装饰器和闭包
Posted forwardfeilds
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了装饰器和闭包相关的知识,希望对你有一定的参考价值。
装饰器用来在不修改原函数代码的情况下,增强该函数的功能。要想熟练掌握装饰器,必须理解闭包。
闭包粗略的讲就是保存有状态的函数,它除了在装饰器中有作用之外,还是回调式异步编程和函数式编程的基础。所以闭包的重要性可想而知。
装饰器基础知识
装饰器就本质而言依然是一个函数,他接收一个函数作为参数,然后返回它,或者返回另一个函数。
1 import functools 2 def deco(func): 3 #@functools.wraps(func) 4 def inner(): 5 print("running inner()") 6 return inner 7 8 @deco 9 def target(): 10 print("running target()") 11 """ 12 target = deco(target) 与 13 @deco 14 def target(): 15 ... 16 是一样的,@只是python的语法糖而已 17 """ 18 target() 19 print(target)
使用python的@语法,虽然函数名称还是target,但是函数指针已经发生了改变,不再指向自身,而是指向deco里面的inner函数。
print(target)打印的结果是:<function deco.<locals>.inner at 0x0000000003590378>
@functools.wraps(func)的作用是把inner的函数名__name__替换成target
加上之后print(target)打印的结果就是:<function target at 0x0000000003590378>.
使用装饰器改进策略模式
1 promos = [] 2 3 #装饰器 4 def deco(func): 5 promos.append(func) 6 return func 7 8 @deco 9 def fidelity_promotion(order): 10 """ 11 为积分1000及以上的顾客提供5%的折扣 12 """ 13 return order.total()*0.05 if order.customer.fidelity >= 1000 else 0 14 15 @deco 16 def bulkitem_promotion(order): 17 """ 18 单个商品为20个及以上提供10%的折扣 19 """ 20 discount = 0 21 for item in order.cart: 22 if item.quantity >= 20: 23 discount += item.total()*0.1 24 return discount 25 26 @deco 27 def largeorder_promotion(order): 28 """ 29 订单中的不同商品达到10个及以上时提供7%折扣 30 """ 31 itemset = set(item.product for item in order.cart) 32 #print(itemset) 33 return order.total()*0.07 if len(itemset) >= 10 else 0 34 35 #最佳的折扣方案 36 def best_promotion(order): 37 return max(promo(order) for promo in promos) 38 39 print("------------------------") 40 joe = Customer(‘John Doe‘, 0) 41 ann = Customer(‘Ann Smith‘, 1100) 42 cart = [ 43 LineItem(‘banana‘, 4, .5), 44 LineItem(‘apple‘, 10, 1.5), 45 LineItem(‘watermellon‘, 5, 5.0) 46 ] 47 48 print(Order(joe, cart, best_promotion)) 49 print(Order(ann, cart, best_promotion))
使用装饰器修饰几个promotion函数,装饰器接收函数作为参数,然后把函数名追加到promos列表中,在把袁术原封不动的返回,这样做有几个好处。
* 折扣函数可以随意定义,只有在定义前加上@deco即可加入促销策略
* 方便禁用某种策略,只需注释掉@deco
不过,多数装饰器都是会被装饰的函数。通常,装饰器会在内部定义一个内部函数,然后将他返回,替换原来的函数。使用内部函数的代码几乎都要靠闭包才能正确运行,为了理解闭包,我们先来看一下python的变量作用域。
变量的作用域
先来看一个例子
1 def f(x): 2 print(x) 3 print(y) 4 5 f(3)
毫无疑问,程序会抛出NameError: global name ‘y‘ is not defined。出现错误不奇怪,因为我们没给b赋值。
如果先给全局变量y赋值,在调用f就不会出现任何问题。
1 y = 4 2 def f(x): 3 print(x) 4 print(y) 5 6 f(3)
以为懂了?再来看一个可能会让你吃惊的例子。
1 y = 4 2 def f(x): 3 print(x) 4 print(y) 5 y += 1 6 7 f(3)
运行结果表明,程序会抛出NameError: global name ‘y‘ is not defined。一开始我也觉得很吃惊,我本以为程序会引用全局变量y,打印出4,可事实却不是这样。
python解释器会认为y是局部变量,因为 y+=1,也就相当于y=y+1,给y赋值了,那么python就会在局部作用域找y,发现y没有值,因此会报错。如果想要使用全局变量y,可以使用global关键字。
