dropout理解~简易理解
Posted sharryling
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dropout理解~简易理解相关的知识,希望对你有一定的参考价值。
工作原理:
所谓的dropout,从字面意思理解,就是“抛弃”。
抛弃什么呢?抛弃的是网络中隐藏层的节点(输入层和输出层是由数据类型和问题类型决定的,当然不能动啦!)。
怎么抛弃呢?dropout有一个参数p,p的取值介于0和1,含义是每个节点有p概率被抛弃。
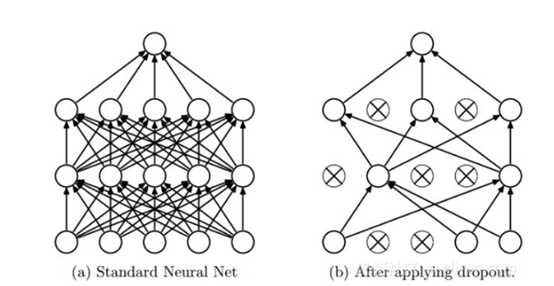
被抛弃对这个节点有什么影响呢?dropout对于节点的影响表现在,一旦某个节点被选定为抛弃的节点,那么对于神经网络的forward过程这个节点的输出就被置为0;对于backward过程,这个节点的权重和偏置不参与更新。也就是说,在某次迭代中,网络中有部分节点不参与这一次的训练,整个网络结构等效于下图右侧(左侧是dropout前的)。
![]() ?
?
为什么管用?
回归到最重要的问题:为什么dropout效果这么好。Hinton大神的解释是dropout减少了节点之间的共适应。共适应这个词说起来好专业,我举个例子来说一下我的理解:
假设一个网络中有10个节点,有一个perfect节点,它的取值刚刚好,另外9个节点的取值还需要调整,也就是所谓的一神带9坑!这个时候网络的输出层往回传递误差,这10个节点都不知道自己现在的取值是不是合适的啊,毕竟咱们开了上帝视角,而它们没有。所以它们就根据传回来的误差更新自己的取值,虽然其他9个节点可能有更合适的取值,但是这个perfect的值就破坏了啊。而且,在更新取值的时候,其他9个坑逼节点心想“这个误差是咱们10个共同造成的,嗯,我只要把我那份误差更新掉就行”,而实际上最终的误差是9个节点造成的,也就是说这些个坑逼节点对自己的错误认识还不够充分!不行,不能这么宠着它们!一个很简单的想法,就是让perfect不工作,得了,您歇着吧!这个时候9个节点就可以更好的更新自己权值,直到出现下一个perfect节点。
但是,问题是咱们也不知道哪个节点是perfect节点啊,咱们训练的时候别说上帝视角了,有时候就连哪些个节点是dead node都看不穿啊。那怎么办呢?就让部分节点先不工作吧,先富带后富。假设不工作的节点全是坑壁节点,那对于perfect节点就是好事啊,毕竟最后的误差就小了。如果不工作的节点恰好有perfect节点,那对于那些个正在工作的菜鸡节点就是好事,让他们能正确认识到自己的错误!这样网络就能训练得更好了。
当节点之间的共适应性减少了,除了能让网络取得更好的参数外,还能具有模型融合的优势。做过数据挖掘比赛的都知道,即使是几个弱鸡模型ensemble一下,也能有非常亮眼的表现。这就是dropout带来的另外一个好处。
Dropout 解决 overfitting
建立 dropout 层
本次内容需要使用一下 sklearn 数据库当中的数据, 没有安装 sklearn 的同学可以参考一下这个教程 安装一下. 然后 import 以下模块.
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import LabelBinarizer
keep_prob = tf.placeholder(tf.float32)
...
...
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
这里的keep_prob是保留概率,即我们要保留的结果所占比例,它作为一个placeholder,在run时传入, 当keep_prob=1的时候,相当于100%保留,也就是dropout没有起作用。 下面我们分析一下程序结构,首先准备数据,
digits = load_digits()可视化结果
训练中keep_prob=1时,就可以暴露出overfitting问题。keep_prob=0.5时,dropout就发挥了作用。 我们可以两种参数分别运行程序,对比一下结果。
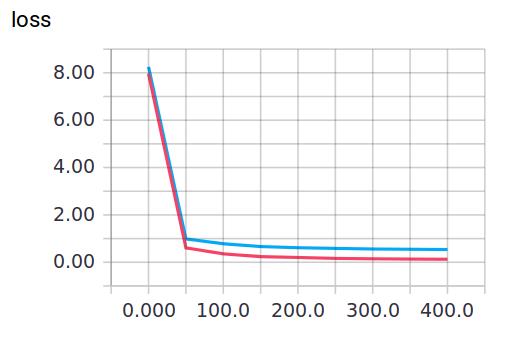
当keep_prob=1时,模型对训练数据的适应性优于测试数据,存在overfitting,输出如下: 红线是 train 的误差, 蓝线是 test 的误差.
![]() ?
?
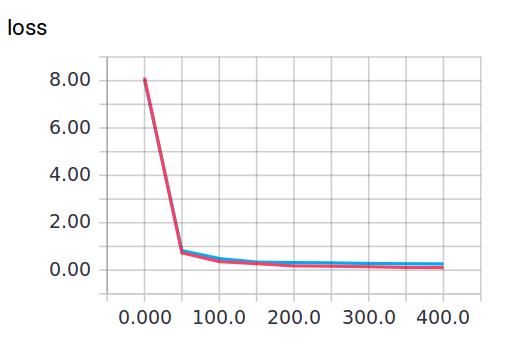
当keep_prob=0.5时效果好了很多,输出如下:
![]() ?
?
以上是关于dropout理解~简易理解的主要内容,如果未能解决你的问题,请参考以下文章
正则化之L1和L2已经dropout的一些理解和pytorch代码实现与效果证明
专知-PyTorch手把手深度学习教程05Dropout快速理解与PyTorch实现: 图文+代码