关于图像的显著性检测
Posted lf-cs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于图像的显著性检测相关的知识,希望对你有一定的参考价值。
图像显著性检测-Saliency Detection via Graph-Based Manifold Ranking
显著性检测是很多计算机处理的预处理,有限的计算机资源来处理数以亿计的图片,不仅耗资巨大,而且往往时间复杂度高。
那么如果说将这些资源集中在图片的显著性区域,就往往可以取得更好的成果,最直接的就是可以摒弃掉一些背景信息,使得“重要部分”能够凸显出来。目前关于图像显著性检测的论文有好多种类。
其中本人正在研究的一篇是《Saliency Detection via Graph-Based Manifold Ranking》,是2013年发表在IEEE上面的一篇文章,这篇文章很经典,被引用的次数也非常多,是经典的“自下而上”方法,值得我们大家反复研读和思考,这篇paper提到了一种核心算法“流形排序”,这种算法可以算是“page rank”也就是佩奇算法的延展,效果不错。下面来简单介绍一下这篇paper。
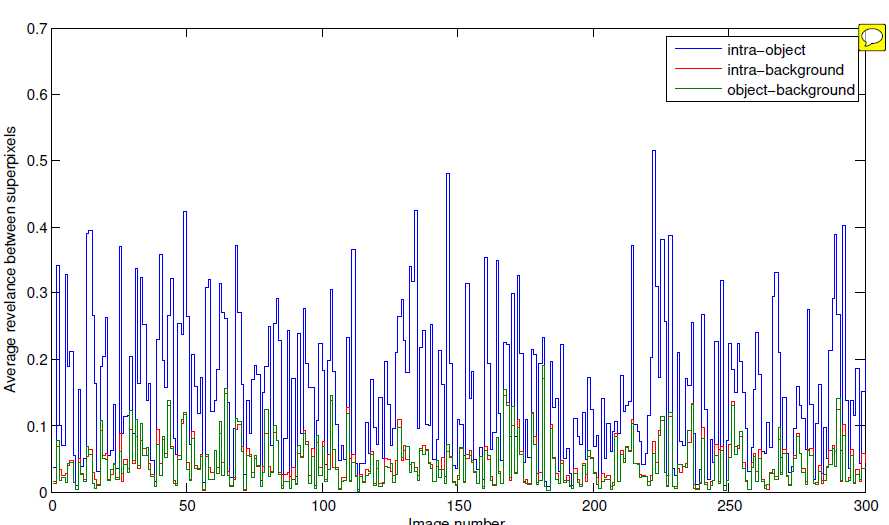
这篇文章的出发点,是有关于前景也就是目标有着很强的内相关性,放在关联矩阵中能够明显看出来和背景不一样。如下图所示蓝、红、绿色分别代表对象-内部,背景-内部,背景-目标,最高的蓝色表示对象内部之间有着很强的关联性,根据这个特点就可以在图像内部将图像前景和背景分离开。
其中最重要的也是最核心的算法就是“流形排序”。下面具体讲一下算法过程:
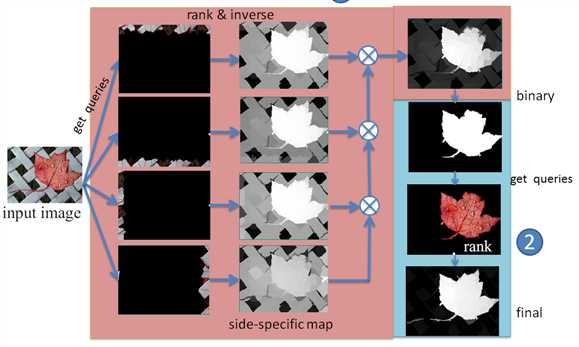
首先将图片利用SLIC方法分割成数量相对固定的超像素集合,将每个超像素看成一个节点,再设某些点为查询点,将超像素节点作为图G中的节点E,构造k-正则图,根据其他节点和查询点之间的关联进行排序,根据排名结果重新赋予超像素灰度值,形成显著图。
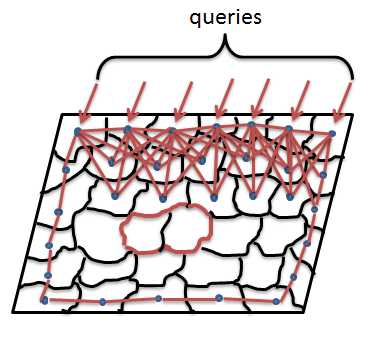
以上边界为例子解释一下算法:首先以上边界为种子节点(queries),然后每个节点都与其周围两圈节点相连,也就是说“每个节点不仅与它相邻节点相连,而且与相邻节点相连”,再将四周节点两两之间相连接,如上图所示,以上边界所有节点为种子点,其他的为未标记节点,由于连线太多影响观看,因此仅仅展示部分连接,实际上是每个节点都按照上述规则进行连接。连接之后根据超像素在Lab色彩空间的平均值来赋予边的权重。其中ci与cj是控制节点在CIE Lab色彩空间节点的平均值。
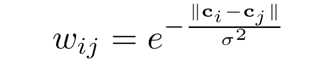
再通过优化下列问题来选取最佳排名。其中y是指示向量 [y1,y2,y3,...yn],如果每一个yi对应一个节点,如果该节点为种子点,则yi为1,否则为0。dii 与 djj 是度矩阵中的的项,D=diag{d11,d22,d33,...,dnn},其中dii为从 j=1到n, wij的和。fi与fj为第i,j个节点与其他所有节点的相关性和。
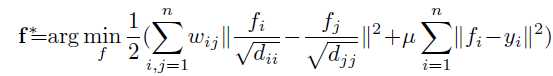
其模型化简之后得到核心模型。阿尔法 为一常数,在代码中设置为0.99。W是关联矩阵,wij是 i节点和 j节点的边的权重。
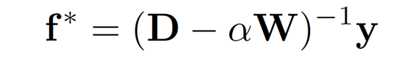
得到的 f* 是一个N维向量,每一个元素为一个节点个背景种子点的相关性,归一化该向量 [0,1] ,节点的显著性为:
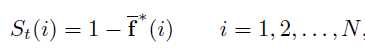
其中i表示索引图中的超像素节点, f*(i)表示归一化向量。
类似地,我们使用底部,左侧和右侧图像边界作为种子点来计算其他三个边界Sb,S1和Sr的显著性映射。我们注意到,显著图是用不同的指标向量y计算的,而权重矩阵和度矩阵D是固定的。也就是说,我们需要为每个图像计算一次矩阵的逆(D-αW)。由于超像素的数量很小,因此矩阵在方程3中的逆矩阵可以有效地计算。因此,四个映射的总计算负荷很低。通过以下过程整合四个显著性图:
