Pandas 基础 - 读/写 Excel 和 CSV 文件
Posted rachelross
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas 基础 - 读/写 Excel 和 CSV 文件相关的知识,希望对你有一定的参考价值。
这一节将分别介绍读/写 Excel 和 CSV 文件的各种方式:
- 读入 CSV 文件
首先是准备一个 csv 文件, 这里我用的是 stock_data.csv, 文件我已上传, 大家可以直接下载下来使用. 正如前面讲过的, csv 文件可以放在 jupyter notebook 同目录下, 这样直接写文件名就可以了, 但是如果没有放在同目录下, 就需要写绝对路径, 否则读取不到.
import pandas as pd
df = pd.read_csv(‘/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv‘)
df
输入输出的效果, 截图如下: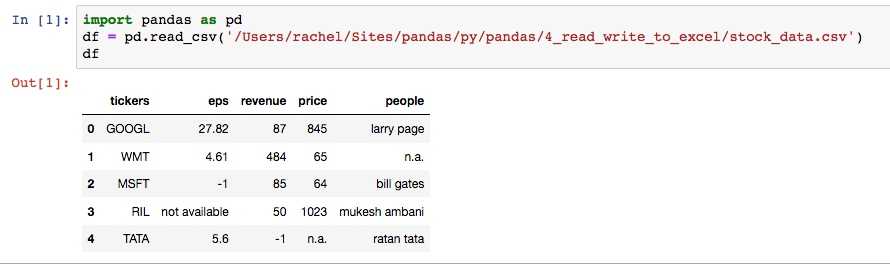
上面就是引入 csv 文件最基本最常规的情况, 下面介绍一些特殊情况:
- 当原 csv 文件有个文件头(如下图):
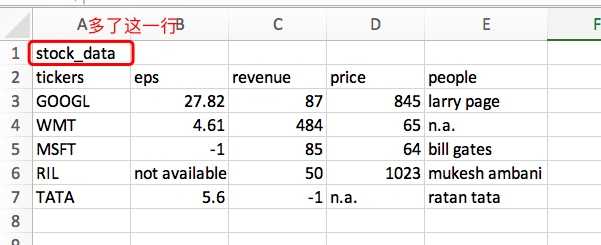
大家可以自行修改一下 csv 文件, 然后在 jupyter 里运行一下看看得到什么结果, 这里就不截图了, 总之, 显然我们并不想要那多出来的一行, 可以这样做:
df = pd.read_csv(‘/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv‘, header = 1)
这里设置了第二个参数 header=1, 意思就是我们要引入的从第一行开始以下的内容(把文件看作是从第0行开始的)
另外, 还可以这么写:
df = pd.read_csv(‘/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv‘, skiprows=1)
也就是把第二个参数改为 skiprows=1, 意思就是要忽略的行数.
两种方式都能得到相同的结果.
- 如果 csv 文件本身没有表头, 也就是所有的列名都不存在, 但是我们在引入的时候, 我们了解每一列都是什么值, 也就是说我们要如何在引入文件的时候自定义列名:
df = pd.read_csv(‘/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv‘, names=[‘stickers‘, ‘eps‘, ‘revenue‘, ‘price‘, ‘people‘])
- 读取指定的几行数据
现在我们把 csv 文件再还原到初始状态, 看下,如果我们只想读取其中的3条数据, 只要加上参数 nrows=3 即可:
df = pd.read_csv(‘/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv‘, nrows=3)
- 整理数据, 统一空值和不合理的值
现在来具体看下表格中的数据, 会发现有些数据是没有的, 从 csv 文件中导入过来的数据看起来也有点乱, 有的写的是 ‘n.a.‘, 有的又是 ‘not available‘, 对于这些空数据, 在 Pandas 中可以统一为 ‘NaN‘.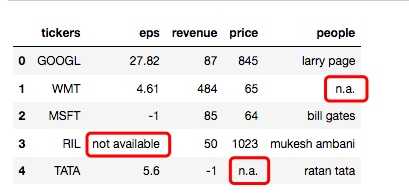
df = pd.read_csv(‘/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv‘, na_values=[‘not available‘, ‘n.a.‘])
这里第二个参数的意思就是, 在读取文件的时候, 凡是遇到 ‘not available‘, ‘n.a.‘ 都统一设为空值 ‘NaN‘.
除了空值以外, 还有可能遇到不合理的值, 比如在 ‘revenue‘(收入)列的最后一行, 值是 ‘-1‘, 这显然是不合常理的, 有可能是笔误或者什么, 总之, 我们并不知道这个值是什么, 所以也应该处理为空值‘NaN‘. 那么, 我们能直接在第二个参数的中括号里直接再加上 ‘-1‘ 吗? 理论上是可以实现效果的, 但是我们发现在 ‘eps‘ 列也有一个 ‘-1‘的值, 而这个值是合理的, 因此如果我们简单粗暴地把 ‘-1‘设为‘NaN‘, 就会影响到这个值, 所以, 我们需要这样做:
df = pd.read_csv(‘/Users/rachel/Sites/pandas/py/pandas/4_read_write_to_excel/stock_data.csv‘, na_values={
‘eps‘:[‘not available‘, ‘n.a.‘],
‘revenue‘: [‘not available‘, ‘n.a.‘, -1],
‘price‘: [‘not available‘, ‘n.a.‘],
‘people‘: [‘not available‘, ‘n.a.‘]
})
这里就是通过 dictionary 的数据形式, 具体明确每一列处理空值的方式.
