爬虫--1
Posted lzqrkn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫--1相关的知识,希望对你有一定的参考价值。
Python非常适合用来开发网页爬虫,理由如下:
1、抓取网页本身的接口
相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests
2、网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。
爬虫的概念:
- 通用爬虫;即将一整张页面进行数据爬取,搜索引擎抓取系统
- 聚焦爬虫;即将网页中局部内容进行爬取,与通用爬虫有关系,要先进行通用爬虫
- 增量式;只爬取最新更新的数据,或者说只爬取没有爬取过的数据
准备工作
1.抓包工具fiddler安装和配置
链接:https://pan.baidu.com/s/1eHbcXbTozMr7QVvi6Cw_mA
提取码:aohp
大妈们可以尽情下载,剩下的勿打扰好吧
直接傻瓜式安装,懂吧
安装之后打开,这里注意!!!!!
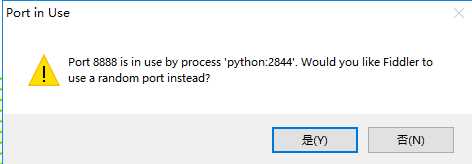
3)打开程序,点击"是"
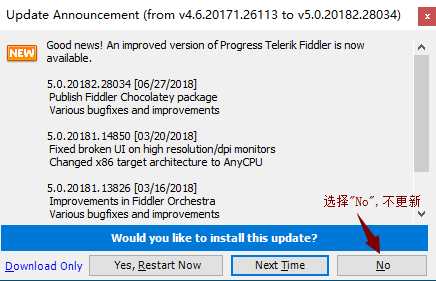
4)是否更新提示弹框,选择"No",如下图
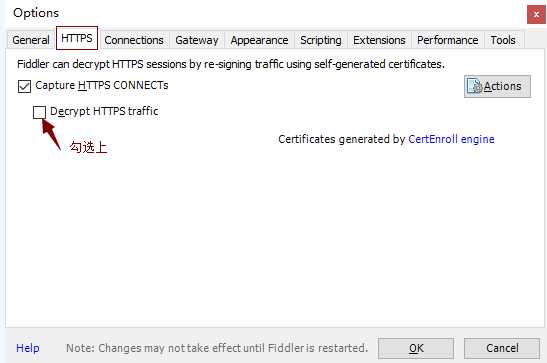
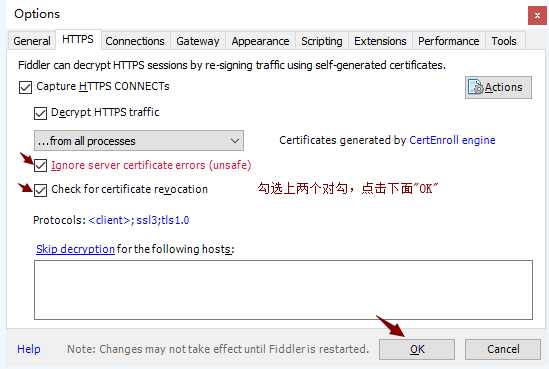
5)点击菜单的"Tools -> Options",如下图
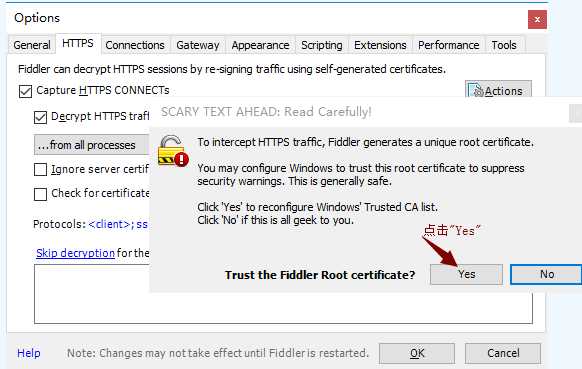
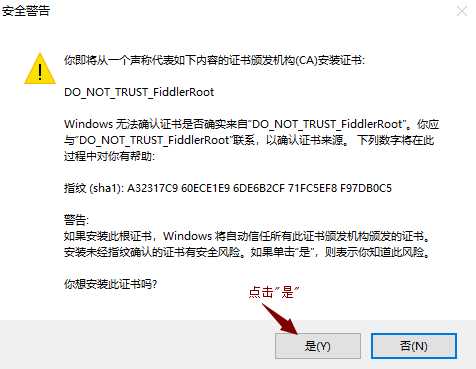
6)安装证书,如下图
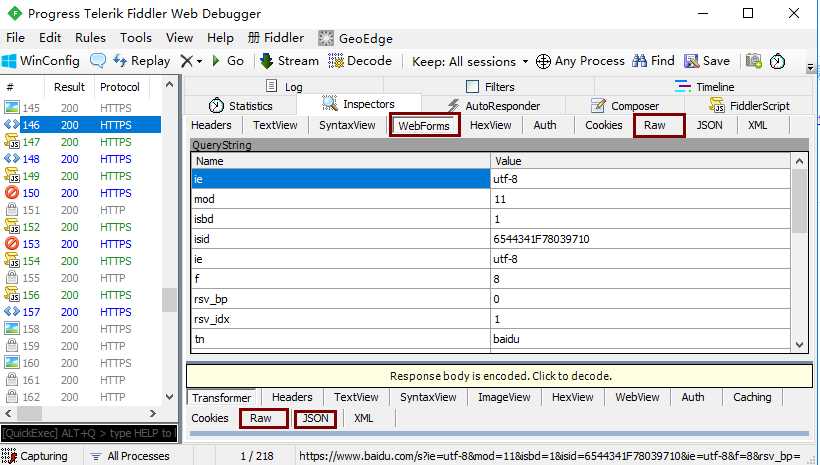
7)重启fiddler,清楚记录,我们可以在fiddler中查看,我们主要使用以下几个部分
参考博客:https://www.cnblogs.com/li-li/p/10435898.html#_label0
以上是关于爬虫--1的主要内容,如果未能解决你的问题,请参考以下文章