面向对象阶段总结 | 贰
Posted xiaofulan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面向对象阶段总结 | 贰相关的知识,希望对你有一定的参考价值。
一.设计策略分析
1.第五次作业
事实上,在进行第五次作业设计的时候,我对多线程的概念还处于完全懵懂的状态,既不能区分线程同步和线程互斥,也不能区分对象锁和类锁,甚至不知道临界区是什么意思,只会对方法加锁而不会对代码块加锁。在这种朦胧的状态下完成了一个现在看起来也还不错的设计,并且最终通过了所有公测互测,只是因为我在上课时不小心记住了老师说的一句话:“这次设计主要采用生产者-消费者模式”。我的手中恰好有一本结城浩的《图解Java多线程设计模式》,上面对各种设计模式的讲解比较通俗易懂,因此我在设计里大量采用了生产者-消费者模式(一共6对生产者-消费者):
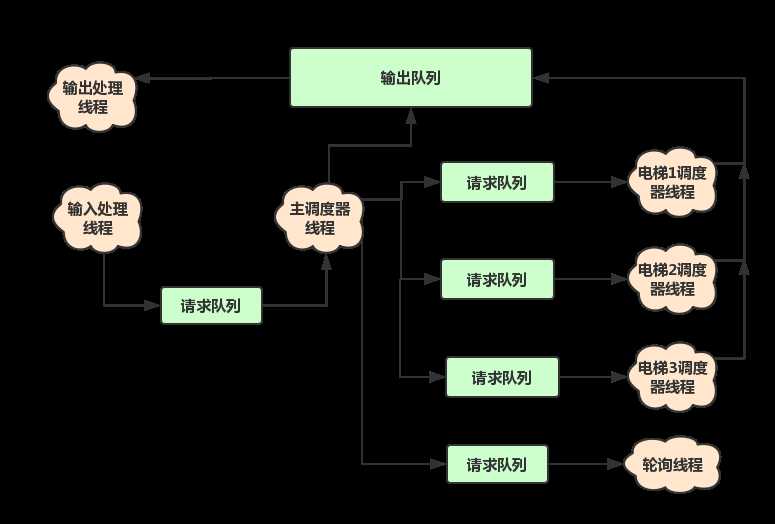
虽然以现在的角度分析,这种设计存在很多冗余,例如输出根本不需要作为一个消费者角色的线程类,事实上只需要一个加类锁的静态方法就够了。但是这种设计着实管用,也顺利帮我度过了传说中最困难的一次作业。
2.第六次作业
第六次作业的设计是我最不满意的一次设计,虽然吸取了上一次作业的教训,在作业之前抓紧时间补充了一下线程安全方面的知识,但是还是显得捉襟见肘。首先遇到的最大的难题就是,如何保证文件操作是线程安全的,这在我最初看来是几乎不可能实现的,因为文件操作针对的是一个文件,而对象锁锁住的是一个对象,一个文件可以同时对应多个文件对象,而他们之间是无法实现互斥的。在与同学讨论之后,我们最终采用了一种非常巧妙的办法,使得这一问题得以解决,我将在心得体会章节专门进行记录。此外,由于我采用的是一条请求对应一个线程的设计,线程之间互不沟通,并且代码的重用性很差,几个触发器的代码存在复制粘贴的现象,导致出现了许多问题。再加上时间仓促,我直到周三的中午,还匆匆忙忙地对代码进行了部分修改,最终在互测中被找到了1个bug。
