爬虫与反爬虫的较量-图片反爬
Posted lyxdw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫与反爬虫的较量-图片反爬相关的知识,希望对你有一定的参考价值。
前言
在去年6月吧,刚转行做爬虫的时候,经常拿图片网还有小说网练手,无意中发现一个壁纸网站叫做娟娟壁纸网,有好多高清壁纸(这不是广告,哈哈)
当时是写了全站爬取的代码。以为自己大工告成的时候,结果刚运行,就发现爬出来的图片不对。

每张图片都是这样,我以为遇到了IP限制,于是使用代理,结果仍然是失败。
难道是请求头做了限制?好,那我全部带上。结果依旧失败。
当时也是忙于找工作,也没静下心来仔细想,今天回过头来继续盘它。
虽然最后巧妙的用了get请求爬取成功,但是还是没搞明白原图反爬的原因。
下面来看一看究竟是怎么回事。
分析网站
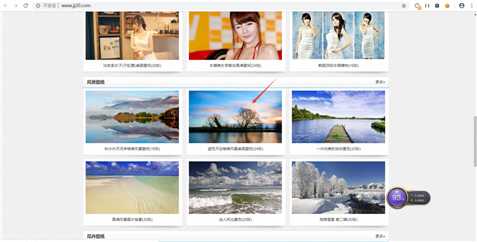
附上链接:http://www.jj20.com/bz/zrfg/ssrh/5565.html
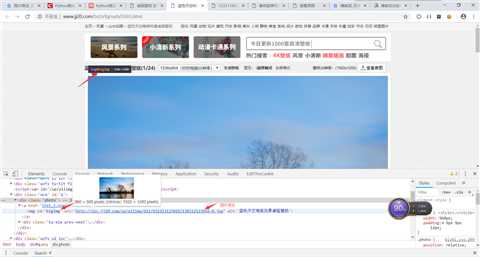
图片url在网站html代码中,我爬取的也是这张图片。
复制图片链接到浏览器访问。
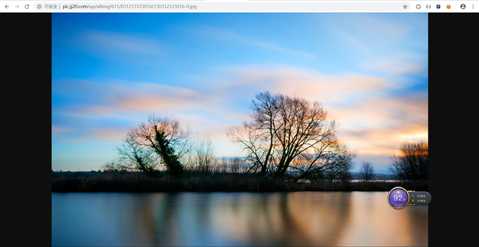
正常,浏览器能加载,爬虫为什么就不能下载。刷新图片,结果图片没了,出现了和爬虫一样的结果。
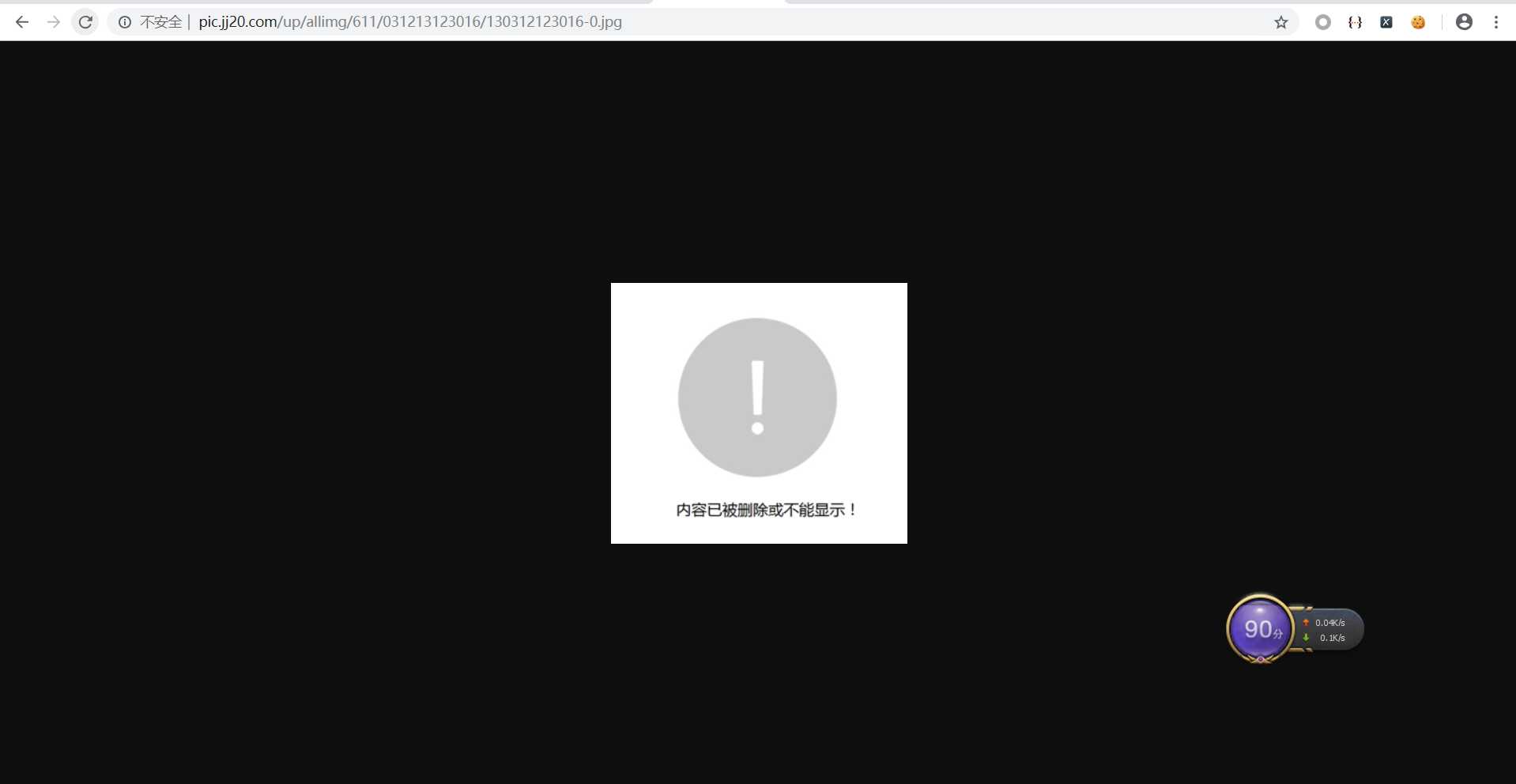
回到网站,刷新,结果,图片没了,加载不出来。
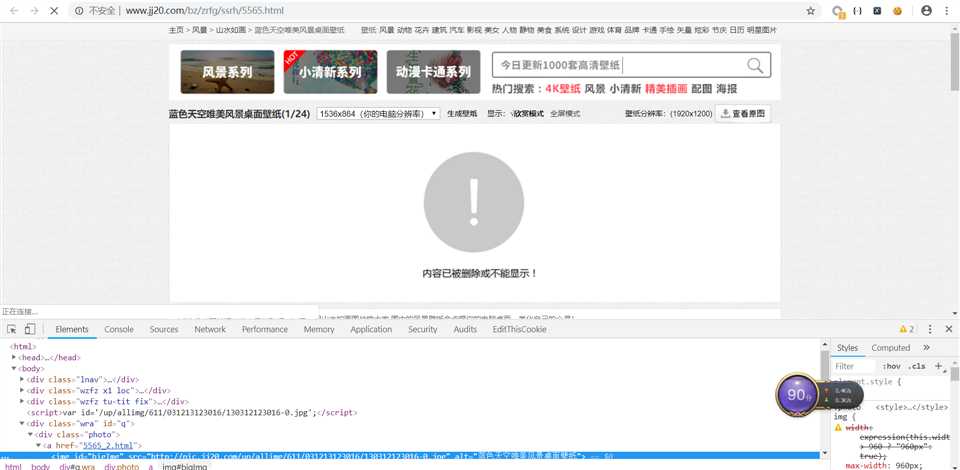
假设是缓存导致的,清理一下浏览器的cookie和缓存。再次刷新,图片又出来了。
爬虫直接请求链接会失败,具体的反爬策略,我们也不清楚。默认为图片只能在网站上加载,单独访问会失败。
从网站分析图片,网站里可能有下载链接。
