HBase
Posted code2one
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase相关的知识,希望对你有一定的参考价值。
目录
HBase
本文实际上是《HBase不睡觉书》的重点归纳。该书不涉及:集群备份、ACL权限控制、REST客户端等。而对于一些不算常用的技术,书中也提示可略过(“集群搭建”除外),本文便以“略”表示。
基础
NoSQL
关系型数据库在大数据情况下受到并发和关联等复杂查询的影响而导致性能下降。
非关系型数据库放弃线性一致性,仅满足最终一致性。
线性一致性:让一个系统看起来好像只有一个数据副本,而且所有的操作都是原子性的。
HBase采用KV存储,意味着随着数据量增大,查询性能也不会下降多少。同时HBase作为列式存储,可以把字段分开存储,从而分散负载。但是这样复杂的存储结构和分布式导致HBase很慢,只是在大数据环境下慢得不明显。
HBase除了不适用于小数据,如单表不超过千万,还不适用于数据分析,如做报表。只有当单表超千万,且并发高,或者数据分析相当简单且非实时。
架构
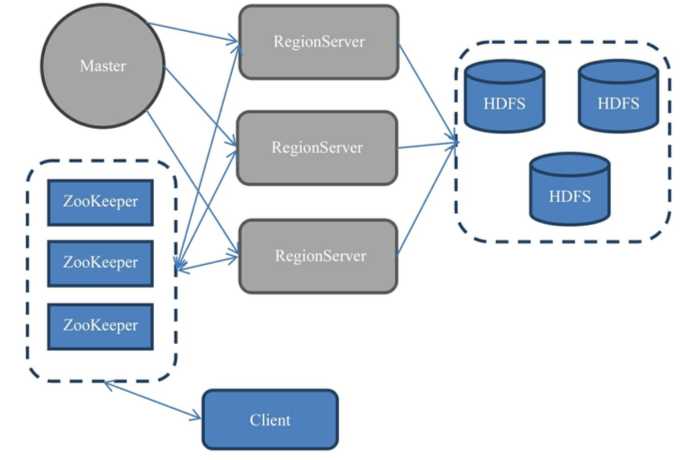
宏观架构
Master(维护表结构信息)和RegionServer服务器(存储数据,HDFS上)。客户端直接通过RS获取数据,所以Master挂点不影响查询,但不能再新建表了。
ZK管理所有RS的信息,包括具体的数据段存放在哪个RS。HBase还自带了ZK,进程名为HQuirumPeer(多了H),在生产环境下要修改设置,防止其自带的ZK启动。
微观架构
Region是一段数据(多个行)的集合,HBase的表一般拥有一个到多个Region。(相当于关系型数据库中的分区)
- Region不能跨服务器,一个RS上有一个或多个Region
- 一个Region足以存储小数据
- 当HBase在进行负载均衡时,可能会从一台RS上把Region移动到另一台RS上。
- Region是基于HDFS的,它所有数据存取都是调用HDFS的客户端接口实现的。
RegionServer
存放Region的容器,直观上是服务器上的一个服务。通常一个服务器只会安装一个RS。客户端通过ZK获取RS地址后,直接从RS获取数据。
Master
负责启动的时候分配Region到具体的RegionServer, 执行各种管理操作, 比如Region的分割和合并、建表、删表、移动Region、修改列族配置等跨RS操作。一般的查询、存储、删除数据都不需要。
存储架构
列:是基本单位,一列或者多列组成一行。各行的列数可以不等,不同行数据或者同一行数据可以存储在不同的机器上。
每行都有唯一的航键来标定一个行的唯一性。每个列都有多个版本,多个版本的值存储在单元格中。
若干个列可以被归为列族。
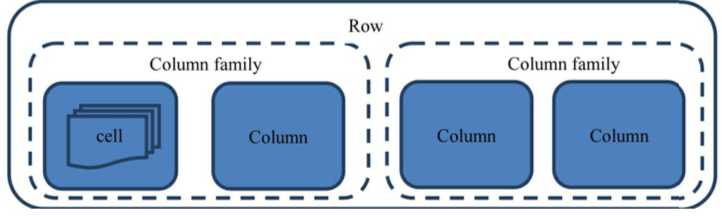
rowkey:Hbase中只能根据rowkey来排序,无法根据某个col来排序。规则为字典序,例如row11在row2前面。如果向HBase插入相同的rowkey,那会更新rowkey值,旧值需要带上版本参数才能找到。一个列上可以有多个版本的单元格,它是存储的最小单位。
列族:需要一开始就设置好(列的修改就灵活很多),包括过期时间、数据块缓存以及是否压缩等,所以一个列如果不存在与列族将失去这些属性而失去意义,也因此在命名上,列名前面始终有列族名。列族的存在让同列族的列尽量存储在一台机器上。列族在满足需求的前提下尽量少,这样能减少性能的损失,也少一点BUG。
单元格:确定一条数据的表达为rowkey:column family:column:version(optional)
HBase的写入必须一行一行来。
集群搭建(略)
《HBase不睡觉书》中Hadoop、Zookeeper和HBase的集群环境搭建是我见到过的最易懂且完整的教程了,连集群的开机启动脚本都逐步介绍了。
HA模式下不能用
namenode主机:端口来访问Hadoop集群,因为端口ip已经不是固定的了,需要采用serviceid访问,它存储在ZK中。
Shell基本操作
常用操作
put ‘mytable‘, ‘row1‘, ‘mycf:name‘, ‘apple‘# 启动(练习模式)
zkServer.sh start
start-dfs.sh
start-hbase.sh
hbase shell
create ‘table_name‘, ‘col_family‘
alter ‘table_name‘, ‘col_family‘ # 新建列族 (先disable这个表,因为会影响所有拥有这个表的RS)
list # 查看有哪些表
describe ‘table_name‘ # 看表信息
scan ‘table‘,{STAETORW=>‘row3‘,ENDROW=>‘row4‘} # 看表数据,start和end可选,但生产中必须用上。如果在创建table时设置了VERSIONS参数大于1,那么scan也是可以看到历史版本记录的。
get ‘table_name‘, ‘row_key‘, ‘col_family:col_name‘ # 数据量大时比scan快不少
get ‘table_name‘, ‘row_key‘, {COLUMN=>‘col_family:col_name‘,VERSIONS=>5}
put ‘table_name‘, ‘row_key‘, ‘col_family:col_name‘, ‘value‘,timestamp(optional) # 新增,默认version为1
alter ‘table_name‘,{col_name=>‘col_name2‘,VERSIONS=>timestamp} # 修改数据,这里timestamp可以是任意数字
delete ‘table_name‘,‘row_key‘,‘col_family:col_name‘,ts # 注意,这是删除ts版本之前的所有版本。delete只是做标记,查询一般无法查到被标记的数据,即便重新put,除非用下面语句。HBase会定期清理这些标记的数据。
scan ‘table_name‘, {RAW=>true,VERSION=>5}