3.第七次作业
第七次作业的设计,就看到了自己的明显提高。根据需要采用了一些设计模式,例如生产者-消费者模式、Thread-per-message模式、Two-Phase Termination模式,但是没有过分依赖。同时有了前两次的经验,能够很得心应手地完成线程安全类的构建(主要是文件操作类使用了类锁,对出租车状态的改变添加了对象锁,同时请求队列采用了阻塞队列)。同时,能够比较精确识别临界区,对代码块加锁,而不是简单粗暴地直接对整个方法进行加锁。
二.代码度量分析
1.第五次作业(电梯控制系统)
(1)代码度量及相应分析
| 度量值 | 总计 | 均值 |
|---|---|---|
| 代码行数 | 911 | 8.93 |
| 嵌套块深度 | 0.63 | |
| 圈复杂度 | 1.75 | |
| 方法个数 | 102 | |
| 类个数 | 20 |
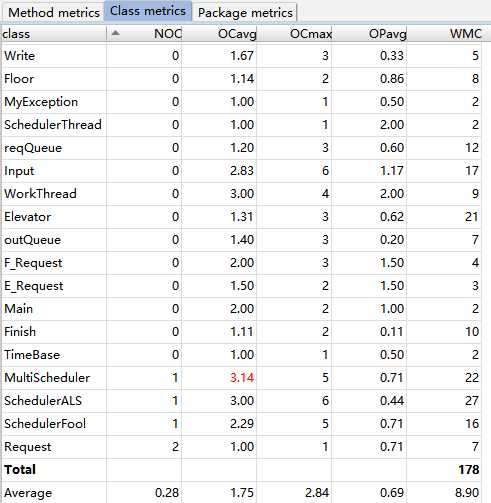
可以发现,与前三次作业相比,无论是程序的圈复杂度还是程序的嵌套块深度都有显著下降。这是因为第一次博客作业之后,我有意识地对功能进行了拆分,尽量遵循SRP原则。类的个数上升了,每个类的复杂度也相应下降了。这次作业被标红的是MultiScheduler类,显示其圈复杂度过高,这可能是由于该类的大部分代码都是沿用自前几次作业的电梯调度系统,因此仍存在一些历史遗留的复杂度过高的问题。
(2)类图(单击查看大图)

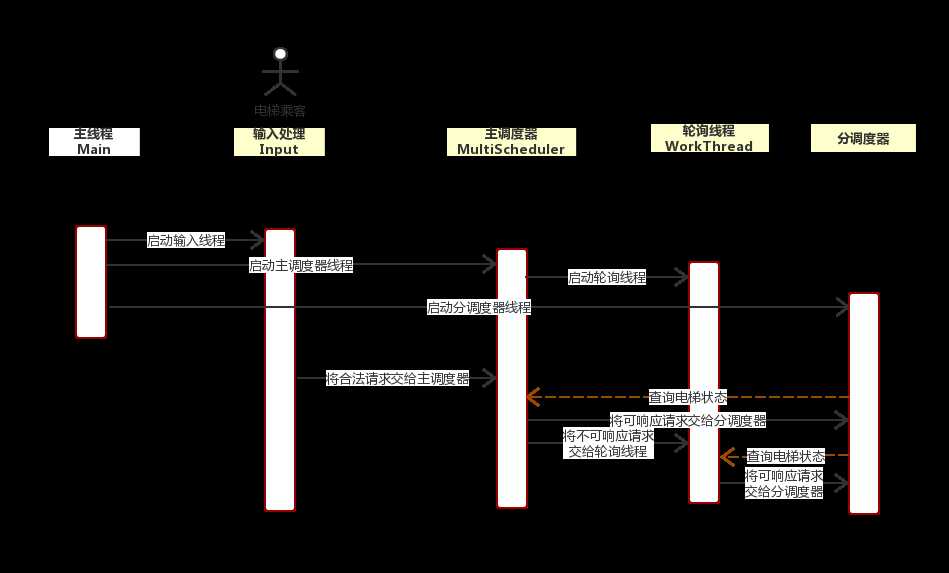
(3)UML时序图
(4)设计原则