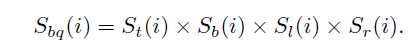
由此可以得到第一阶段的显著图。在第二阶段,要根据第一阶段产生的显著图得到的前景超像素节点,作为前景种子点,继续进行流形排序,再将两幅显著图结合,得到最终的显著图。使用SC方法生成显著性图有两个原因。首先,不同侧面的超像素通常不相似,应该具有较大的距离。如果我们同时使用所有边界超像素作为种子点(即,指示这些超级像素是相似的),则标记结果通常不太理想,因为这些节点不可压缩(如图4)。其次,它减少了不精确种子点的影响,即参考真实的突出节点被无意中选择作为后台种子点。如图5的第二列所示,使用所有边界节点生成的显著性图很差。由于标记结果不精确,具有显著对象的像素具有低显著性值。通过整合四个显著性图,可以识别对象的一些显著部分(尽管整个对象未被均匀地突出显示),这为第二阶段检测过程提供了足够的提示。

虽然显著对象的大部分区域在第一阶段突出显示,但某些背景节点可能无法被充分抑制(参见图4和图5)。为了缓解这个问题并改善结果,特别是当对象出现在图像边界附近时,通过使用前景种子点进行排名来进一步改进显著性图。
clear all;close all;clc;
addpath(‘./function/‘);
%%------------------------设置参数---------------------%%
theta = 0.1; % 控制边缘的权重
alpha = 0.99; % 控制流行排序成本函数两个项的平衡
spnumber = 200; % 超像素的数量
imgRoot = ‘./test/‘; % 测试图像的路径
saldir = ‘./saliencymap/‘; % 显著性图像的输出路径
supdir = ‘./superpixels/‘; % 超像素标签的文件路径
mkdir(supdir);
mkdir(saldir);
imnames = dir([imgRoot ‘*‘ ‘jpg‘]);
disp(imnames);
imname = [imgRoot imnames.name];
[input_im,w] = removeframe(imname); %预处理去掉边框
[m,n,k] = size(input_im);
%%----------------------生成超像素--------------------%%
imname = [imname(1:end-4) ‘.bmp‘]; %SLIC软件仅支持bmp格式的图片
comm = [‘SLICSuperpixelSegmentation‘ ‘ ‘ imname ‘ ‘ int2str(20) ‘ ‘ int2str(spnumber) ‘ ‘ supdir]; %<filename> <spatial_proximity_weight> <number_of_superpixels> <path_to_save_results>
system(comm);
spname = [supdir imnames.name(1:end-4) ‘.dat‘];
%超像素标签矩阵
fid = fopen(spname,‘r‘);
A = fread(fid, m * n, ‘uint32‘); %fread(fid, N, ‘str‘) N代表读入元素个数, ‘str‘是格式类型
A = A+1; %把A变成正整数或逻辑值
B = reshape(A,[n, m]);
superpixels = B‘;
fclose(fid);
spnum = max(superpixels(:)); %实际的超像素数目
%%----------------------设计图形模型--------------------------%%
%计算特征值 (mean color in lab color space)
%对于每个超像素
input_vals = reshape(input_im, m*n, k);
