Python网络爬虫使用总结
Posted Anderslu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python网络爬虫使用总结相关的知识,希望对你有一定的参考价值。
网络爬虫使用总结:requests–bs4–re技术路线
简要的抓取使用本技术路线就能轻松应对。参见:Python网络爬虫学习笔记(定向)
网络爬虫使用总结:scrapy(5+2结构)
使用步骤:
第一步:创建工程;
第二步:编写Spider;
第二步:编写Item Pipeline;
第四步:优化配置策略;
工程路径:


网络爬虫使用总结:展望(PhantomJS)
如上所有的两条记录路线仅仅是对网页的处理,只能爬取单纯的html代码。就需要引出”PhantomJS”,PhantomJS是一个无界面的,可脚本编程的WebKit浏览器引擎。它原生支持多种web 标准:DOM 操作,CSS选择器,JSON,Canvas 以及SVG。
网络爬虫使用总结:scrapy框架的使用过程再次总结
创建工程、创建Spider:
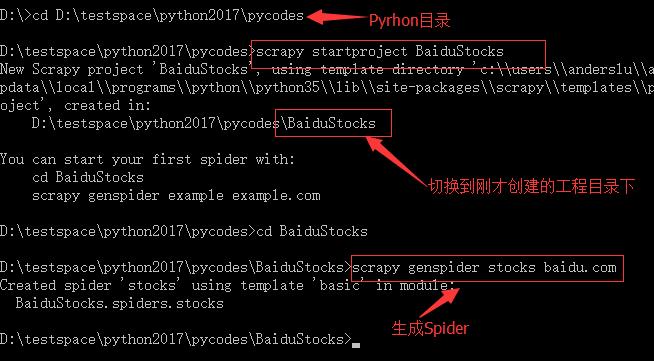
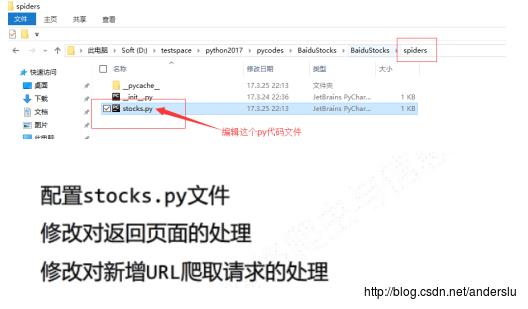
编辑Spider文件:
编写Pipelines(scrapy框架的出口):
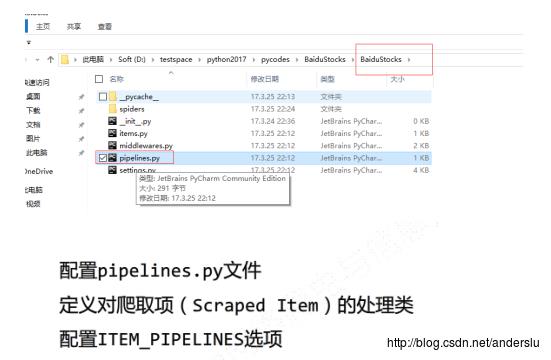
配置Item_Pipelines:

执行爬取:
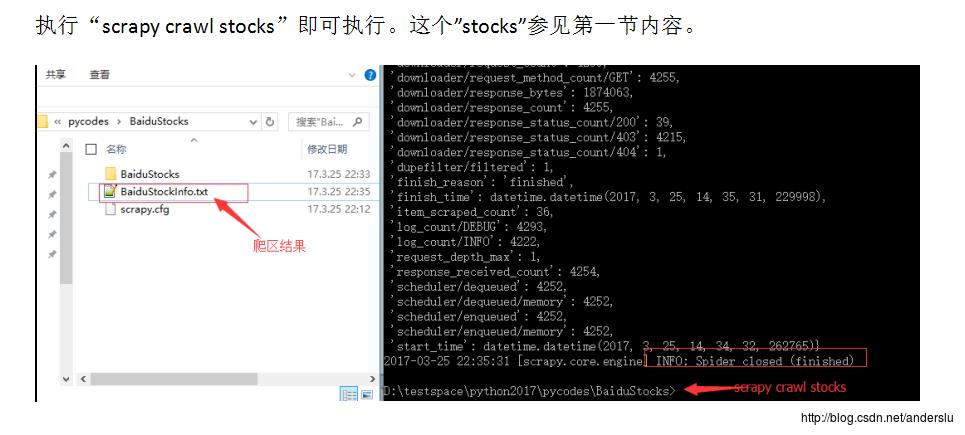
经过python网络爬虫的课程学习,python算是个入门菜鸟了。以后要陆续在工作与生活中用起来,最后感谢:Python网络爬虫与信息提取课程。
以上是关于Python网络爬虫使用总结的主要内容,如果未能解决你的问题,请参考以下文章