听完老师在总结课上的分析之后,我发现此次作业我的一个问题是电梯类和主调度器类之间存在数据结构耦合,为了让主调度器实时获取电梯的状态,我选择了直接将电梯对象以参数形式传递给了主调度器。事实上更好的做法是将电梯状态作为共享对象,以状态板的形式对外发布供调度器读取。
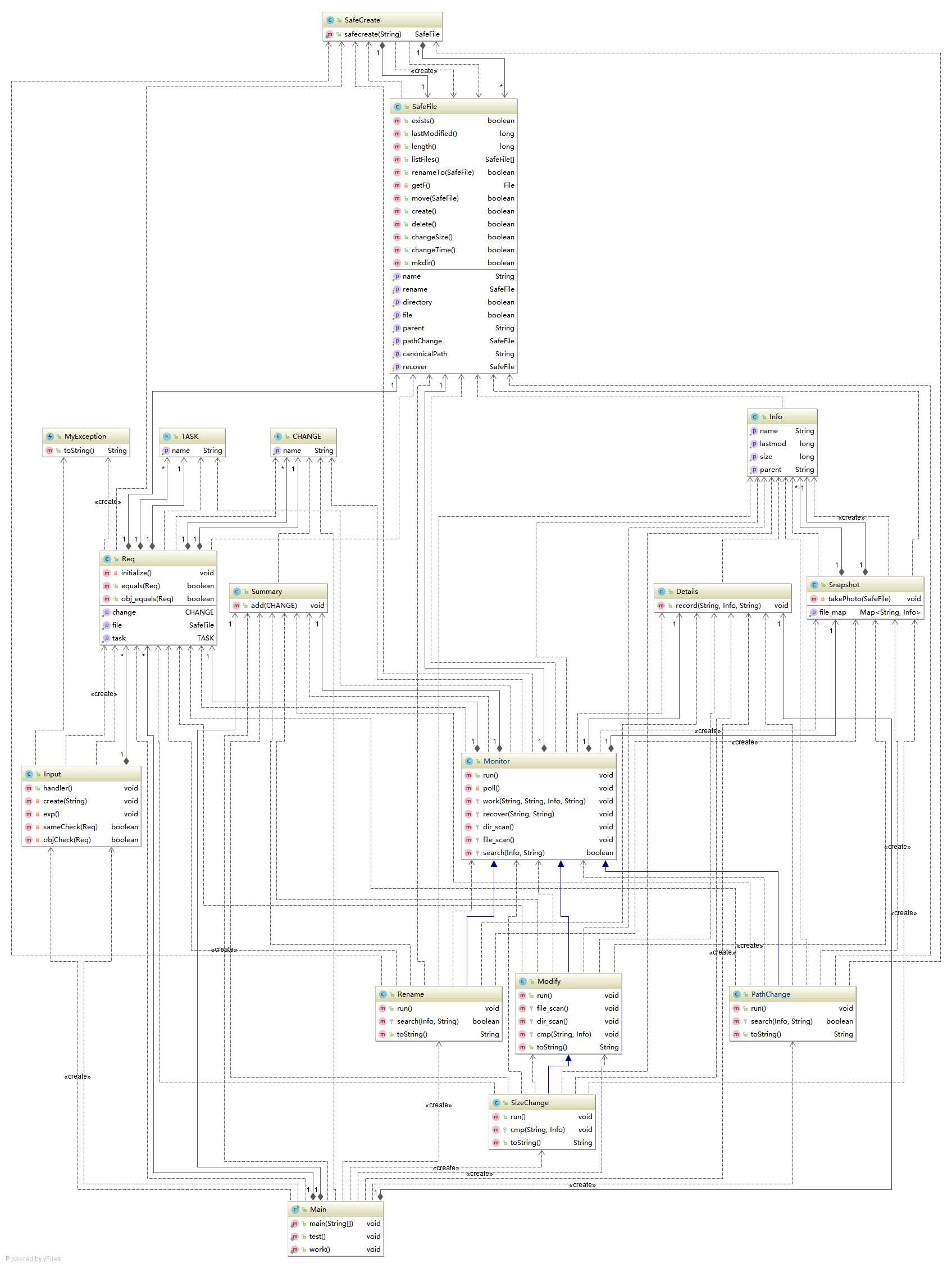
2.第六次作业(文件监控系统)
(1)代码度量及相应分析
| 度量值 | 总计 | 均值 |
|---|---|---|
| 代码行数 | 775 | 8.16 |
| 嵌套块深度 | 0.74 | |
| 圈复杂度 | 1.76 | |
| 方法个数 | 95 | |
| 类个数 | 18 |
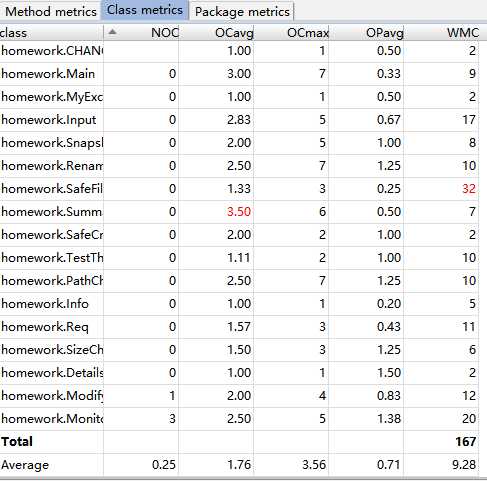
这次作业被标红的是Summary类,这是用于record-summary触发器进行文件输出的类,其圈复杂度偏高的原因可能是我在其中使用了switch语句:
switch (change){
case RENAMD:
renamed++;
System.out.println(change.getName()+"\\t"+renamed);
writer.write(change.getName()+"\\t"+renamed);
break;
case MODIFIED:
modified++;
System.out.println(change.getName()+"\\t"+modified);
writer.write(change.getName()+"\\t"+modified);
break;
case PATH_C:
path++;
System.out.println(change.getName()+"\\t"+path);