deleteall ‘table_name‘,‘row_key‘ # delete必须加上列
disable ‘table_name‘ # 删除表前需要将表下线。执行速度取决于该表当前的负载
drop ‘table_name‘ #删除表没有列定义,某行数据有属性A才有了A列,如果都没有属性A就没有A列。
没有列属性,几乎没有表属性,有列族属性。
其他shell命令(略)
基础客户端API
Table相关
public static void main(String[] args) throws URISyntaxException, IOException {
Configuration conf = HBaseConfiguration.create();
conf.addResource(new Path(
ClassLoader.getSystemResource("hbase-site.xml").toURI()));
conf.addResource(new Path(
ClassLoader.getSystemResource("core-site.xml").toURI()));
// 建立连接
try (Connection conn = ConnectionFactory.createConnection(conf);
// 负责管理建表、 改表、 删表等元数据操作的接口
Admin admin = conn.getAdmin()) {
// 定义表
TableName tn = TableName.valueOf("mytable");
HTableDescriptor table = new HTableDescriptor(tn);
// 定义和添加列族
HColumnDescriptor mycf = new HColumnDescriptor("mycf");
table.addFamily(mycf);
createOrOverwriteTable(admin, table);
// 修改cf属性
mycf.setCompressionType(Compression.Algorithm.GZ);
mycf.setMaxVersions(HConstants.ALL_VERSIONS); // Integer.MAX_VALUE
table.modifyFamily(mycf);
admin.modifyTable(tn, table); // 此时才真正修改
// 往 table 里添加 newcf 列族
HColumnDescriptor newCol = new HColumnDescriptor("newcf");
admin.addColumn(tn, newCol);
// 删除表
admin.disableTable(tn);
admin.deleteColumn(tn, "mycf".getBytes("UTF-8"));
admin.disableTable(tn);
}
}
// 下面只是封装后的函数,可忽略。
private static void deleteSchema(Configuration conf) throws IOException {
try (Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin()) {
TableName tn = TableName.valueOf("mytable");
// 删除表
admin.disableTable(tn);
admin.deleteColumn(tn, "mycf".getBytes("UTF-8"));
admin.disableTable(tn);
}
}
private static void modifySchema(Configuration conf) throws IOException {
try (Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin()) {
TableName tn = TableName.valueOf("mytable");
if (!admin.tableExists(tn)) {
System.out.println("Table does not exist.");
System.exit(-1);
}
// 往 table 里添加 newcf 列族
HColumnDescriptor newCol = new HColumnDescriptor("newcf");
admin.addColumn(tn, newCol);
// 修改cf属性
HTableDescriptor table = admin.getTableDescriptor(tn);
HColumnDescriptor mycf = new HColumnDescriptor("mycf");
mycf.setCompressionType(Compression.Algorithm.GZ);
mycf.setMaxVersions(HConstants.ALL_VERSIONS); // Integer.MAX_VALUE
table.modifyFamily(mycf);
admin.modifyTable(tn, table); // 此时才真正修改
}
}
private static void createSchemaTables(Configuration conf) throws IOException {
try (Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin()) {
HTableDescriptor table = new HTableDescriptor(TableName.valueOf("mytable"));
// 定义和添加列族
table.addFamily(new HColumnDescriptor("mycf")
.setCompressionType(Compression.Algorithm.GZ));
createOrOverwriteTable(admin, table);
}
}
