基于skip-gram做推荐系统的想法
Posted dongguadan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于skip-gram做推荐系统的想法相关的知识,希望对你有一定的参考价值。
一、人工智能之自然语言处理
自然语言处理(Natural Language Processing, NLP),是人工智能的分支科学,意图是使计算机具备处理人类语言的能力。
“处理人类语言的能力”要达到什么效果呢?举个例子!班主任问路班长:“你能把粉笔递过来么?”。这句话有两层意思,第一层:你能不能把粉笔递过来;第二层:把粉笔递过来。Get到第一层,班长回答“能”,Get到第二层意思,班长递上粉笔。倘若班长仅回答了“能”,情景略尴尬。
对于人类来说,Get到两层意思没什么问题,但是要计算机Get到第二层意思就不那么简单。因为人类语言囊括了许多主观意识,是人从出生开始不断学习而形成的技能,如果想要计算机达到这样的效果,也需要有一个学习的过程。基于这样一个出发点,自然语言处理应运而生。
二、自然语言处理之word2vec
计算机智能保存0、1这样的数据,不会保存kitty、tom、jerry、舒克这样的文本,那么该如何表达文本呢?
1、 one-hot编码
又称独热编码、一位有效编码。直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制,如图一:
|
kitty |
1 |
0 |
0 |
0 |
|
tom |
0 |
1 |
0 |
0 |
|
jerry |
0 |
0 |
1 |
0 |
|
舒克 |
0 |
0 |
0 |
1 |
图一
举个例子:我们用{1,0,0,0}表示kitty,用{0,0,0,1}表示tom。这样kitty与tom之间的区分程度就可以用数学中的向量距离来表示。
但是one-hot有一个弊端,就是表达方式太冗余,仅仅利用了一个位置,其他位置全部浪费了。上面4个单词用了4列,其中3列为0,如果有1000个单词,那么就会有999列为0。因此需要一种更好的表达方式。
2、 Embeddings
是一组广泛应用于预测NLP建模的特征工程技术,是比one-hot更有效率的一种表达方式,如图二:
|
|
Cat |
Mouse |
|
kitty |
0.8 |
0.2 |
|
tom |
0.9 |
0.1 |
|
jerry |
0.2 |
0.8 |
|
舒克 |
0.3 |
0.7 |
图二
我们使用Cat和Mouse两个特征,kitty{0.8,0.2}与tom{0.9,0.1}之间的距离要小于kitty{0.8,0.2}与jerry{0.2,0.8}之间的距离,与直观上的感受是一致的,也可以达到区分的目的。而且空间占用相比于one-hot减小了一倍。
三、word2vec之skip-gram