rgb_vals = zeros(spnum,1,3);
inds = cell(spnum,1);
for i = 1:spnum
inds{i} = find(superpixels==i);
rgb_vals(i,1,:) = mean(input_vals(inds{i},:),1);
end
lab_vals = colorspace(‘Lab<-‘, rgb_vals); %rgbzhuan转换成lab空间
seg_vals = reshape(lab_vals,spnum,3); % 每个超像素点的特征
% 求得边界
%求邻接矩阵
adjloop = zeros(spnum,spnum);
[m1 n1] = size(superpixels);
for i = 1:m1-1
for j = 1:n1-1
if(superpixels(i,j)~=superpixels(i,j+1))
adjloop(superpixels(i,j),superpixels(i,j+1)) = 1;
adjloop(superpixels(i,j+1),superpixels(i,j)) = 1;
end;
if(superpixels(i,j)~=superpixels(i+1,j))
adjloop(superpixels(i,j),superpixels(i+1,j)) = 1;
adjloop(superpixels(i+1,j),superpixels(i,j)) = 1;
end;
if(superpixels(i,j)~=superpixels(i+1,j+1))
adjloop(superpixels(i,j),superpixels(i+1,j+1)) = 1;
adjloop(superpixels(i+1,j+1),superpixels(i,j)) = 1;
end;
if(superpixels(i+1,j)~=superpixels(i,j+1))
adjloop(superpixels(i+1,j),superpixels(i,j+1)) = 1;
adjloop(superpixels(i,j+1),superpixels(i+1,j)) = 1;
end;
end;
end;
bd = unique([superpixels(1,:),superpixels(m,:),superpixels(:,1)‘,superpixels(:,n)‘]);
for i = 1:length(bd)
for j = i+1:length(bd)
adjloop(bd(i),bd(j)) = 1;
adjloop(bd(j),bd(i)) = 1;
end
end
edges = [];
for i = 1:spnum
indext = [];
ind = find(adjloop(i,:)==1);
for j = 1:length(ind)
indj = find(adjloop(ind(j),:)==1);
indext = [indext,indj];
end
indext = [indext,ind];
indext = indext((indext>i));
indext = unique(indext);
if(~isempty(indext))
ed = ones(length(indext),2);
ed(:,2) = i*ed(:,2);
ed(:,1) = indext;
edges = [edges;ed];
end
end
% 计算关联矩阵
valDistances = sqrt(sum((seg_vals(edges(:,1),:)-seg_vals(edges(:,2),:)).^2,2));
valDistances = normalize(valDistances); %Normalize to [0,1]
weights = exp(-valDistances/theta);
W=sparse([edges(:,1);edges(:,2)],[edges(:,2);edges(:,1)], ...