writer.write(change.getName()+"\\t"+path);
break;
case SIZE_C:
size++;
System.out.println(change.getName()+"\\t"+size);
writer.write(change.getName()+"\\t"+size);
break;
default:break;
}
writer.write("\\r\\n");
writer.flush();事实上,这是一个经常在编写代码时困扰我的问题。我清楚switch语句是不被推荐的,但是在某些情况下,我仍旧无法找出更好的替代写法,如果大家有更好的建议,欢迎在评论区交流。
(2)类图(单击查看大图)
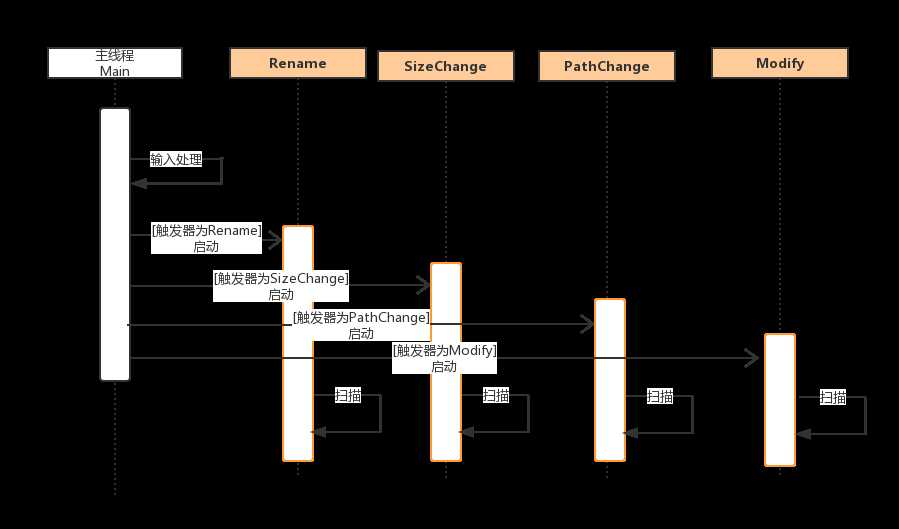
(3)UML时序图
(4)设计原则
这次作业比较重大的缺陷是对继承关系的处理上,我的本意是将重复的代码提取出来,遵循重用原则,但是设计不当且时间匆忙未进行细致修改,我代码的继承关系最终如下:
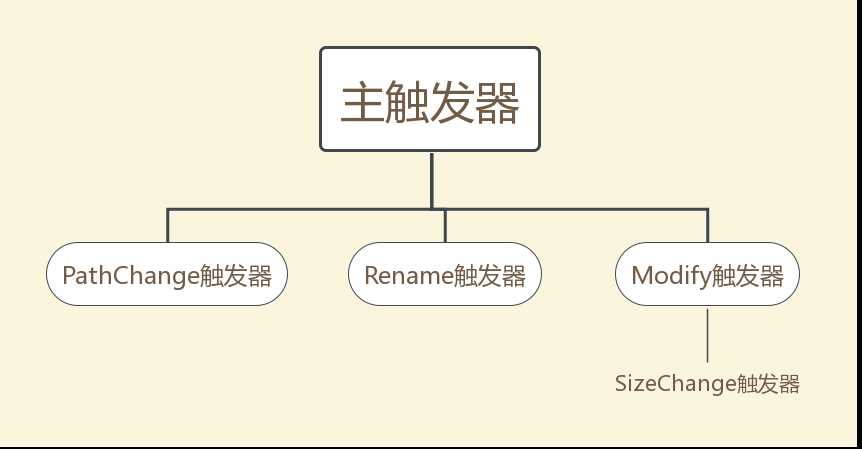
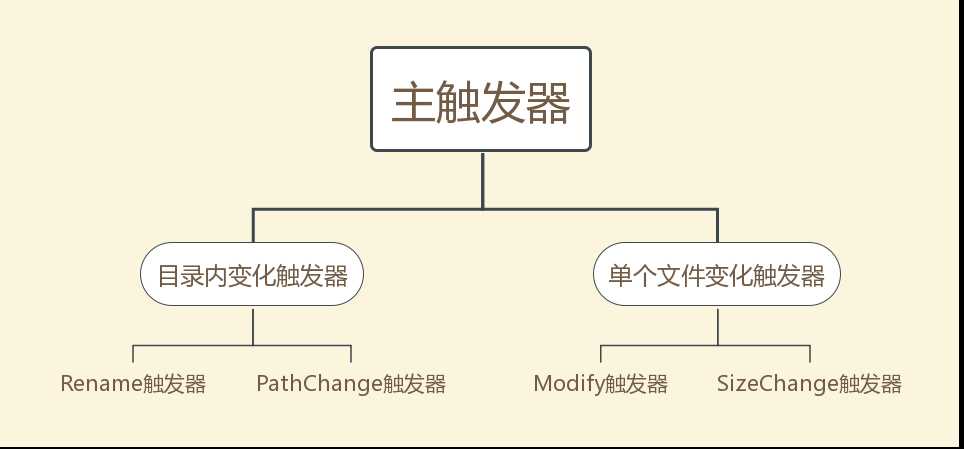
显然SizeChange触发器不应该继承Modify触发器,同时PathChange触发器与Rename触发器之间仍旧有许多相同的代码,导致每次修改都需要对两个类分别进行改动,容易出错。这个设计违背了OCP原则。事实上如果整体架构不变,单对这一问题进行改动的话,设计成如下继承关系可能更好:
3.第七次作业(出租车调度系统)
以下代码度量均忽略了GUI部分的代码。
(1)代码度量及相应分析
| 度量值 | 总计 | 均值 |
|---|---|---|
| 代码行数 | 877 | 9.97 |