private static void createOrOverwriteTable(Admin admin, HTableDescriptor table) throws IOException {
if (admin.tableExists(table.getTableName())) {
admin.disableTable(table.getTableName());
admin.deleteTable(table.getTableName());
}
admin.createTable(table);
}CRUD相关
包括:put、checkAndPut、has、append、increment、get、exists、delete、checkAndDelete、mutateRow、batch、put(ArrayList)、get(ArrayList)、 delete(ArrayList)、getScanner
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
// conf 相关的同上,故省略
// 建立连接,早期直接通过conf获取table的方法已经被废除
try (Connection conn = ConnectionFactory.createConnection(conf)) {
Table table = conn.getTable(TableName.valueOf("mytable"));
// 在HBase中,所有数据都是bytes
Put put = new Put(Bytes.toBytes("row1"));
put.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("name"),
Bytes.toBytes("value1")) // 早期使用add,已经废除
.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("name"),
Bytes.toBytes("value2"));
// 执行
table.put(put);
// CheckAndPut能防止check之后插入数据之前修改数据,它有两个实现:
// 第一个调用方式是在put操作之前先把指定的value跟即将写入的行
// 中的指定列族和指定列当前的value进行比较, 如果是一致的则进行put操作并返回true。
// 第二个调用方式是第一个调用方式的增强版, 可以传入CompareOp来进行更详细的比较
// checkAndPut最后一个参数put中的rowkey必须跟第一个参数的row一致
Put put2 = new Put(Bytes.toBytes("row2"));
put2.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("name"),
Bytes.toBytes("ted"));
// 将旧值为 jack 的数据修改为 row2 。如果旧值已经被修改,res1 为 false。
// 如果将 row2 改为 null,则判断该数据是否存在,不存在就会 put。
boolean res1 = table.checkAndPut(Bytes.toBytes("row2"), Bytes.toBytes("mycf"),
Bytes.toBytes("name"), Bytes.toBytes("jack"), put2);
// LESS 表示传入的数如果小于当前值就 put
boolean res2 = table.checkAndPut(Bytes.toBytes("row2"), Bytes.toBytes("mycf"),
Bytes.toBytes("name"), CompareFilter.CompareOp.LESS,
Bytes.toBytes("jack"), put2);
// has
boolean has = put2.has(Bytes.toBytes("mycf"), Bytes.toBytes("name"));
// append数据
Append append = new Append(Bytes.toBytes("row2")); // 可以设置 offset 和 len 来切割 "row2"
append.add(Bytes.toBytes("mycf"), Bytes.toBytes("name"),
Bytes.toBytes("Wang"));
table.append(append);
// increment
Increment inc = new Increment(Bytes.toBytes("row3"));
// 要保证 inc.addColumn 中的 col 是 long 型
inc.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("age"), 10L);
table.increment(inc);
// get
Get get = new Get(Bytes.toBytes("row1"));
get.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("name"))
.setTimeRange(0L, 1L)
.setMaxVersions(); // 默认 Integer.MAX_VALUE, 不调用这个函数就为 1
Result res3 = table.get(get);
byte[] name = res3.getValue(Bytes.toBytes("mycf"), Bytes.toBytes("name"));
System.out.println(Bytes.toString(name));
// 上面 res.getValue() 只能获取最新版本数据,如果想获取多个版本的,就需要 Cell
get.setMaxVersions(10);
Result res4 = table.get(get);
List<Cell> cells = res4.getColumnCells(Bytes.toBytes("mycf"), Bytes.toBytes("name"));