[weights;weights],spnum,spnum);
% 最优化关联矩阵 (公式3)
dd = sum(W); D = sparse(1:spnum,1:spnum,dd); clear dd; %S = sparse(i,j,s,m,n,nzmax)由向量i,j,s生成一个m*n的含有nzmax个非零元素的稀疏矩阵S;即矩阵A中任何0元素被去除,非零元素及其下标组成矩阵S
optAff = eye(spnum)/(D-alpha*W);
mz = diag(ones(spnum,1));
mz = ~mz; %将A的对角元素设置为0
optAff = optAff.*mz;
%%-----------------------------显著性检测第一阶段--------------------------%%
% 为每个超像素计算显著性值
% 作为种子点的上边界
Yt = zeros(spnum,1);
bst = unique(superpixels(1,1:n));
Yt(bst) = 1;
bsalt = optAff*Yt;
bsalt = (bsalt-min(bsalt(:)))/(max(bsalt(:))-min(bsalt(:))); %正规化数据
bsalt = 1-bsalt; %补码为显著性度量
% down
Yd = zeros(spnum,1);
bsd = unique(superpixels(m,1:n));
Yd(bsd) = 1;
bsald = optAff*Yd; %f*(i) 此向量中的每个元素表示节点与背景种子点的相关性
bsald = (bsald-min(bsald(:)))/(max(bsald(:))-min(bsald(:)));
bsald = 1-bsald;
% right
Yr = zeros(spnum,1);
bsr = unique(superpixels(1:m,1));
Yr(bsr) = 1;
bsalr = optAff*Yr;
bsalr = (bsalr-min(bsalr(:)))/(max(bsalr(:))-min(bsalr(:)));
bsalr = 1-bsalr;
% left
Yl = zeros(spnum,1);
bsl = unique(superpixels(1:m,n));
Yl(bsl) = 1;
bsall = optAff*Yl;
bsall = (bsall-min(bsall(:)))/(max(bsall(:))-min(bsall(:)));
bsall = 1-bsall;
% combine
bsalc = (bsalt.*bsald.*bsall.*bsalr);
bsalc = (bsalc-min(bsalc(:)))/(max(bsalc(:))-min(bsalc(:)));
% 为每个像素分配显著性值
tmapstage1 = zeros(m,n);
for i = 1:spnum
tmapstage1(inds{i}) = bsalc(i);
end
tmapstage1 = (tmapstage1-min(tmapstage1(:)))/(max(tmapstage1(:))-min(tmapstage1(:)));
mapstage1 = zeros(w(1),w(2));
mapstage1(w(3):w(4),w(5):w(6)) = tmapstage1;
mapstage1 = uint8(mapstage1*255);
outname = [saldir imnames.name(1:end-4) ‘_stage1‘ ‘.png‘];
imwrite(mapstage1,outname);
%%----------------------显著性检测第二阶段-------------------------%%
% 自适应阈值二值化
th = mean(bsalc); %阈值被设置为整个显著图上的平均显著性
bsalc(bsalc<th)=0;
bsalc(bsalc>=th)=1;
% 为每个超像素计算显著性值
fsal = optAff*bsalc;
% 为每个像素分配显著性值
tmapstage2 = zeros(m,n);
for i = 1:spnum
tmapstage2(inds{i}) = fsal(i);
end
tmapstage2 = (tmapstage2-min(tmapstage2(:)))/(max(tmapstage2(:))-min(tmapstage2(:)));
mapstage2 = zeros(w(1),w(2));
mapstage2(w(3):w(4),w(5):w(6)) = tmapstage2;
mapstage2 = uint8(mapstage2*255);
outname = [saldir imnames.name(1:end-4) ‘_stage2‘ ‘.png‘];
imwrite(mapstage2,outname);
以上是关于关于图像的显著性检测的主要内容,如果未能解决你的问题,请参考以下文章