| 嵌套块深度 | 0.70 | |
| 圈复杂度 | 2.08 | |
| 方法个数 | 89 | |
| 类个数 | 19 |
可以看到此次作业的圈复杂度有所上升,圈复杂度比较高的类主要有三个:
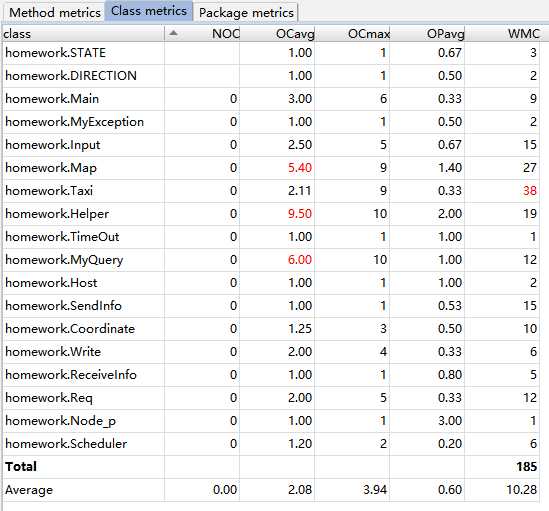
其中Map中涉及到了最短路径的计算,MyQuery是提供给测试者查询出租车状态的接口,而Helper则是主要负责请求调度的类。Helper中的代码复杂度的确有些高,我试着为我测试的代码进行了度量,发现他的主调度器圈复杂度只有3.67,因此我的代码还有优化和改进的空间。
(2)类图(单击查看大图)
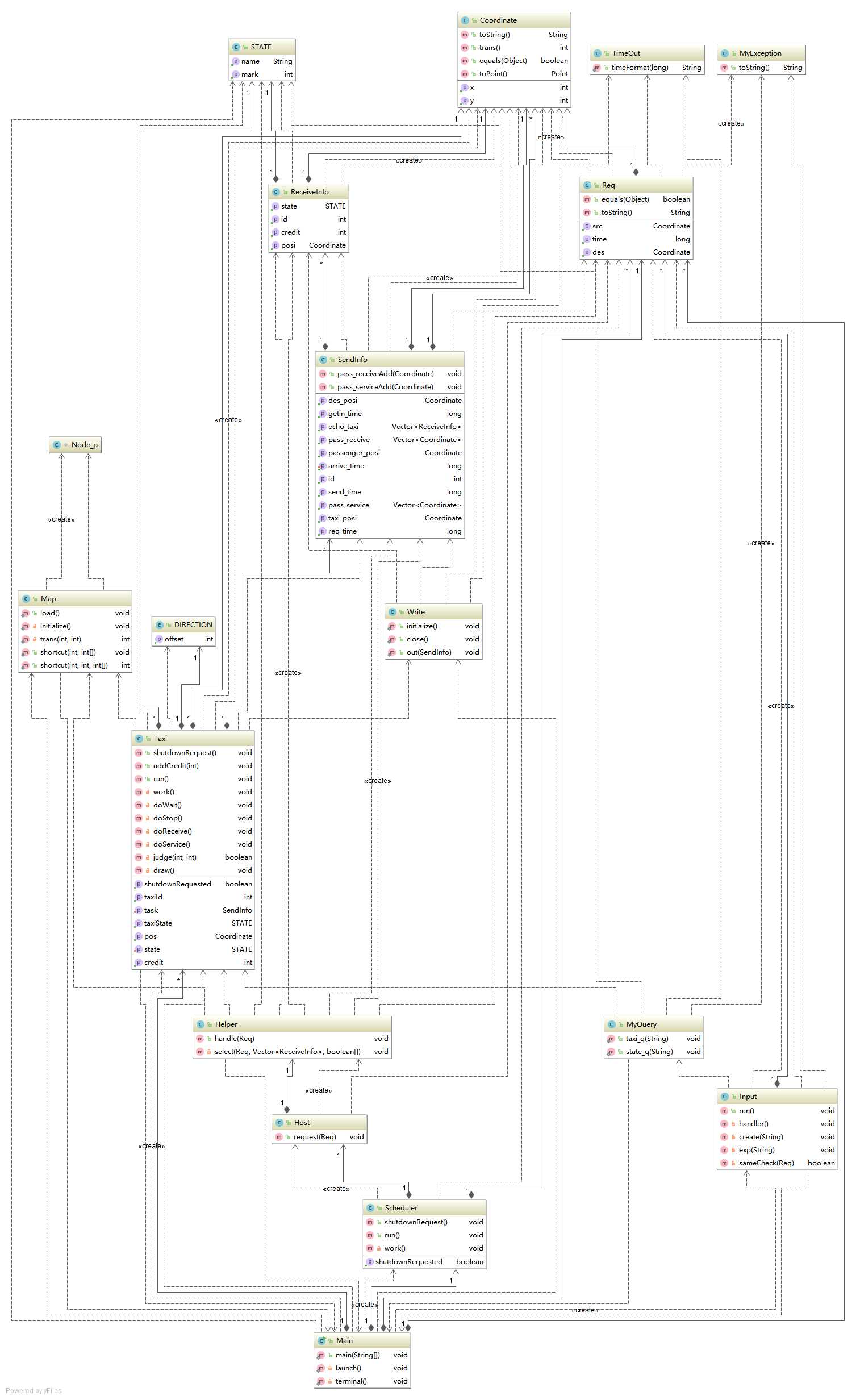
(3)UML时序图
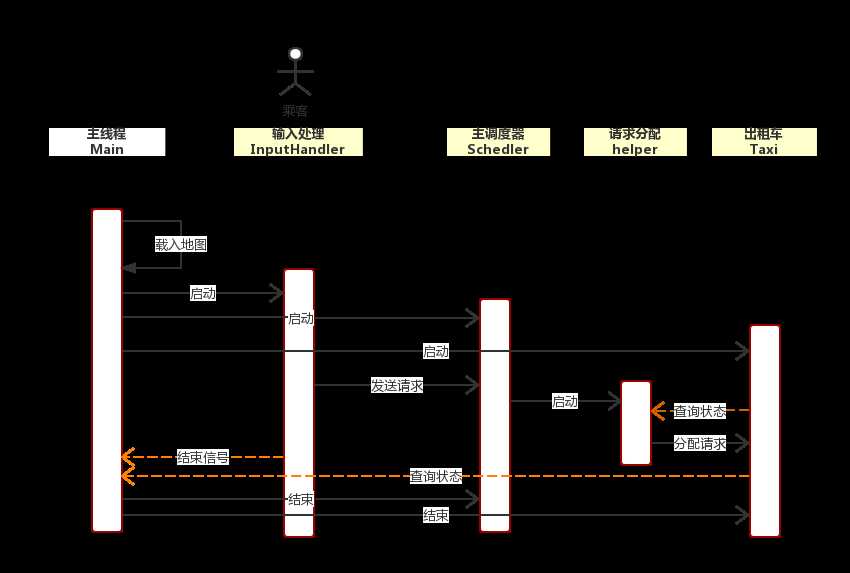
(4)设计原则
同一个量size=80以及time=200在代码的许多处反复出现,违背了局部化原则,可以新建一个静态类单独存储常用的常量。
三.分析自己的bug
第五次和第七次作业未被发现功能性bug,第六次作业在互测中测试者发现了我的一个bug,经过讨论确实是我的程序的一个缺陷。第七次作业测试者发现了我的一个在设计原则上的缺陷。
第六次作业被发现的bug,具体原因是:我有两个位置涉及到快照的拍摄,一处在线程的构造函数内(即一启动线程就拍摄一张最初的快照),另一处在每次扫描时都拍摄一张,我在周三中午为了解决一些问题,临时对拍摄快照的对象做了一些改动,但是因为比较慌张,我只修改了扫描中的一处,而忘记修改构造函数。这直接导致我的程序在特定情况下无法识别新旧文件,事实上这对renamed和size-changed触发器都有影响,但是测试者把它算作了一个bug,在此表示感谢。其实第六次作业出现这样的问题并不意外,我在完成作业的过程中,就感到了时间的紧张,设计和编码工作都进行的比较仓促。不太完善的设计,对编写的程序都不够熟悉,都导致在改正一个bug的同时,很有可能导致新的bug的产生,这是以后应该吸取的教训。
