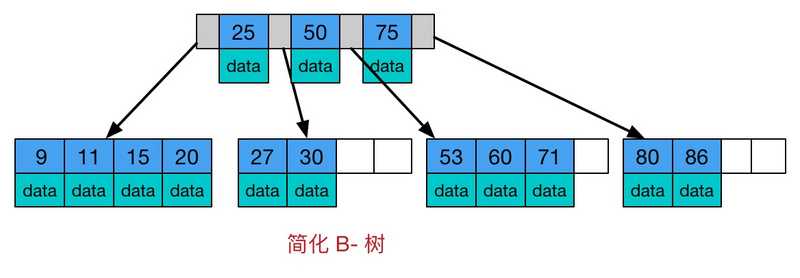
B-Tree有以下特点:
- 所有键值分布在整棵树中
- 任何一个关键字出现且只出现在一个节点中
- 搜索有可能在非叶子节点结束
- 在关键字全集内做一次查找,性能逼近二分查找
B+-Tree:B+-Tree是B-Tree的变体,也是一种多路搜索树,它与B-Tree的不同之处在于:
- 非叶子节点仅用来索引,数据都保存在叶子节点中
- 所有叶子节点均有一个链指针指向下一个叶子节点
简化B+-Tree如下图:
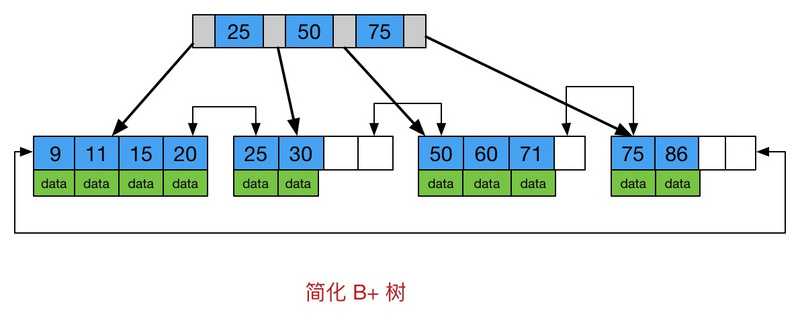
面:为什么B+-Tree相比B-Tree更适合用来做存储索引?
- B+树的磁盘读写代价更低(内部节点不存储真正数据信息)
- B+树的查询效率更加稳定(所有关键字查询都必须经过根节点到叶子节点,都是O(logn))
- B+树更有利于对数据库的扫描(只需遍历叶子节点,就可以扫描到全部的关键字)
由于B+-Tree的查询必须进过根节点到叶子节点,经过多次I/O,那么是否可考虑Hash索引呢?
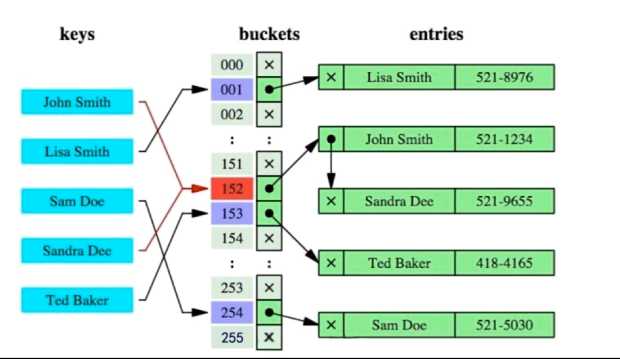
虽然Hash索引的查询效率比B+-Tree索引的查询效率要高,但同时它也有许多的弊端:
- 仅仅能满足“=”,“IN”,不能使用范围查询
- 无法被用来避免数据的排序操作
- 不能利用部分索引键查询
- 不能避免表扫描
- 遇到大量Hash值相等后的情况性能并不一定就会比B+-Tree索引高
所以综上,mysql采用B+树来作为索引的数据结构。
密集索引和稀疏索引
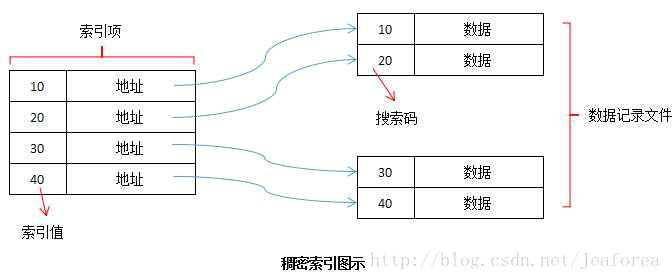
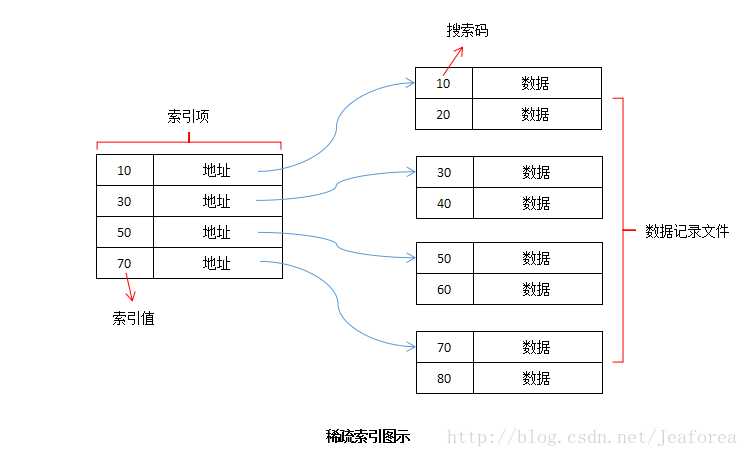
面:密集索引和稀疏索引的区别
答:
- 密集索引文件中的每个搜索码都对应一个索引值
- 稀疏索引文件只为搜索码的某些值建立索引项
- 密集索引比稀疏索引更快地定位一条记录
- 稀疏索引所占空间小,并且插入和删除时所需维护的开销也小
在MySQL中的InnoDB中,关于密集索引的知识点如下:
- 若一个主键被定义,则该主键作为密集索引
- 若没有主键被定义,该表的第一个唯一非空索引则作为密集索引
- 若不满足以上条件,InnoDB内部会生成一个隐藏主键(密集索引)
面:如何定位并优化慢查询SQL?(开放性)
答:
- 根据慢日志定位慢查询SQL
