数据类型补充,小数据类型
Posted jiazeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据类型补充,小数据类型相关的知识,希望对你有一定的参考价值。
. 数据类型的比较


数据类型的划分:
容器非容器划分:
容器型数据类型:list,tuple,dict,set。
非容器型数据类型:int str bool
可变与不可变划分:
可变(不可哈希hash)的数据类型:list dict,set
不可变(可哈希hash的)的数据类型: int bool str tuple
序列类型:
1.id is详解
ID 在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址: name = ‘nba‘ print(id(name)) # 1585831283968 IS is 又是什么那? == 是什么意思是那? is(身份运算)指的两边的内存地址是否相等,也就是是否是同一个地址 ==指的两边的数值是否相等 所以:如果内存地址相等,那数值一定相等,如果数值相等,内存地址不一定相等
2.代码块
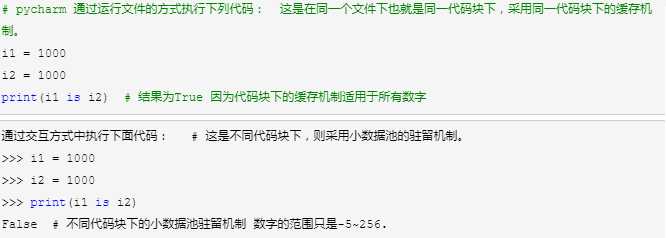
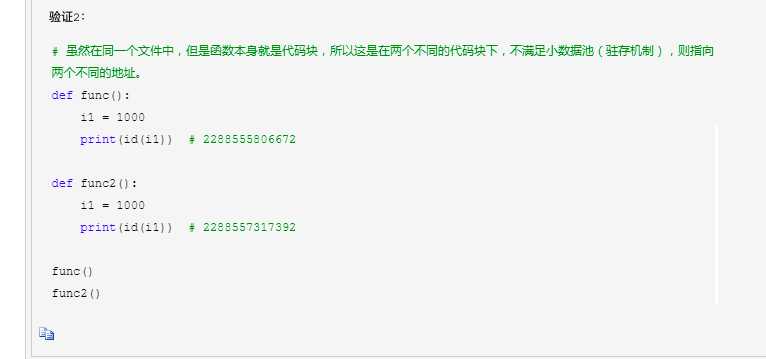
在python中一切都是对象 Python的程序是由代码块构造成的。块是python程序的一个文本,他是一个能执行的一个单元 python中的代码块:一个函数,一个模块,一个类,一个文件都是代码块,而在交互式方式输入的每条语句都是一个代码块。 那代码块和小数据池有什么关系那? 代码块的缓存机制: 在python执行同一个代码块下的初始化对象命令时(可以理解为c#中的初始化字符串),会检查该值是否存在(默认在一个字典那种去检查),如果该变量和值存在默认要检查的字典中,就重新使用该值 如果不存在,就在字典中创建该变量与值相对的映射,存入到字典当中,方便以后继续调用。 所以同一个代码块中i1=1000,i2=1000,指向的时同一个1000,即:要使用同一代码块的缓存机制,所以i1和i2指向的内存地址相同,数值也相同 代码块缓存机机制的适用范围: int(float):任何数字在同一代码块都复用 bool:True和False在内存中都以1或0表示,复用 str:几乎所有的字符串都符合 1.非乘法得到的字符都满足代码块的缓存机制 2.乘法得到的为两种: 1.乘数为1的任何字符串都满足代码块的缓存机制 2.乘数>=2时:仅含大小写字母,数字,下划线,总长度<=20,满足代码块的缓存机制 trple():空元组 None: 代码块缓存机制的优点: 1.节省内存空间 2.提升python性能 ============================================================================================================================ 小数据池 也称作小整数缓存机制,或称为驻留机制等等 小数据池是针对不同代码块之间的缓存机制 小数据池缓存机制: 小数据池缓存机制使用的不同的代码块中,在内存中开辟两个内存地址: 一个空间:-5-256 一个空间:一定规则的字符串(相乘不超过20,且乘数的是1) 小数据池适用范围 int(整数):python自动将-5-256之间的整数进行缓存(放在一个池中,可能是字典,或其他容器),当你把整数赋值给变量时,并不会直接创建对象,而是在内存中使用已经创建好的缓存对象 bool:就是True,False,无论你创建多少个变量指向True,False,那么他在内存中只存在一个1或0 str: 1.字符串的长度为0或者1,默认都采用了驻留机制(小数据池) 2.字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留 3,用乘法得到的字符串,分两种情况。 1.乘数为1时,仅含大小写字母,数字,下划线,默认驻留,含其他字符,长度<=1,默认驻留,含其他字符,长度>1,默认驻留。 2.乘数>=2时,仅含大小写字母,数字,下划线,总长度<=20,默认驻留。 小数据池的优点: 1.节省内存空间 2.提升python性能
重点:
如果在同一代码块下,则采用同一代码块下的换缓存机制。
如果是不同代码块,则采用小数据池的驻留机制。
验证1:
验证2:
3.基础数据类型之间的转换
1.int bool str三者之间可以进行转换 2.bool可以与所有的数据类型进行转换,所有为空的数据类型转换成bool都是false 3.字符串<--->列表 str--->list li=str.spilt() list--->str str=‘.‘.join(list) #其中list里面的元素必须都是字符串类型 4.字符串<--->元组 str--->tuple tu =str1.partition(‘b‘) #b是字符串中一个字符 tuple--->str str=‘.‘.join(tu) 5.列表<-->元组 list<--->tuple tuple(list)或者list(tuple) 6.字典<--->列表 dict--->list list(dict) #列表中的元素是字典里面的键值 other: 1.如果元组中只有单个元素,并期没有‘,‘逗号的时候,那么打印出来的类型为元素本身 tu = (123) print(tu,type(tu)) 2.字典的formkeys()方法:用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。 dict.formkeys(seq,[,value]),键值必须为可迭代类型 坑: 如果你的值是一个可变的数据类型, 他在内存中是一个id相同的内存地址。 dic = dict.fromkeys(‘abcd‘,[]) dic[‘a‘].append(666) dic[‘b‘].append(111) dic[‘c‘].append(222) print(dic)
4.set集合操作
set:是字典的阉割版,没有值的键 rar文件 set的作用: 1.列表去重 2.关系测试 set是无序列,但是在数字1-21之间的数字,在集合中从小到大的排序
5.拓展
# 将此列表索引为奇数位对应的元素全部删除. l1 = [11, 22, 33, 44, 55] #方法一:通过del函数的切片加步长的方式删除 del li[1::2] print(li) #方法二:错误案例 for item in range(len(li)): item % 2 ==1: ll.pop(item) print(li) ---> [11,33,44] 此方法从思路上来讲是正确的,range(len(li))根据"顾头不顾腚"原则能生成从0-5(0,1,2,3,4)五个元素,然后判断为奇数的,然后根据pop(索引)的方法来删除奇数索引。 但其实里面的一个坑在于:如果我们从前向后删除第一个为奇数索引之后,这个索引就消失了了,还剩下0 2 3 4四个索引,但是根据列表的特性,中间不能出现断裂的索引,也就是说,索引必须是连续的。 所以索引2 3 4 会向前补充,所以就会漏掉一部分索引,从而导致删除的结果不对。 #正确的删除方式: 1.在for循环里面不要对列表的大小进行改变(删除,增加元素等操作),可能会影响到后续最终结果 li1=[] for item in range(len(li)): if item % 2 ==0: li1.append(li[item]) li=li1 print(li) 2.根据题意来说,从后向前删除列表,不会产生以上问题 for item in range(len(li)-1,-1,-1): if item % 2 ==1: li.pop(item) print(li)
拓展二
#将字典中的key中含有k元素的所有键值对删除. dic = {‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘, ‘k3‘: ‘v3‘, ‘name‘: ‘alex‘} #错误案例 for key in dic: if ‘k‘ in key: dic.pop(key) print(dic) 报错信息: dictionary changed size during iteration #正确案例 l1 = [] for key in dic: if ‘k‘ in key: l1.append(key) for key in l1: dic.pop(key) print(dic) 将符合条件的可以添加到其他对象那个之中,在进行修改 在for循环里面不要对字典的大小进行改变(删除,增加元素等操作),可能会影响到后续最终结果
以上是关于数据类型补充,小数据类型的主要内容,如果未能解决你的问题,请参考以下文章