第七次作业被发现的设计原则缺陷是,我在代码里80(地图尺寸)这个量出现了很多次,测试者认为我违反了局部化原则,并且建议我将80设为一个主类里的静态变量为所有类所公用。的确,如果地图尺寸发生了改变,按照我现在的写法进行修改的话是一件非常费力且容易出错的事情。
四.测试策略
引入多线程编程以后,测试难度明显变高,存在许多随机的成分,有些bug也难以复现。我在第一次博客中提出的用大量随机样例逼近完备性的方法似乎不太好用了。因此这几次测试,我主要依靠的是自己设计和编码时的笔记,每次遇到容易出错的地方,我会进行记录,作为互测时重点查看的地方。测试的顺序大概为:
基础功能测试 ——> 边界情况测试 ——> 阅读代码,寻找缺陷,构造样例
关于边界情况测试,可以刻意构造一些比较特殊的情况,来测试程序的反应能力。例如对于文件监控系统,同一个目录下存在除文件名外完全相同的几个文件,就是一种边界情况。而对于出租调度系统,通过一组请求将许多出租车调度到同一个位置,再在这个位置发出大量的请求,就是一种边界情况。
如果准备好的样例无法找出被测者的bug,那么阅读代码就变成了一件很有必要的事情。这个过程类似于假说演绎法,通过阅读、推理、猜测、证实,从而找到bug。例如我在第七次作业,就通过阅读代码猜想被测者可能会出现时间误差的问题,经过构造样例测试以后,果然发现了对应的问题。
五.心得体会
1.设计模式是一把锤子
如我在设计策略中所述,在这几次作业中,设计模式给我提供了许多帮助。当然设计模式只是一个工具,虽然好用,但是并不是任何场景都可以直接套用的,只有将设计模式内化在自己的心中,根据需要在适当的时候使用,才能事半功倍。就像武侠小说中说的,“无招胜有招”。