以上就是读取 CSV 文件的方法和常见问题, 下面看下如何输出 CSV 文件.
- 输出 CSV 文件
只需要简单执行下面这行命令, 就可以生成一个 new.csv 文件, 至于这个文件生成在哪里, 还是去终端看下, 你此时的 jupyter notebook 运行在哪里:
df.to_csv(‘new.csv‘)
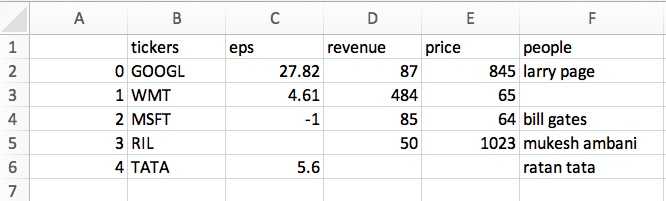
空值部分全部为空白. 但是多了一列序号索引, 如果想去掉:
df.to_csv(‘new.csv‘, index=False)
- 输出指定的列
如果你只想要把前两列的内容保存成 csv 文件输出.
首先查看一下所有的列名:
df.columns
输出:
Index([‘tickers‘, ‘eps‘, ‘revenue‘, ‘price‘, ‘people‘], dtype=‘object‘)
只输出 ‘tickers‘ 和 ‘eps‘ 列:
df.to_csv(‘new.csv‘, columns=[‘tickers‘, ‘eps‘])
这时再查看一下 new.csv 文件, 发现里面真的只有两列.
- 不输出表头, 即列名
设置第二个参数 header = False 即可:
df.to_csv(‘new.csv‘, header = False)
- 读取 EXCEL 文件
首先是准备一个 excel 文件, 这里我用的是 stock_data.csv, 文件我已上传, 大家可以直接下载下来使用.
import pandas as pd
df = pd.read_excel(‘stock_data.xlsx‘, ‘Sheet1‘)
df
输出: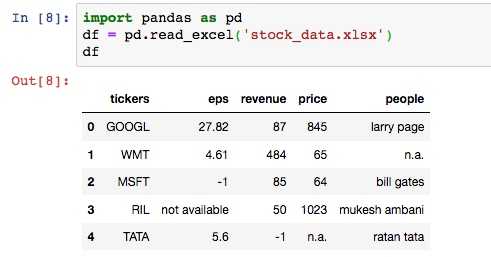
- 整理数据
从上图, 我们可以看到有一些 n.a. 和 not available 的数据, 我们可以做更有针对性的调整:
def convert_people_cell(cell):
if cell == ‘n.a.‘:
return ‘Sam Walton‘
return cell
def convert_eps_cell(cell):
if cell == ‘not available‘:
return None
return cell
df = pd.read_excel(‘stock_data.xlsx‘, ‘Sheet1‘, converters={
‘people‘: convert_people_cell
})
- 保存成 excel 文件输出
- 自定义输出
df.to_excel(‘new.xlsx‘, sheet_name=‘stocks‘, index=False, startrow=1, startcol=2)
参数说明:
sheet_name=‘stocks‘: 设置 sheet 名称
index=False: 去掉序号索引
startrow=1: 从第二行开始表格
startcol=2: 从第三列开始表格
输出:
- 把两个 dataframe 输出到一个 excel 表的两个 sheet
df_stocks = pd.DataFrame({
‘tickers‘: [‘GOOGL‘, ‘WMT‘, ‘MSFT‘],
‘price‘: [845, 65, 64 ],
‘pe‘: [30.37, 14.26, 30.97],
‘eps‘: [27.82, 4.61, 2.12]
})
df_weather = pd.DataFrame({
‘day‘: [‘1/1/2017‘,‘1/2/2017‘,‘1/3/2017‘],
‘temperature‘: [32,35,28],
‘event‘: [‘Rain‘, ‘Sunny‘, ‘Snow‘]
})
with pd.ExcelWriter(‘stocks_weather.xlsx‘) as writer:
df_stocks.to_excel(writer, sheet_name="stocks")
df_weather.to_excel(writer, sheet_name="weather")
更多关于 Pandas 读取/输出文件的属性, 可以参考官网:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
以上是关于Pandas 基础 - 读/写 Excel 和 CSV 文件的主要内容,如果未能解决你的问题,请参考以下文章
为啥用python的pandas读excel文件时会少掉一行数据