线索二叉树之初步剖析(献给那些想形象思考二叉树遍历过程的人)
Posted shaonianpi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线索二叉树之初步剖析(献给那些想形象思考二叉树遍历过程的人)相关的知识,希望对你有一定的参考价值。
对于二叉树的遍历通常习惯采用递归的方法,当树的规模很大的时候,递归的深度就会很深,这就导致了对空间的浪费。在此,我们先不讨论二叉树遍历的本质,以及递归的详细过程。我先先来研究一下,二叉树本身:
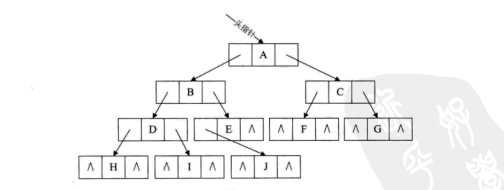
图1 二叉树
图1所示为一个二叉树的结构,我们注意结点的特征。结点包含了三个数据:存储值,指向左子节点的左指针,以及指向右子节点的右指针。
我们考虑在计算机中的实现:对于每一个节点,我们都需要分配相同大小的空间。能够指向左右子节点的指针,是有效的,因为我们能够通过这些指针访问到下一个左、右子节点。但一棵树中,还存在着空指针,尤其是叶子结点。这些空指针没有被有效的利用,严格意义上讲,就是一种浪费。很容易发现,对于一个含有n个结点的二叉树,实际上有2n个指针域(每个结点有左右两个指针)。现在思考有几个指针得到了利用,多少个没有得到利用。除了头结点没有被指针指向(假设先不考虑头指针),其余的n-1个节点都被一个指针指向。因此这2n个指针中,有n-1个指针得到了利用,则言下之意,还剩下(2n-(n-1))=n+1个指针时空指针域。那么这些没有被用到的指针可以被利用吗?
答案是肯定的,这些空指针域可以被利用,而且很好用。
我们先来回顾二叉树的遍历过程,以图1所示二叉树为例。考虑它的中序遍历:从根节点A开始,先找它的左子结点,是B;再看B,B也有左子结点,是D;D还有左子结点,是H;再看H,H没有左子结点了。所以中序遍历第一个元素为H,再看H有没有右子结点,没有,因此H以及H的后续结点(都为空)访问完毕,此时我们来访问它的前序结点,是D。..........直到遍历所有结点。
在此,我们思考这样一个问题:我们是如何在访问到了H,回头找到D的,进一步找到B的.....。对,我们的核心机制在栈,是通过弹栈的方式。我们找到了后续访问的元素。且先不谈论栈这种机制带来的巨大内存消耗,我们思考这样一个问题:假如我们知道了D的位置(仅仅是知道了D的位置,而不是知道了所有元素的位置),我们想知道树中,访问完了D,与D近邻的下面一个元素是谁???
如果我们没有更为优良的机制,我们的做法只能是:做一遍二叉树遍历(对,就是通过栈机制),遍历至少D之前所有的元素和接下来一个元素,我们才知道D接下来是谁?如果我们想访问C接下来的一个元素是谁呢?,对不起,只能遗憾的告诉你,我们要他妈遍历整个二叉树了。说到了这里,你对这个查找过程是不是看起来很眼熟??似曾相识???对,没错,这他妈就是单向链表的查找,时间复杂度为O(n)的单向链表查找!!!!(是不是恍然大悟,现在你明白了普通二叉树遍历的本质是什么了吧!!!)。
你可能觉得这也太蠢了吧,找一个元素我要遍历整颗树,没错,我也是这么想的,这是真的蠢。。。。那么有没有某种方式,使得查找不要这么蠢呢?有,这就是线索二叉树。
鉴于我画图本领不强,我就不就图1所示二叉树进行线索二叉树的详细讲解了,对此,来个简单的
比如:
以上是关于线索二叉树之初步剖析(献给那些想形象思考二叉树遍历过程的人)的主要内容,如果未能解决你的问题,请参考以下文章