for (Cell c : cells) {
// getValue 内部 也是使用 cloneValue 的
byte[] cValue = CellUtil.cloneValue(c);
System.out.println(Bytes.toString(cValue));
}
// 节省网络开销,get 一个比较大的列时能缩短传输时间
boolean exists = table.exists(get);
// delete
Delete del = new Delete(Bytes.toBytes("row1"));
del.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("name"));
table.delete(del);
// 如果当前存储的不是 tim ,则不会删除。如果传 null,则 col 不存在时删除
boolean res = table.checkAndDelete(Bytes.toBytes("row1"), Bytes.toBytes("mycf"),
Bytes.toBytes("name"), Bytes.toBytes("tim"), del);
// mutation 大原子操作,例如增加一列并删除另一列。
// 实际名字叫 mutateRow,强调针对一行进行操作,rowkey不同会报错
// 删除 mycf:age 列
Delete delete = new Delete(Bytes.toBytes("row3"));
delete.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("age"));
// 修改 mycf:name 为 chris
Put edit = new Put(Bytes.toBytes("row3"));
edit.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("name"),
Bytes.toBytes("chris"));
// 新增列
Put put3 = new Put(Bytes.toBytes("row3"));
put3.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("job"),
Bytes.toBytes("engineer"));
RowMutations rowMutations = new RowMutations(Bytes.toBytes("row3"));
rowMutations.add(delete);
rowMutations.add(edit);
rowMutations.add(put);
table.mutateRow(rowMutations);
// 只会在一开始check一次给出的value跟数据库中现有的value是否一致
table.checkAndMutate(Bytes.toBytes("row3"), Bytes.toBytes("mycf"),
Bytes.toBytes("age"), CompareFilter.CompareOp.LESS,
Bytes.toBytes("5"), rowMutations);
// 批量操作,在一个 actions 中不要同时放针对一个单元格的 put 和 delete,因执行顺序不定
List<Row> actions = new ArrayList<>();
Get get1 = new Get(Bytes.toBytes("row2"));
actions.add(get1);
Put put1 = new Put(Bytes.toBytes("row3"));
put.addColumn(Bytes.toBytes("mycf"), Bytes.toBytes("name"),
Bytes.toBytes("lily"));
actions.add(put1);
Delete delete1 = new Delete(Bytes.toBytes("row1"));
actions.add(delete1);
Object[] res5 = new Object[actions.size()];
table.batch(actions, res5); // 早期有不需要传递 res5 的方法,但不安全,操作失败时没有返回
// res5 的结果可能是:
// null: 操作与服务器通信失败
// EmptyResult: Put和Delete操作成功后的返回结果
// Result: Get 操作成功后的结果,没有匹配就是一个空的Result
// Throwable
byte[] oneRes = ((Result) res5[0]).getValue(Bytes.toBytes("mycf"),
Bytes.toBytes("name"));
System.out.println(Bytes.toString(oneRes));
// 批量 put,不是原子,可能有的成功有的不成功。
// 不成功会重试,除非 NoSuchColumnFamilyException。
// 失败数据会被放到写缓冲区,等下一次插入数据时重试
table.put(new ArrayList<Put>());
// 批量 get,如果有一个失败有会整体失败,如果需要部分返回,则用batch
table.get(new ArrayList<Get>());
// 批量删除,如果全部删除成功,那么 List 的长度变为0
try {
table.delete(new ArrayList<Delete>());
} catch (RetriesExhaustedException e) {
// 可以获取异常的原因和参数
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// Scan,获取多条数据。通常加上始末位置。另外,如果addColumn,那么没有添加的就不会被扫描,所以,如果想实现SELECT name from A where age > 10的时候,需要把name和age都添加进去,这样针对age的过滤器(高级API介绍)才会起作用。
