结对第二次—文献摘要热词统计及进阶需求
Posted linziming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结对第二次—文献摘要热词统计及进阶需求相关的知识,希望对你有一定的参考价值。
格式描述
要求:链接
目标:学习如何使用Github和爬虫工具,体验结对编程
- Github项目:
爬虫部分Python代码置于PairProject2的cvpr目录下 代码签入记录:
PairProject1
PairProject2
- 分工:
- 221600124:编写爬虫部分代码、测试代码并调试
- 221600127:编写WordCount基础需求及进阶需求代码
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 42 |
| ? Estimate | ? 估计这个任务需要多少时间 | 30 | 42 |
| Development | 开发 | 700 | 1085 |
| ? Analysis | ? 需求分析(包括学习新技术) | 120 | 150 |
| ? Design Spec | ? 生成设计文档 | 50 | 50 |
| ? Coding Review | ? 设计复审 | 20 | 15 |
| ? Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| ? Design | ? 具体设计 | 120 | 60 |
| ? Coding | ? 具体编码 | 240 | 600 |
| ? Code Review | ? 代码复审 | 60 | 60 |
| ? Test | ? 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 55 | 100 |
| ? Test Report | ? 测试报告 | 20 | 30 |
| ? Size Measurement | ? 计算工作量 | 10 | 10 |
| ? Postmortem & Process Improvement Plan | ? 事后总结, 并提出过程改进计划 | 25 | 60 |
| 合计 | 785 | 1227 |
解题思路
在刚开始拿到题目后,我们小组决定使用C++实现。
- 基本功能方面,使用最基础的思路,从文件中逐渐读入字符,并且根据题目的字面要求来进行判断和统计。之后根据要求将统计字符数、统计单词数、统计最多的10个单词及其词频这三个基本功能独立出来分别写成三个函数。
- 进阶需求方面,使用python从CVPR2018官网爬取今年的论文列表。对于参数的使用,根据argc及argv来获取对应参数的数值。
设计实现过程
代码拥有countChar,countWord,countLine,countFre这四个函数,这四个函数之间是相互独立的。单元测试则是将各个函数的功能分别进行白盒测试,每个函数的功能经过10组数据的测试。
算法的关键在于对读取的字符进行判断。流程图如下:
改进程序性能
我们小组在改进程序性能上所花费的时间大约为60分钟,因此我们只是想出了改进的思路,而具体的实现可能还略有欠缺。
- 在原本的代码中是用两个数组来统计单词及其频率,之后经过查阅相关资料,我们发现可以使用C++STL中的map容器来储存该数据。并且由于map内部的数据都是自动排序的,这可以节省排序所需的时间。
- 代码存在冗余,由于在编写代码的初期只是考虑如何去实现需求的功能,而没有考虑到性能,导致其中有些代码写的比较随意,可能存在代码的重复或者无用的代码
性能分析图如下: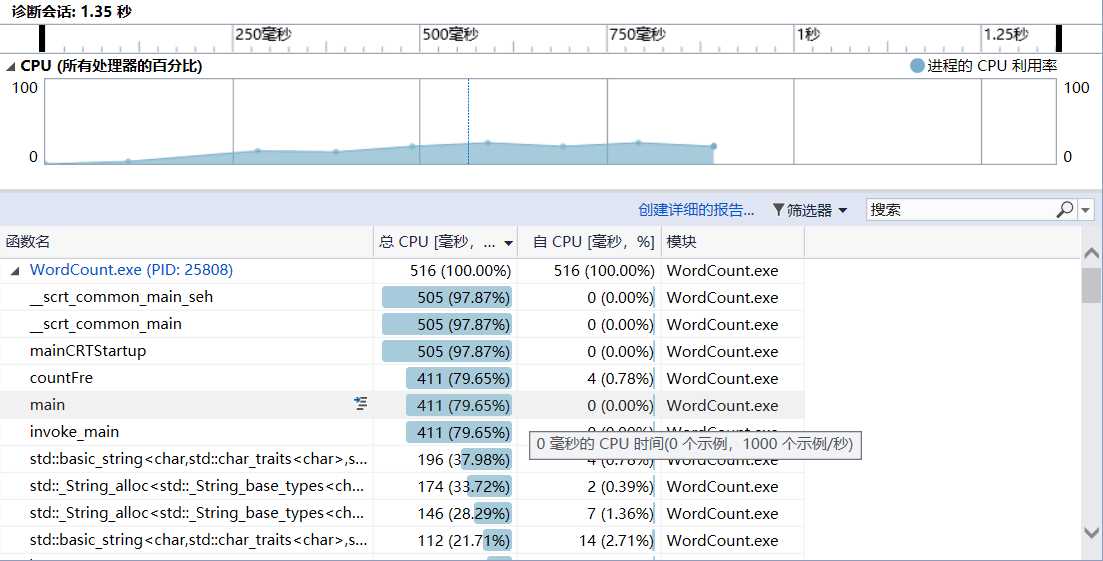
消耗最大的函数:countFre,即统计单词词频的函数
代码说明
选取countFre作为关键代码,以下为代码:
int countFre(FILE *file) {
fseek(file, 0, SEEK_SET);
char c;
string temp="";//temp变量用于保存读入的字符
int alacnt = 0;//alacnt变量用于统计当前temp字符串已有字符数
int w_cnt = 0;//w_cnt变量用于统计不重复的单词的数目
while (fscanf_s(file, "%c", &c, sizeof(char)) != EOF) {
if (c < 0 || c>255) continue;//非ascii码跳过统计
if (isalpha(c) || isdigit(c) && alacnt >= 4) {//如果字符c为字母或者字符c为数字并且temp字符串已有4个或以上字母,则将字符c加入字符串