首先我们要有一个直观的感受,来看下面四个句子:
1、 武磊在西班牙足球甲级联赛打入首粒入球;
2、 武磊确认为西班牙人足球队本场比赛的首发;
3、 湖人5连胜,詹姆斯三双再刷NBA历史纪录;
4、 詹姆斯又创NBA里程悲,湖人还有办法吗?
上面四个句子,我们可以发现:当“武磊”出现时,大概率会出现“足球”、“西班牙”, 小概率出现“NBA”;当“詹姆斯”出现时,大概率会出现“NBA”、“湖人”,小概率出现“足球”。
上述问题可以换一种抽象的描述:当X出现时,Y1、Y2、Y3…Yn会以较大概率出现。Skip-Gram-Naïve-Softmax模型可以处理这种情况,如图三:
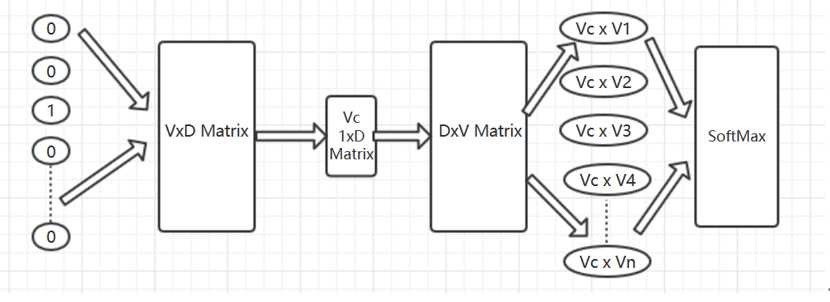
图三
假设我们的输入是最左边的one-hot-vector向量,经过VxD维矩阵M1映射为1xD的Vc向量,再经过DxV维矩阵M2映射,最后经过SoftMax成为公式一
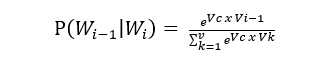 公式1
公式1
公式1可以用来用来表示的具体信息,我们暂不讨论数学公式,仅从直观上分析:要找到一种情景S使公式1最大,从而最有效的对矩阵M1、M2进行训练(参考神经网络相关知识)。
那么情景S如何选取呢,Skip-gram将情景S定义为单词的上下文,即距离目标单词Wi物理位置较近的Wi-1,Wi+1等等。比如说本节的例子,“武磊”附近大概率出现“足球”、“西班牙”,“詹姆斯”附近大概率出现“NBA”、“湖人“。
通过符合情景S的训练集,对图中的矩阵M1、M2进行训练,就可以得的单词的Embeddings表示,进而计算不同单词之间的距离。
代码实现、数据集:https://github.com/dongguadan/recommender-system.git
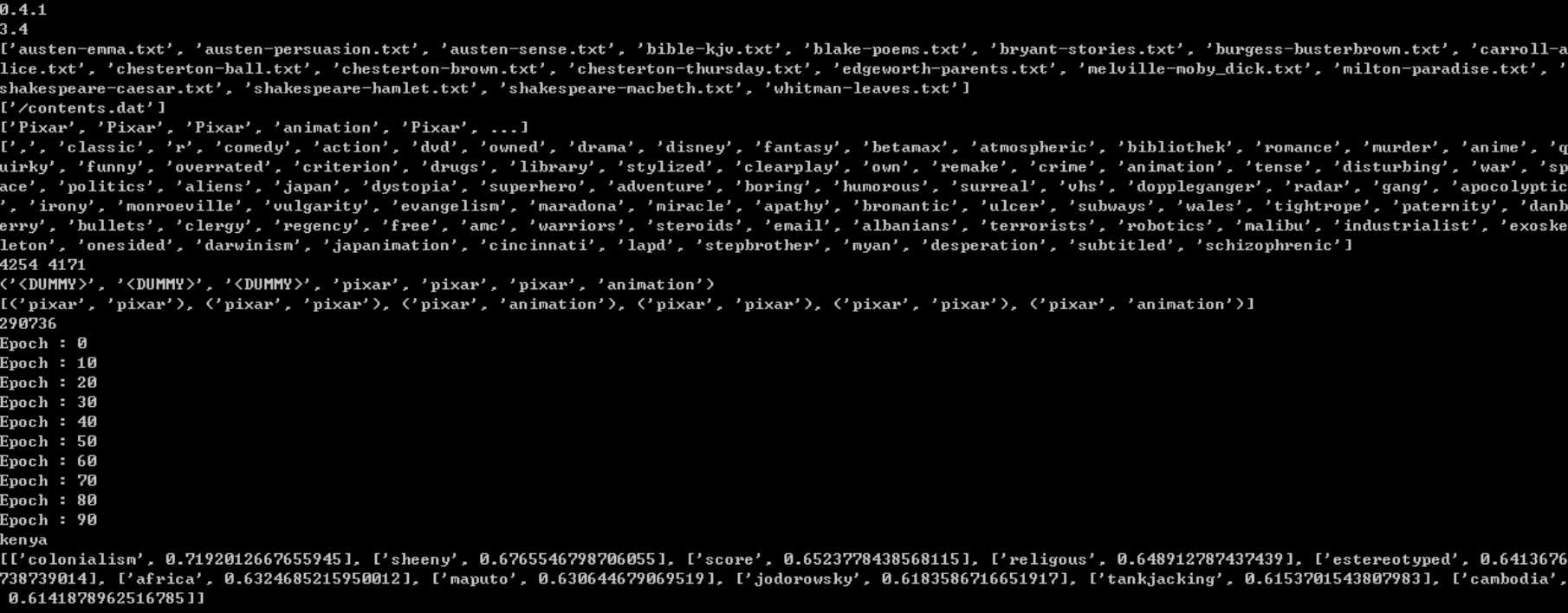
查询单词:kenya
相似度排名:
Colonialism:0.71
Sheeny:0.67
Score:0.65
Religious:0.64
Estereotyped:0.64
Africa:0.63
Maputo:0.63
Jodorowsky:0.61
Tankjacking:0.61
Cambodia:0.61
图四
四、Skip-gram应用于推荐系统
上面的数据集是基于影视评论的统计,通过计算于目标单词相似度最近的单词,可以找到与评论者近似的评论,进而对评论者的兴趣进行评估、做友好推荐。
五、参考
https://github.com/DSKSD/DeepNLP-models-Pytorch
https://www.jianshu.com/p/8e291e4ba0da
以上是关于基于skip-gram做推荐系统的想法的主要内容,如果未能解决你的问题,请参考以下文章