Scan scan = new Scan(Bytes.toBytes("row1")) // 通常还会加上Filter,暂时忽略
.setCaching(100); // 一次 RPC 请求返回多少条数据
try (ResultScanner res6 = table.getScanner(scan);) {
// 获取结果的方法与 get 不同,因为 get 的结果要等 table.get() 执行完才能获得
// 而 scan 则是在遍历 ResultScanner 时才执行 scan
for (Result r : res6) {
String name1 = Bytes.toString(r.getValue(Bytes.toBytes("mycf"), Bytes.toBytes("name")));
System.out.println(name1);
}
}
}
}HBase内部实现
简单的预告与补充
- Namespace:表命名空间不是强制的, 当想把多个表分到一个组去统一管理的时候才会用到表命名空间。
- Table( 表) : 一个表由一个或者多个列族组成。 数据属性, 比如超时时间( TTL) , 压缩算法( COMPRESSION) 等, 都在列族的定义中定义。 定义完列族后表是空的, 只有添加了行, 表才有数据。
- Column Qualifier:列
HBase不支持表关联,部分支持ACID。
Namespace
把相同业务的表分成同一组,从而方便配额管理、安全管理等。目前只能通过shell调用,在创建表时加上。
create ‘myns:table1‘,‘mycf1‘
alter_namespace ‘myns‘,{METHOD=>‘set‘,‘PROPERTY_NAME‘=>‘PROPERTY_VALUE‘}
alter_namespace ‘ns1‘,{METHOD=>‘unset‘,NAME=>‘PROPERTY_VALUE‘}HBase中有两个保留表空间是预先定义好的:
- Hbase: 系统表空间, 用于HBase内部表。
- default: 那些没有定义表空间的表都被自动分配到这个表空间
下
存储架构
RegionServer
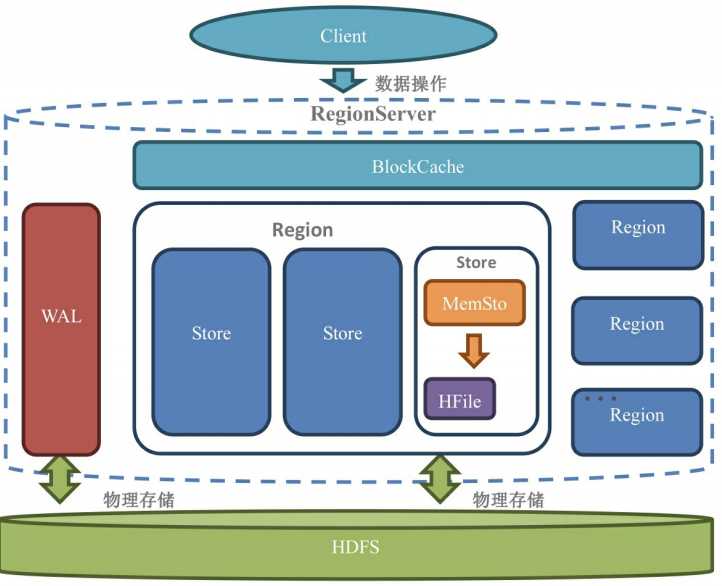
- 一个RegionServer包含一个WAL,多个Region。Region划分规则是:一个表的一段键值在一个RegionServer上会产生一个Region。不过当你1行的数据量太大了(要非常大,否则默认都是不切分的),HBase也会把你的这个Region根据列族切分到不同的机器上去。
- WAL: 预写日志,当操作到达Region的时候, HBase先把操作写到WAL里。另外,HBase会先把数据放到基于内存实现的Memstore里, 等数据达到一定的数量时才刷写( flush) 到最终存储的HFile内。这个过程如果宕机,就从WAL中回复数据。
- Region:每一个Region都有起始rowkey和结束rowkey, 代表了它所存储的row范围。每一个Region内都包含有多个Store实例。划分规则是:一个列族分为一个Store,如果一个表只有一个列族,那么这个表在这个机器上的每一个Region里面都只有一个Store。
- Store: 一个Store对应一个列族的数据, 如果一个表有两个列族, 那么在一个Region里面就有两个Store。一个Store里面只有一个Memstore,但有多个HFile。每次Memstore的刷写就产生一个新的HFile出来。
- BlockCache:不是必要项,但默认开启,在调优部分介绍。
WAL
Mutation的子类,如Put、Append、Increment、Delete都可以通过setDurability(Durability.SKIP_WAL)设置WAL相关。也可设置异步,并设定时间间隔,但数据有可能丢失,时间间隔权衡可能丢失的量。
WAL滚动:WAL的检查间隔由hbase.regionserver.logroll.period定义,默认值为1小时。检查的内容是把当前WAL中的操作跟实际持久化到HDFS上的操作比较,看哪些操作已经被持久化了,被持久化的操作就会被移动到.oldlogs文件夹内(这个文件夹也是在HDFS上的)。一个WAL实例包含有多个WAL文件。WAL文件的最大数量通过
hbase.regionserver.maxlogs(默认是32)参数来定义。
其他触发条件:
- 当WAL文件所在的块(Block)快要满了;
- 当WAL所占的空间大于或者等于某个阀值(
hbase.regionserver.hlog.blocksize * hbase.regionserver.logroll.multiplier),前者把它设置为HDFS块大小,后者默认0.95,则如果WAL文件所占的空间大于或者等于95%的块大小,则这个WAL文件就会被归档到.oldlogs文件夹内。
Master会负责定期地去清理.oldlogs文件夹,如果WAL文件没有任何引用指向。这些指向有两个:
- TTL进程:该进程会保证WAL文件一直存活直到达到hbase.master.logcleaner.ttl定义的超时时间(默认10分钟)为止
- 备份(replication)机制:有两个集群才需要考虑,HBase要保证备份集群已经完全不需要这个WAL文件了,才会删除这个WAL文件。
Store
MemStore:每个Store中有一个MemStore实例。数据写入WAL之后就会被放入MemStore。MemStore是内存的存储对象,只有当MemStore满了的时候才会将数据刷写(flush)到HFile中。
设计目的
- 为了让数据顺序存储从而提高读取效率。数据会先在Memstore中整理成LSM树,最后再刷写到HFile上。如果开启了BlockCache,那么会先读取BlockCache,没有才到HFile+Memstore。
- 优化数据的存储。比如一些数据添加后又马上被删除了。