总结起来,我在几次作业中采用的设计模式有:
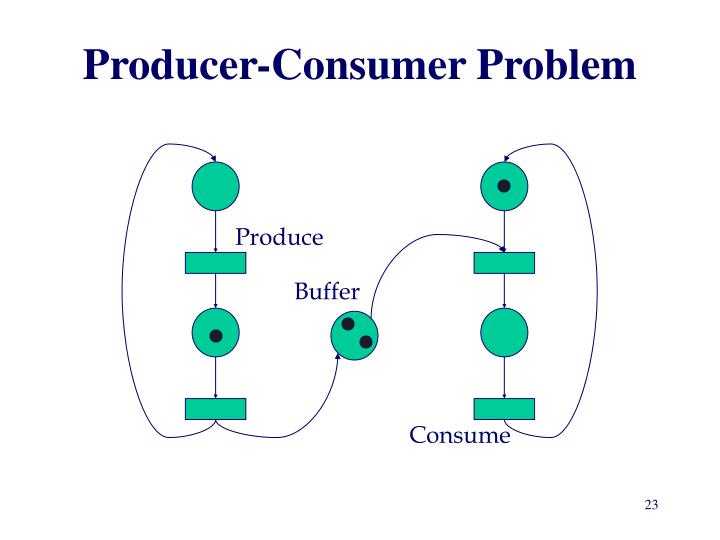
- Producer-Consumer模式
这个模式是我使用得最多的模式,除了在第五次作业夸张地采用了六组Producer-Consumer模式以外,第七次作业的输入-请求队列-调度器也采用了相同的模式。当然我在使用中也进行了一些改进,在第五次作业中完全采用的是类似管程的方法,自己构建了一个托盘类,其中使用wait()和notify()实现同步。在第七次作业中,我使用了阻塞队列,从而使得代码变得更加清爽。
- Thread-Per-Message模式
这种模式的意思是每个消息一个线程。在出租车调度系统中,我采用了该模式,调度器只是一个委托端,而真正处理请求的是由调度器启动的执行短线程。采用这一模式的本意是提高调度器的响应性,缩短响应时间,但是矛盾在于启动线程和上下文切换本身就会耗费CPU时间,从而出现了一个平衡问题。在第七次作业中,采用这种模式处理同时输入的300条请求并无任何问题,但是究竟线程数是多少是最优的、能否存在一种介于1个线程和300个线程之间的平衡的方法、在接下来的几次作业中,是否应该继续沿用这种模式,还是有待思考和讨论的问题。
- Work Thread模式
在第五次作业中,我遇到了一个问题:有些楼层请求在被调度器获取时并没有立刻可以响应它的电梯,需要不断进行等待和查询,但是如果占用调度器线程进行轮询的话,又不能及时响应其他后来的可以被响应的请求。起先我想到的方法是采用Thread-Per-Message模式,每遇到一个需要轮询的请求后,就开启一个轮询线程专门负责该请求。