temp += c;
alacnt++;
}
if (alacnt < 4 && !isalpha(c)) {//如果字符c不为字母并且temp字符串已有字符数小于4,则清空字符串
temp = "";
alacnt = 0;
}
if (alacnt >= 4 && !(isalpha(c) || isdigit(c))) {//如果字符c不为字母或者数字并且temp字符串已有字符数大于4,即为分隔符的情况下
bool found = false;//found用于表示该单词是否曾出现过
for (int i = 0; i < (int)temp.length(); i++)//将该单词转换为全小写
temp[i] = tolower(temp[i]);
for (int i = 0; i < w_cnt; i++) {//查找该单词是否已存在
if (temp == word[i]) {
times[i]++;
found = true;
break;
}
}
if (!found) {//如果不存在就将该单词添加到数组中
word[w_cnt] = temp;
times[w_cnt]++;
w_cnt++;
}
temp = "";
alacnt = 0;
}
}
if (alacnt >= 4) {//判断到文件结尾的最后一个字符串是否为单词
bool found = false;
for (int i = 0; i < (int)temp.length(); i++)
temp[i] = tolower(temp[i]);
for (int i = 0; i < w_cnt; i++) {
if (temp == word[i]) {
times[i]++;
found = true;
break;
}
}
if (!found) {
word[w_cnt] = temp;
times[w_cnt]++;
w_cnt++;
}
}
for (int i = 0; i < w_cnt - 1; i++) {//对词频数组进行排序
for (int j = 0; j < w_cnt - 1 - i; j++) {
if (times[j] > times[j + 1] || times[j] == times[j + 1] && word[j] < word[j + 1]) {
int temp;
temp = times[j];
times[j] = times[j + 1];
times[j + 1] = temp;
string s_temp;
s_temp = word[j];
word[j] = word[j + 1];
word[j + 1] = s_temp;
}
}
}
return w_cnt;
}单元测试
以爬虫爬取到的论文作为测试数据,每个功能有10组测试数据。
void test() {
for (char i = '0'; i <= '9'; i++) {
char s[] = "testx.txt";
s[4] = i;
FILE *in;
errno_t err;
if ((err = fopen_s(&in,s, "r")) != 0) {
printf("Open file failed!");
exit(0);
}
printf("%s
", s);
printf("characters: %d
", countChar(in));
printf("words: %d
", countWord(in));
printf("lines: %d
", countLine(in));
printf("
");
fclose(in);
}
}
int main() {
test();
system("pause");
return 0;
}总结与收获
在这次作业过程中,我们小组也遇到了许多困难。起初,我和我的队友都不会使用爬虫工具爬取
论文信息,经过我们的协商之后,我的队友选择去学习如何使用爬虫工具,而我则先负责WordCount相关功能的编写。再如我们用爬虫得到的结果做测试数据时发现程序会崩溃,后来逐渐搜索数据发现爬取所得到的论文结果中存在非ascii码字符,于是我们修改代码使得程序能够正常运行。
我认为我的队友非常可靠,他对新知识的学习能力非常出色。这次作业过程就是由他来学习爬虫的写法,并且他也没有辜负我的期望成功地完成了这项任务。但是我们可能需要更多的沟通。
附加题
我们小组在附加题方面想对数据的图形可视化做出一些努力。我们有以下两种思路:
效果如下图: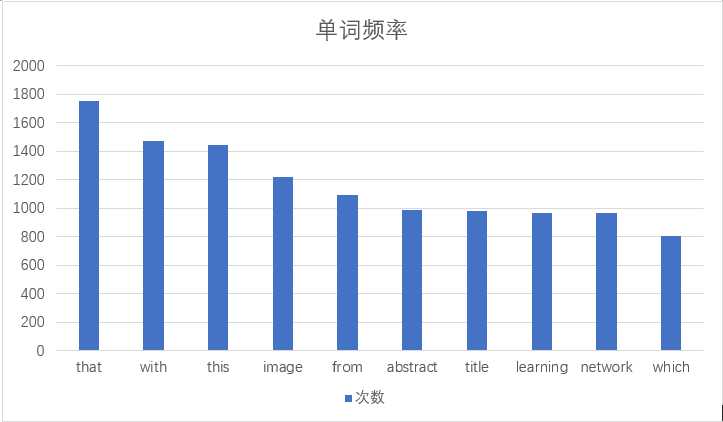
由于时间紧迫,我们并没有具体实现。
以上是关于结对第二次—文献摘要热词统计及进阶需求的主要内容,如果未能解决你的问题,请参考以下文章