数据是先写入WAL(HDFS,数据到达的顺序),再被放入Memstore(内存,数据整理后的顺序),最后被持久化到HFile(HDFS,数据整理后的顺序)中。HDFS中的文件是不可修改的,只能创建、追加、删除。
HFile:在Store中有多个HFile。当MemStore满了之后HBase就会在HDFS上生成一个新的HFile,然后把MemStore中的内容写到这个HFile中。HFile直接跟HDFS打交道,它是数据的存储实体。
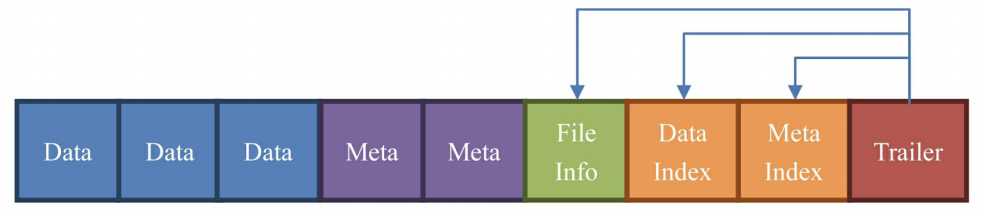
HFile(StoreFile,HFile的抽象类)是由一个一个的块组成的。在HBase中一个块的大小默认为64KB,由列族上的BLOCKSIZE属性定义。
- Data:数据块。每个HFile有多个Data块。我们存储在HBase表中的数据就在这里。Data块其实是可选的,但是几乎很难看到不包含Data块的HFile。
- Meta:元数据块。Meta块是可选的,Meta块只有在文件关闭的时候才会写入。Meta块存储了该HFile文件的元数据信息,在v2之前布隆过滤器(Bloom Filter)的信息直接放在Meta里面存储,v2之后分离出来单独存储。
- FileInfo:文件信息,其实也是一种数据存储块。FileInfo是HFile的必要组成部分,是必选的。它只有在文件关闭的时候写入,存储的是这个文件的信息,比如最后一个Key(LastKey),平均的Key长度(Avg Key Len)等。
- DataIndex:存储Data块索引信息的块文件。索引的信息其实也就是Data块的偏移值(offset)。DataIndex也是可选的,有Data块才有DataIndex。
- MetaIndex:存储Meta块索引信息的块文件。MetaIndex块也是可选的,有Meta块才有MetaIndex。
- Trailer:必选的,它存储了FileInfo、DataIndex、MetaIndex块的偏移值。
Data数据快组成:BlockType, Cell(KeyValue), Cell, Cell …。一行的一列代表一个KV,遍历的时候也是一个一个KV地遍历。
Data数据块的第一位存储的是块的类型,后面存储的是多个KeyValue键值对,也就是单元格(Cell)的实现类。块的类型一直在增加,例如上面提及的DATA、META、FILE_INFO、ROOT_INDEX等。
KeyValue:如下图,每个KV都有列族和列名等信息,所以如果他们太大,会很占空间。如果数据主要是归档数据,不太要求读写性能,那么建议使用压缩。

增删查改:实际上,HBase几乎总是在做新增操作。新增/修改/删除单元格时,HBase都会在HDFS新增数据,只是写上不同的cell,如版本号、类型为DELETE且值为null。
这种方式必然会破环数据的连续性和顺序性,这促使HBase需要定期进行数据的合并,在major compaction时,一旦检测到delete标记的记录就会忽略,从而实现删除(后面有稍详细的介绍)。
存储过程
一个KeyValue在从客户端被发送出来到被持久化进HBase或者从HBase持久化层被读出到客户端的过程。
写入:WAL - MemStore - HFile
读取:先BlockCache再到Memstore+HFile。
墓碑标记和数据不在一个地方,所以有可能先读到数据后读到墓碑。要知道数据是否已被删除,HBase的Scan操作会继续往下扫描,直到被扫描的数据大于给出的限定条件为止,这样它才能知道哪些数据应该被返回给用户,而哪些应该被舍弃。所以你增加过滤条件也无法减少Scan遍历的行数,只有缩小STARTROW和ENDROW之间的行键范围才可以明显地加快扫描的速度。
在Scan扫描的时候store会创建StoreScanner实例。StoreScanner会把MemStore和HFile结合起来扫描,所以具体从MemStore还是HFile中读取数据,外部的调用者都不需要知道具体的细节。当StoreScanner打开的时候,会先定位到起始行键(STARTROW)上,然后开始往下扫描,一个一个KV地扫描。
宏观层面读取
0.96版本之后使用二层查询架构。
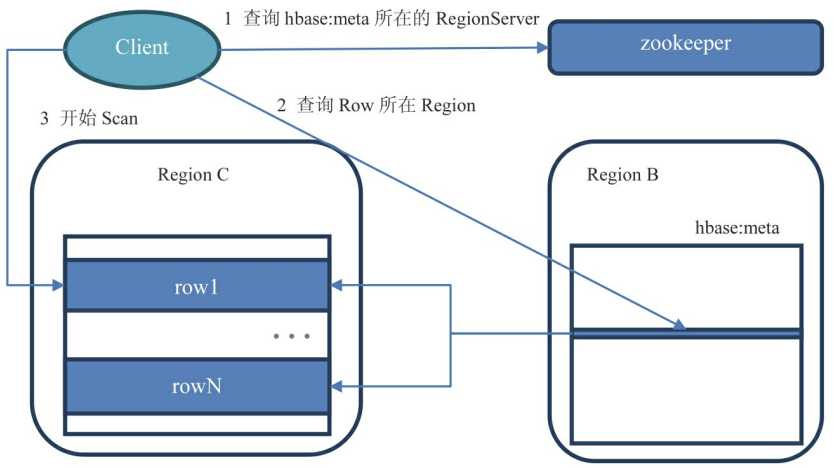
- 客户端先通过ZooKeeper的/hbase/meta-region-server节点查询到哪台RegionServer上有hbase:meta表。
- 客户端连接含有hbase:meta表的RegionServer。hbase:meta表存储了所有Region的行键范围信息,通过这个表就可以查询出你要存取的rowkey属于哪个Region的范围里面,以及这个Region又是属于哪个RegionServer。
- 获取这些信息后,客户端就可以直连其中一台拥有你要存取的rowkey的RegionServer,并直接对其操作。
- 客户端会把meta信息缓存起来,下次操作就不需要进行以上加载hbase:meta的步骤了。
高阶客户端API
过滤器
基础
过滤器相当于SQL中的Where语句。HBase中的过滤器被用户创建出来后会被序列化为
可以网络传输的格式,然后被分发到各个RegionServer。在RegionServer中Filter被还原出来。这样在Scan的遍历和Get的过程中,不满足过滤器条件的结果就不会被返回客户端。
由于分发到不同机器,所以并不知道各个scanner的结果数量,如果需要限制数量,只能在scanner返回结果时对结果进行处理。
所有的过滤器都要实现Filter接口。HBase同时还提供了FilterBase抽象类,它提供了Filter接口的默认实现,这样大家就不必把Filter接口的每一个方法都写上自己的实现了。
// 和基础API一样,下面代码是包裹在try{}里面的
Table table = conn.getTable(TableName.valueOf("mytable"));
Scan scan = new Scan();
// 选出 value 为 ‘%apple%‘ 的数据。注意是针对 value ,不区分列
ValueFilter filter1 = new ValueFilter(CompareFilter.CompareOp.EQUAL,