但是在测试中我发现了问题,由于轮询线程之间并不存在时序关系,因此在有多条请求同时轮询的情况下,很容易发生后来的请求抢占了本该分给先来请求的电梯。经过反复思考,我采用了Work Thread模式,"雇佣"一个工人线程专门负责轮询,每次遇到无法马上响应的请求,都交给轮询线程处理,从而提高调度器的吞吐量。
- Two-Phase Termination模式
这一模式解决的是如何让线程优雅地结束的问题,通过设计一个结束标志(闩),由线程频繁检查该标志来控制线程终止,而非简单粗暴的采用stop()方法,可以避免有些线程还未处理完已有的任务就被终止。第六次作业一个让我不太满意的地方就是程序并不是总能优雅的终止,有些时候必须依靠测试者进行强制结束。因此在第七次作业中,我采用这一模式,进行了一系列设计,可以保证在控制台输入结束命令之后,所有的线程都有序地渐次结束(虽然后来我发现其实直接把GUI关闭以后程序就可以结束了……)。


2.怎样对一个文件加锁
在第六次作业中,我遇到的一个难以解决的问题是:如何实现线程安全的SafeFile类。因为对象锁只对同一个文件对象才有用,而实际的情况是,对同一个文件,可能每一次操作都会新建一个文件对象,这些文件对象指向的是同一个文件,但是却完全无法对他们加锁。
后来采用的解决方案是,构建一个HashMap,以标准文件路径为键,以文件对象为键值,每次针对一个文件新建对象时,先在HashMap的键中中查询文件路径是否已经存在,如果存在则直接返回对应的对象,如果不存在再新建对象并且将对应的路径和对象存入HashMap。文件路径和文件是一一映射的,通过这个HashMap的构建,成功地实现了一个文件只对应一个文件对象,方便对文件操作加锁,同时也可以为文件对象增加了一些标记而不必担心文件对应多个文件对象的问题。
以上是关于面向对象阶段总结 | 贰的主要内容,如果未能解决你的问题,请参考以下文章