1 y = 4 2 def f(x): 3 print(x) 4 global y 5 print(y) 6 y += 1 7 8 f(3) 9 print(y) #y的值变为5
闭包
有时,人们会把闭包和函数弄混,这是有历史原因的:在函数内部定义函数的做法并不常见,直到开始使用lambda函数时才会这样做。而且,只有在涉及嵌套函数才会有闭包问题,因此许多人是同时知道这两个概念的。
闭包,也就是延伸了作用域的函数,包括函数体中的引用、不在函数体也不是全局变量的引用。关键是他能访问函数体之外的非全局变量。
学术性的话通常言简意赅、清晰准确,但不容易理解。
假设我们现在有一个avg函数,他要计算平均值,每次都有新的值加进来,因此每次的平均值可能都不一样。我们想,所以得保存之前的历史数据。
用类实现的代码如下:
1 class Average(object): 2 def __init__(self): 3 self.series = [] 4 5 def __call__(self, val): 6 self.series.append(val) 7 return sum(self.series)/len(self.series) 8 9 avg = Average() 10 print(avg(1)) 11 print(avg(2)) 12 print(avg(3)) 13 print(avg(4))
但是今天我们要学习的是闭包,所以用高级函数实现如下:
1 def make_average(): 2 series = [] 3 def average(val): 4 series.append(val) 5 return sum(series)/len(series) 6 return average 7 8 9 avg = make_average() 10 print(avg(1)) 11 print(avg(2)) 12 print(avg(3)) 13 print(avg(4))
函数make_average内部定义了一个空列表series,和一个内部函数average,average接收一个参数,然后把参数放进列表中,计算平均值,make_average最后返回average函数。
现在,我们来比较一下两者实现的差别。
类的方式实现很明显,他把所有的历史数据都放在实例的series列表中,但是高阶函数里的average到哪里去找series列表呢?
注意,series定义在make_average函数中,那么在average函数中,series被称为自由变量(free variable)。指的是未在本地作用域中绑定的变量。

series参数被绑定在average函数的__closure__属性中,它是个列表,每个元素是cell对象,数据保存在cell_contents中。
1 avg = make_average() 2 print(avg(1)) 3 print(avg(2)) 4 print(avg(3)) 5 print(avg(4)) 6 print(avg.__closure__) 7 for item in avg.__closure__: 8 print(item.cell_contents)
运行结果如下:
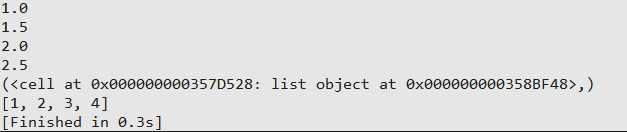
综上,闭包本质就是函数,只是他会保留定义时在函数外部存在的自由变量的绑定,这样调用函数时,虽然定义作用域不可用,但是保留的那些自由变量依然可以使用。
nonlocal声明
前面的make_average实现效率并不高,因为每次添加一个值进去,都得重新编列一遍series列表求和,如果我们能绑定历史的求和值跟元素个数,显然效率更高。
方法一:
1 def make_average(): 2 s = 0 3 n = 0 4 def average(val): 5 n += 1 6 s += val 7 return s/n 8 return average 9 10 avg = make_average() 11 avg(1)
一运行,咦?怎么报错了呢
别急,我们换种方法试一下:
方法二:
1 def make_average(): 2 s_n = {‘sum‘:0, ‘n‘:0} 3 def average(val): 4 s_n[‘n‘] += 1 5 s_n[‘sum‘] += val 6 return s_n[‘sum‘]/s_n[‘n‘] 7 return average 8 9 avg = make_average() 10 print(avg(1)) 11 print(avg(2)) 12 print(avg(3)) 13 print(avg(4))
一运行,终于没问题了。这是为什么?
在一开始,我们讨论过变量作用域的话题,方法一中, s+=val等价于 s = s+val,也就是给变量s赋值,这时,python就不再把s当成自由变量,而是当成局部变量看待,因此会报错,告诉你s是局部变量在没有赋值前被引用。再来看下为什么方法二没问题,方法二定义了一个字典,尽管在average函数里修改字典里键对应的值,但是并没有对字典本身做什么赋值操作,因此s_n绑定的还是自由变量,同理,你换成列表用append的方式也是一样的。
为了解决方法一中存在的问题,python3引入了nonlocal声明。它的作用就是把变量标记为自由变量,明确的告诉python解释器,这个变量是自由变量而非局部变量,即使在给它赋值,那也是自由变量。
正确的代码如下:
1 def make_average(): 2 s, n = 0, 0 3 def average(val): 4 nonlocal s, n #标记为自由变量 5 s += val 6 n += 1 7 return s/n 8 return average 9 10 11 avg = make_average() 12 print(avg(1)) 13 print(avg(2)) 14 print(avg(3)) 15 print(avg(4))
以上是关于装饰器和闭包的主要内容,如果未能解决你的问题,请参考以下文章