new SubstringComparator("apple"));
// 选出 value 为 ‘apple‘
// new BinaryComparator("apple")
// 数值比较,下面选出等于10的
// new BinaryComparator(Bytes.toBytes(10))
scan.setFilter(filter1);
try (ResultScanner res = table.getScanner(scan);){
for (Result r : res) {
String name = Bytes.toString(r.getValue(Bytes.toBytes("mycf"),
Bytes.toBytes("name")));
// 如果匹配的(无论哪一列)就会有 Result 返回,但这里打印时选择 name,所以非 name 列的
// 的 name 变量会是null
System.out.println(name);
}
}
// 选出 name 列的 value 为 ‘%apple%‘ 的数据。
// 务必保证每行记录都包含有将要比较的列,否则没有比较列的行会整行被放入结果集。
// 如果无法保证,第一种方案:则在遍历结果集的时候再次判断结果是否包含所需的列,没有的话会像上面那样返回null。
// 第二种方案:使用过滤器列表 FilterList(后面介绍)。这种方法比较慢,但不会像第一种方法那样返回过多数据。
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(Bytes.toBytes("mycf"),
Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL, new SubstringComparator("apple"));
// 分页过滤器,如果放到 FilterList 中,一般都是放在最后
PageFilter pageFilter = new PageFilter(2L);
// 翻页
PageFilter pageFilter1 = new PageFilter(2L);
scan.setFilter(filter1);
byte[] lastRowkey = null;
try(ResultScanner rs1 = table.getScanner(scan)){
lastRowkey = printResult(rs1); // 代码看下面
}
byte[] startRowkey = Bytes.add(lastRowkey, new byte[1]); // 加上一个0字节来排出上一次结果的最后一行
scan.setStartRow(startRowkey);
try(ResultScanner rs2 = table.getScanner(scan)){
printResult(rs2);
}
// FilterList 方案,实现 (xiamen OR shanghai) AND active=‘1‘
FilterList innerFilterList = new FilterList(FilterList.Operator.MUST_PASS_ONE);
Filter xiamenFilter = new SingleColumnValueFilter(Bytes.toBytes("mycf"),
Bytes.toBytes("city"), CompareFilter.CompareOp.EQUAL,
new BinaryComparator(Bytes.toBytes("xiamen")));
innerFilterList.addFilter(xiamenFilter);
Filter shanghaiFilter = new SingleColumnValueFilter(Bytes.toBytes("mycf"),
Bytes.toBytes("city"), CompareFilter.CompareOp.EQUAL,
new BinaryComparator(Bytes.toBytes("shanghai")));
innerFilterList.addFilter(shanghaiFilter);
FilterList outerFilterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
outerFilterList.addFilter(outerFilterList);
Filter activeFilter = new SingleColumnValueFilter(Bytes.toBytes("mycf"),
Bytes.toBytes("active"), CompareFilter.CompareOp.EQUAL,
new BinaryComparator(Bytes.toBytes("1")));
outerFilterList.addFilter(activeFilter);
scan.setFilter(outerFilterList);
// printResult
private static byte[] printResult(ResultScanner res){
byte[] lastRowKey = null;
for (Result r : res) {
byte[] rowkey = r.getRow();
String name = Bytes.toString(r.getValue(Bytes.toBytes("mycf"), Bytes.toBytes("name")));
int age = Bytes.toInt(r.getValue(Bytes.toBytes("mycf"), Bytes.toBytes("age")));
System.out.println(Bytes.toString(rowkey) + ": name=" + name + " age=" + age);
lastRowKey = rowkey;
}
return lastRowKey;
}行过滤器
