场内的代码表, 感觉水很深
Posted duan-qs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了场内的代码表, 感觉水很深相关的知识,希望对你有一定的参考价值。
场内的代码表, 感觉水很深
写了一个爬取代码表的小爬虫, 很久以前的事了.
现在想好好分析一下, 代码的分类, 又写了一个统计函数. 分别统计
7个不同字头的代码里, 分别有多少只品种.
先上菜:
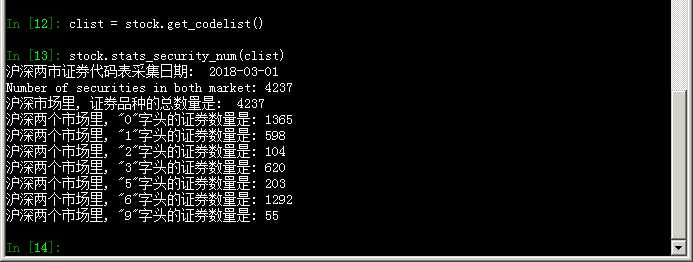
代码运行结果(cmd窗口里启动Ipython的场景):
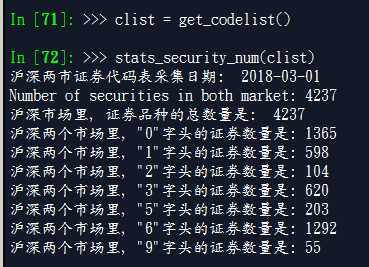
spyder的Ipython窗口里的场景: 想看看他们之间在博客里的展现有何不同:
备注: 这次spyder的字体改成了: DFKai_SB
因为新宋体确实没法用: 该字体在代码窗口里的花括号太难看了, 以至于无法与方括号无异
所以不得不放弃新宋体.
然后再现上厨艺
def get_codelist():
cn_dict = p_load(‘d:/db/amipy/data/codename_dict.pkl‘)
lst = [c for c in cn_dict.keys()]
lst.sort()
return lst
def get_xzt_security_num(codelist,xzt=‘1‘):
u‘‘‘
检索代码列表, 得到‘1‘字头的品种的数量
>>> codelist = get_codelist()
>>> get_xzt_security_num(codelist, ‘0‘)
‘‘‘
count = 0
for c in codelist:
if c.startswith(xzt):
count +=1
return count
def stats_security_num(codelist, dt=‘2018-03-01‘):
u‘‘‘
分别统计某个字头的代码的品种个数
Examples:
>>> clist = get_codelist()
>>> stats_security_num(clist)
‘‘‘
print(‘沪深两市证券代码表采集日期: ‘, dt)
print(‘Number of securities in both market: {}‘.format(len(codelist)))
# 4237
prefix = [‘0‘, ‘1‘, ‘2‘, ‘3‘, ‘5‘, ‘6‘, ‘9‘,]
nums=[]
total=0
for pre in prefix:
num=get_xzt_security_num(codelist, pre)
nums.append(num)
total += num
print("沪深市场里, 证券品种的总数量是: ", total)
for i in range(len(nums)):
print(‘沪深两个市场里, "{}"字头的证券数量是: {} ‘.format(prefix[i], nums[i]))
然后再顺便说一下: cmd窗口里如何如何启动Ipython环境:

以上是关于场内的代码表, 感觉水很深的主要内容,如果未能解决你的问题,请参考以下文章