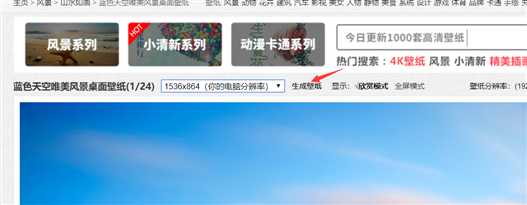
生成壁纸,根据分辨率来的,之前网站爬的应该都是原图,点进去看一下。
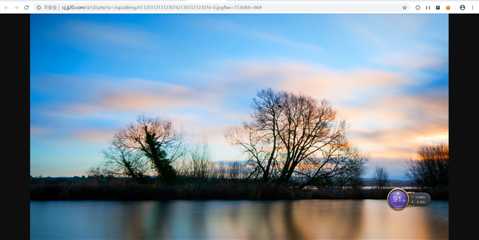
刷新,还是这张图,可以重复访问。
http://cj.jj20.com/d/cj0.php?p=/up/allimg/611/031213123016/130312123016-0.jpg&w=1536&h=864
这是一个get请求,提交了三个参数p(图片链接),w(宽),h(高),生成一张1536乘864的图片。
单张图片爬取
(写一个demo,测试了一下)
import requests url = "http://cj.jj20.com/d/cj0.php?p=/up/allimg/611/031213123016/130312123016-0.jpg&w=1536&h=864" res = requests.get(url).content #以二进制字节码保存 with open(‘1.jpg‘,‘wb‘) as f: f.write(res)
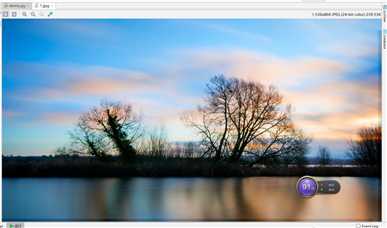
(单张图片爬取成功)宽和高都是可以自己改的,看自己桌面分辨率自己改。
本文主要介绍爬取思路,全站爬取代码后续再补充。
对于上面的网站原图反爬,我至今不是特别明白是什么原因,希望了解这方面的大牛,可以留言告知,我会尽快回复。
温馨提示
- 如果您对本文有疑问,请在评论部分留言,我会在最短时间回复。
- 如果本文帮助了您,也请评论关注,作为对我的一份鼓励。
- 如果您感觉我写的有问题,也请批评指正,我会尽量修改。
- 本文为原创,转载请注明出处。
- 本文所有代码仅供学习参考,在爬取的同时考虑对方的服务器承受能力,适可而止。
以上是关于爬虫与反爬虫的较量-图片反爬的主要内容,如果未能解决你的问题,请参考以下文章