- 使用explain等工具分析SQL
- 修改SQL或者尽量让SQL走索引
实例:首先查看慢日志(DML SQL执行时间大于一定长度)的相关配置。
show VARIABLES like '%query%'在返回的结果中,关注三个变量:
| Variable_name | value |
|---|---|
| long_query_time | 1.000000 #慢查询时间的阈值 |
| slow_query_log | ON #是否开启记录慢查询日志 |
| slow_query_log_file | /home/mysql/data3001/mysql/slow_query.log #慢日志路径 |
show status like '%slow_queries%' #查看当前慢查询的条数运行语句SELECT name FROM chapter,chpater表中有50多万条记录,耗时23s。运行上面的查询慢查询条数的SQL语句,会发现增加了1,接下来通过explain工具分析。运行语句explain SELECT name FROM chapter,关注返回结果的type列发现结果是ALL,意味着是走的全表扫描,那么确实是不快的。我们来看下查询走索引的,explain SELECT id FROM chapter,type列的结果是index,走的是索引(但不是主键索引,看key列结果是fk_chapter_novel,走的是外键索引,说明主键索引不一定比其他索引快)。此时运行SELECT id FROM chapte只耗时2.9秒。来强制走下主键索引,运行语句SELECT id FROM chapter FORCE INDEX(PRIMARY),耗时23s,运行EXPLAIN SELECT id FROM chapter FORCE INDEX(PRIMARY)发现是走了主键索引的,但是耗时却和全表扫描差不多了。
面:索引是建立的越多越好吗?
答:答案当然是否定的。
- 数据量小的表不需要建立索引,建立会增加额外的索引开销
- 数据变更需要维护索引,因此更多的索引意味着更多的维护成本
三、锁
关于数据库锁部分主要回答如下问题:
- MyISAM与InnoDB关于锁方面的区别是什么
- 数据库事务的四大特性
- 事务隔离级别以及各级别下的并发访问问题
- InnoDB可重复读隔离级别下如何避免幻读
- RC(提交读)、RR(可重复读)级别下的InnoDB的非阻塞如何实现
面:MyISAM与InnoDB关于锁方面的区别是什么?
