tensorflow_code
Posted sharryling
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow_code相关的知识,希望对你有一定的参考价值。

1.MNIST数据集问题
如果下载不了就去网上下载,然后上传到jupyter,注意目录
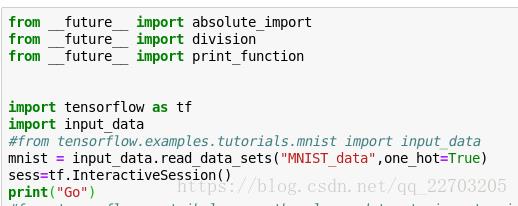
![]() ?
?
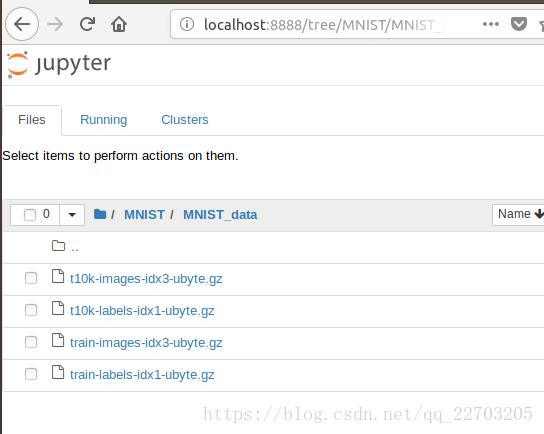
![]() ?
?
2.tensorboard_test
import tensorflow as tf
with tf.name_scope(‘graph‘) as scope:
matrix1 = tf.constant([[3., 3.]],name =‘matrix1‘) #1 row by 2 column
matrix2 = tf.constant([[2.],[2.]],name =‘matrix2‘) # 2 row by 1 column
product = tf.matmul(matrix1, matrix2,name=‘product‘)
sess = tf.Session()
writer = tf.summary.FileWriter("logs1/", sess.graph)
init = tf.global_variables_initializer()
sess.run(init)open jupyter‘s terminal
bash
tensorboard --logdir="logs1/"3.mnist_simple
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import input_data
#from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
sess=tf.InteractiveSession()x = tf.placeholder("float", [None, 784])
# 变量:网络权值
W = tf.Variable(tf.zeros([784, 10]))
# 变量:bias
b = tf.Variable(tf.zeros([10]))
# 得到模型
y = tf.nn.softmax(tf.matmul(x, W) + b)
# 使用占位符描述每张图片的标号(one-hot)
y_ = tf.placeholder("float", [None, 10])
# 计算张量的所有元素的总和
# 交叉熵作为loss function
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
# 选择算法最小化损失函数(梯度下降算法)
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# 开始在图中进行模型的计算
init = tf.initialize_all_variables()
# 启动会话
sess = tf.Session()
sess.run(init)
# 开始模型训练
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
# 计算定义好的train_step, 并且确定输入x, y_(占位符变量)
sess.run(train_step, feed_dict = {x : batch_xs, y_ : batch_ys})
# 完成训练后,variable的值会被自动更新
# W, b的值即为神经网络学习得到参数
# 使用测试数据集评估模型性能
# 得到最大值1所在的下标索引值
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# 得到准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(sess.run(accuracy, feed_dict = {x : mnist.test.images, y_ : mnist.test.labels}))4.mnist_cnn
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1) #从截断的正态分布(2sigma)中输出随机值
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)
# 卷积和池化
#卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小
# x:做卷积的输入图像,tensor:[batch, in_height, in_width, in_channels]
# W:卷积核是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数]
# strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
# padding:"SAME" or "VALID"
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding = "SAME")
# 池化用简单传统的2x2大小的模板做max pooling
# x:表示输入
# ksize:表示池化窗口大小,一般为[1, height, width, 1]
# strides:表示窗口在每一个维度上滑动的步长,一般为[1, stride,stride, 1]
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides=[1, 2, 2, 1], padding=‘SAME‘)
# 卷积在每个5x5的patch中算出32个特征(有32个卷积核)
W_conv1 = weight_variable([5, 5, 1, 32])
# 每个特征上的偏置
b_conv1 = bias_variable([32])
# 输入图像
x_image = tf.reshape(x, [-1,28,28,1])
# 把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二层卷积
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 密集连接层
# 图片尺寸减小到7x7,加入一个有1024个神经元的全连接层
# 我们把池化层输出的张量reshape成一些向量
# 乘上权重矩阵,加上偏置,然后对其使用ReLU
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# dropout
# 为了减少过拟合,我们在输出层之前加入dropout
# 用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率
# tf.nn.dropout可以屏蔽神经元的输出,自动处理神经元输出值的scale
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 输出层
# 一个softmax层,就像前面的单层softmax regression一样
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 测试及评估性能
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
for i in range(20000): #开始训练模型,循环训练5000次
batch = mnist.train.next_batch(50) #batch大小设置为50
if i % 100 == 0:
train_accuracy = accuracy.eval(session = sess,
feed_dict = {x:batch[0], y_:batch[1], keep_prob:1.0})
print("step %d, train_accuracy %g" %(i, train_accuracy))
train_step.run(session = sess, feed_dict = {x:batch[0], y_:batch[1],
keep_prob:0.5}) #神经元输出保持不变的概率 keep_prob 为0.5
print("test accuracy %g"%accuracy.eval(session = sess,feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))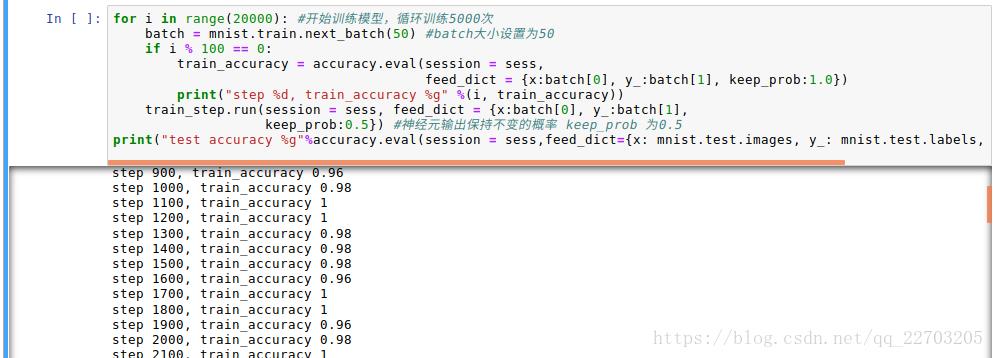
![]() ?
?
sklearn学习代码:
1.sklearn学习笔记之简单线性回归
https://www.cnblogs.com/magle/p/5881170.html
2.sklearn学习笔记之岭回归
https://www.cnblogs.com/magle/p/5878967.html
https://blog.csdn.net/fenxishichengzhang/article/details/53968592
以上是关于tensorflow_code的主要内容,如果未能解决你的问题,请参考以下文章