机器学习初入门01-numpy的基础用法
Posted gyhmolo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习初入门01-numpy的基础用法相关的知识,希望对你有一定的参考价值。
一、numpy基础结构
1. numpy.genformtxt(‘路径名‘, delimiter = ‘分割符‘, dytype = 读取方式如str ):读取一个文件,返回一个numpy.ndarray结构的数据,这里给出了一个形式,更多参数信息参考help(numpy.genformtxt)
2. numpy.ndarray可看成是一个矩阵结构
3. numpy.array(list):把一个 list 转换成 ndarray 格式并返回,下面举两个例子
vector = numpy.array([1, 2, 3, 4]) 则vector表现为向量 [1 2 3 4]
matrix = numpy.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]]) 则matrix表现为矩阵 :

4. vector.shape:给出vector向量的形状(4, ) matrix.shape:给出matrix矩阵的形状(4,4) 下文中向量形式的ndarray用vector表示,矩阵形式的ndarray用matrix表示
5. numpy.array中的内容需要是相同的类型的,这一点与 list 有很大的不同,否则ndarray的内容类型会发生强制转换,用 .dtype如vector.dtype查看数据的类型
6. ndarray结构的数据提取、切片方式与 list 结构一样。想取矩阵的某一列:matrix[:, 列数];想取矩阵的多个列:matrix[:, 对列切片];想取子矩阵即某些行某些列:matrix[对行切片, 对列切片]
7. 在numpy中,要判断一个矩阵或者向量中是否有一个值,不需要做循环,直接:vector/matrix == 想找的值。该式子会返回一个向量/矩阵(需要加括号,如v=(vector==1),可以把(vector==1)看成是一个条件,v=(vector==1)就是对该条件做判断,然后把判断的结果返回给v),内容类型是bool型,向量/矩阵中若有该值,对应的位置为True,否则是False。返回的向量也可以作为索引,如vector[v],返回1。
二、numpy的矩阵基础
8. vector/matrix.astype(类型0):把向量或矩阵中的内容转换成类型0
9. vector.min():取vector数据数据中的最小值。想了解ndarray更多的内置属性:print(help(numpy.array))
10. matrix.sum(axis=指定维度):axis=1表示每一行的所有元素相加,把每行的总值组成一个向量并返回;axis=0表示对列操作
三、numpy的常用函数
11.?np.arange(num):创建一个有num个数据的vector,数据从0顺序排到num-1。 np.arange(起始值,终止值,步长):数据从起始值开始,最后一个值要小于终止值,相邻值相差为步长,即数据范围为 [起始值,终止值)。如np,arange(10,30,10)生成[10,20]
12. ndarray.reshape(m,n):把ndarray变成一个m*n的matrix,m*n = ndarray中数据的个数。对于向量,可直接写为vector.shape(m,n)如np.arrange(8).reshape(4,2)生成矩阵 :

13. ndarray.size:给出ndarray的数据个数 ndarray.ndim::给出ndarray的维度
14. np.zeros/ones(结构,dtype=数据类型):初始化一个全0/全1的矩阵/向量;结构为数字,则初始化向量;结构为元组(m,n),则初始化m*n的矩阵;dtype缺省时,默认数据类型为float,其他数据类型有np.int、np.str等等。np.zeros(结构, dtype=np.str)生成的ndarray的数据为空字符串。若无特殊说明,下文中出现的结构均为数字或者元组。
15. np.random.random(结构0):进入numpy的random模块,然后调用random函数,生成一个结构为结构0,数据为随机数的ndarray,数据范围为[-1,1]。
16. np.linspace(起始值,终止值,数据个数):和np.arange类似,但数据可以取到终止值,及数据范围为 [起始值,终止值],数据内容是从起始值到终止值平均分布的数。类型缺省时为float
17. ndarray**num:ndarray的数据进行num次方运算
18. 设 a=ndarray1,b=ndarray2,a*b为对应位置相乘,a.dot(b)/np.dot(a,b)为ab的矩阵乘积,当然ab的结构要符合矩阵运算规则。
四、矩阵常用操作
? ?
19. np.exp(ndarray):对ndarray中的所有数据做exp运算 np.sqrt(ndarray):对ndarray中的所有数据进行开方操作。
20. np.floor(ndarray):取整操作对数据进行向下取整。
21. np.flatten(matrix): 对矩阵做扁平化处理,把矩阵拉扯为一个向量。
22. matrix.T:对矩阵转置。
23. np.hstack(a,b):横向拼接矩阵a和b,常用于拼接特征,即给原来的样本增加特征。 np.vstack(a,b):纵向拼接矩阵a和b,常用于拼接样本,即增加样本数量。
24. np.hsplit(a,num):横向切割矩阵a,平均切割为num份 np.vsplit(a,num):略。 num也可以是元组,是元组的话就是指定切割位置。
25. matrix.argmax(axis=指定维度):axis=0时返回每列最大值对应索引号;axis=1略。
26. np.tile(待扩展的ndarray, 扩展维度):扩展向量或矩阵的,直接上图
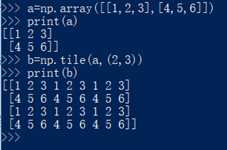
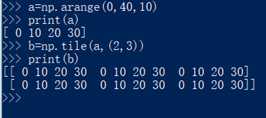
27. np.sort(ndarray,axis):对指定维度进行排序,直接上图
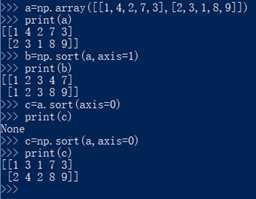
28. np.argsort(vector):把vector中的元素从小到大顺序提出索引号,直接上图
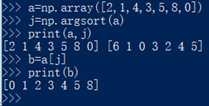
?
五、不同复制操作的对比
29.?=:python中变量可以认为是指针,也就是是说变量名指向的是内存中的一块存储空间,比如说a=5,b=a,那么a和b本身没有什么关系,只是某内存中存储的数据,但是a和b指向的是同一块内存区域,如果说我们改变b的值,那么只是改变了b所指向的内容,因为a和b指向同一内容,所以此时a所指向的内容也跟着变。表现出来就是b变a也变
30. view:若要实现浅赋值,可以使用view方法。c = a.view(),此时a和c指向的内存不同,假设a指向内存A,c指向内存C,若改变C的结构,比如把2*4矩阵改为4*2矩阵,这时A是不变的,但是如果改变C的数值,则A的数值会发生变化,因为内存A和C是共用一组数据的。表现出来就是c结构变,a不变;c数据变,a数据变
31. copy:若希望复制的时候指针指向不一样,数据也不一样,就用copy方法,copy实现的是深复制。 d = a.copy(),假设d指向内存D,D和A无关,D的内容也只是用A的内容做了初始化,此时无论如何改变D,A都不会发生任何变化。表现出来就是d变a不变
?
?
以上是关于机器学习初入门01-numpy的基础用法的主要内容,如果未能解决你的问题,请参考以下文章
机器学习之sklearn基础——一个小案例,sklearn初体验