答:
- MyISAM默认使用的是表级锁,不支持行级锁
- InnoDB默认使用的是行级锁,也支持表级锁
共享锁和排它锁的兼容性
| - | X | S |
|---|---|---|
| X | 冲突 | 冲突 |
| S | 冲突 | 兼容 |
MyISAM适合的场景
- 频繁执行全表count语句
- 对数据进行增删改的频率不高(表级锁,每次都会锁住整张表),查询非常频繁
- 没有事务
InnoDB适合的场景
- 数据增删改查都相当频繁(行级锁)
- 可靠性要求比较高,要求支持事务
数据库锁的分类
- 按锁的粒度划分,可分为表级锁、行级锁、页级锁
- 按锁级别划分,可分为共享锁、排它锁
- 按加锁方式,可分为自动锁、显式锁
- 按操作划分,可分为DML锁、DDL锁
- 按使用方式划分,可分为乐观锁、悲观锁
面:数据库事务的四大特性
答:ACID
- 原子性(Atomic):事务中的所有操作要么全部执行,要么全部失败回滚
- 一致性(Consistency):确保数据库的状态从一个一致性状态转变为另一个一致性状态,一致性状态是指数据库中的数据应满足完整性约束
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应该影响其他事务的执行
- 持久性(Durability):一个事务提交后,它对数据库的修改应该永久保存在数据库中
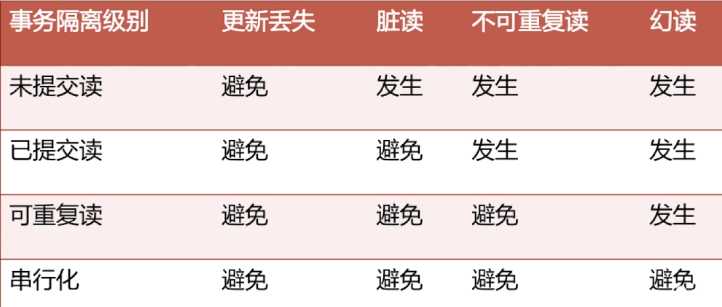
面:能说说事务隔离级别以及各级别下的并发访问问题吗?
答:MySQL事务的隔离级别由低到高分别是read uncommitted(未提交读)、read committed(提交读)、repeatable read(可重复读)、serializable(串行化)。并发访问问题及对应解决的事务隔离级别如下:
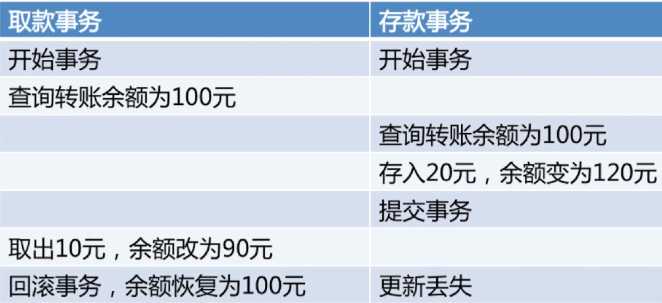
更新丢失(一个事务的更新覆盖掉了另一个事务的更新):MySQL中所有事务隔离级别在数据库层面上均可避免
实例如下图:
脏读(一个事务读到另外一个未提交事务的数据):READ-COMMITTED事务隔离级别及以上可避免
不可重复读(事务A多次读取同一数据,事务B在事务A读取的同时对该数据做了更新并提交,导致事务A多次读取到的结果不一致):REPEATABLE-READ事务隔离级别及以上可避免
幻读(事务A多次读取与搜索条件相匹配的若干行,事务B用插入或删除行的方式来修改事务A的结果集,导致事务A出现了“幻觉”):SERIALIZABLE事务隔离级别可避免
当前读与快照读
当前读的数据是最新的,而快照读读取的是快照。当前读主要是以下SQL:
select...lock in share mode
select...for update
update,delete,insert面:能说说InnoDB可重复读隔离级别下如何避免幻读吗?
答:表面上来看是通过伪MVCC的快照读(非阻塞读)实现的,但本质确实通过next-key锁即行锁+gap锁实现的。
参考资料
以上是关于面试之关系型数据库的主要内容,如果未能解决你的问题,请参考以下文章