行过滤器RowFilter:根据rowkey,配合比较器来过滤,这样比Get或Scan配合STARTROW和ENDROW更灵活。
多范围过滤器MultiRowRangeFilter:把不同的范围RowRange加入到数组,然后放入MultiRowRangeFilter实现。
行键前缀过滤器PrefixFilter:使用时要配合scan.setStartRow(startRowkey),避免从头开始遍历。当遍历时发现rowkey大于规定的前缀就会停止扫描。
模糊行键过滤器FuzzyRowFilter:根据处在中间或者结尾的关键词来过滤行键。
FuzzyRowFilter filter = new FuzzyRowFilter(Arrays.asList( new Pair<>( Bytes.toBytesBinary("2016_??_??_4567"), new byte[] {0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0} ) ));包含结尾过滤器InclusiveStopFilter:也可以通过scan.setEndRow(endRowkey),这里
endRowkey = Bytes.add(endRowkey, new byte[1])随机行过滤器RandomRowFilter:用于采样,设置一个0.0~1.0的数,相当于每个样本被采集概率。
列过滤器
FamilyFilter
QualifierFilter
依赖列过滤器DependentColumnFilter:表中需要设置一个依赖列,然后DependentColumnFilter以该依赖列的时间戳去过滤其他的列,凡是时间戳比依赖列的时间戳大的列都会被过滤掉。这是为了解决高并发下多用户修改数据,导致scan出来的数据是部分更新的脏数据。如下图所示,client2可以在最后才更新依赖列来避免脏读。通常加上dropDependentColumn参数为true,因为依赖列始终是有结果返回的,但如果其他列都被过滤了,那么只有依赖列的结果通常也是无意义的。有需要的话还可以加上比较器。
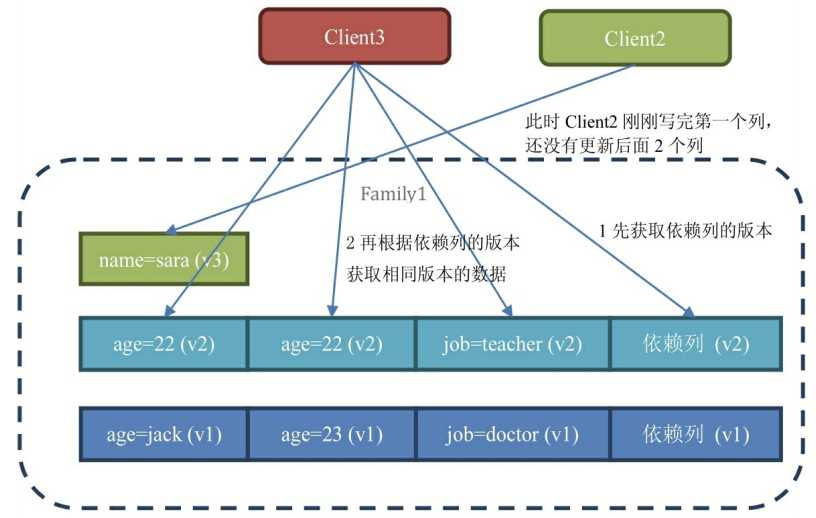
setBatch和DependentColumnFilter不能同时使用,因为使用了setBatch(int n)后scan每遍历n个单元格都会停下来把结果返回给客户端。这样就有可能出现,某行数据读取到一半,但是还没有读取到依赖列,就满足了batch的条件,并将结果集返回给了客户端。这种情况下,依赖列过滤器就无法工作了。
列前缀过滤器ColumnPrefixFilter
多列前缀过滤器
byte[][] filter_prefix = new byte[2][]; filter_prefix[0] = Bytes.toBytes("a"); filter_prefix[2] = Bytes.toBytes("b"); MultipleColumnPrefixFilter prefixFilter = new MultipleColumnPrefixFilter(filter_prefix);列键过滤器(KeyOnlyFilter):在不需要value,只需要列名时使用。注意从Result中获取key的方法可参考下面代码
for (Result r : res) { List<Cell> cells = r.listCells(); List<String> sb = new ArrayList<>(); byte[] rowkey = r.getRow(); sb.add("row=" + Bytes.toString(rowkey)); for (Cell cell : cells) { sb.add("column=" + new String(CellUtil.cloneQualifier(cell))); } System.out.println(StringUtils.join(sb, ", ")); }首次列键过滤器FirstKeyOnlyFIlter:只检索第一列后立马跳到下一行,一般用于count。
int count = 0; for (Result r : res) { count++; }列名范围过滤器ColumnRangeFilter
列数量过滤器ColumnCountGetFilter:针对Get,只选择前n个列返回。(略)
列翻页过滤器ColumnPaginationFilter:针对Get。(略)
单元格、装饰、自定义过滤器
单元格过滤器
- 时间戳过滤器TimestampsFilter:适用于自定义时间戳的场景,因为过滤是要精确到毫秒的。
- 之前介绍的值过滤器也属于此类
装饰过滤器
跳转过滤器:当被包装的过滤器判断当前的KeyValue需要被跳过的时候,整行都会被跳过
Filter vf = new ValueFilter(CompareFilter.CompareOp.NOT_EQUAL, new BinaryComparator(Bytes.toBytes("north"))); Filter skipFilter = new SkipFilter(vf);全匹配过滤器WhileMatchFilter:当遇到需要过滤的目标时停止scan。
自定义过滤器(略)
比较器
除了BinaryComparator和SubstringComparator,HBase还有下列比较器:
- RegexStringComparator + CompareOp.EQUAL
- NullComparator + CompareOp.EQUAL或CompareOp.NOT_EQUAL
- LongComparator:把BinaryComparator(Bytes.toBytes(10))改为LongComparator(10L)
- 比特位比较器(BitComparator):比特位比较器的构造函数需要两个传参:要计算的比特数组和计算方法。计算方法的可选值由BitComparator.BitwiseOp枚举类提供,有AND、OR和XOR可选。HBase会将你传入的比特数组通过你要求的计算方法跟数据库中的值进行比特位计算。当比较关系为EQUAL的时候,结果集中包含的那些运算结果为非全0的结果。当比较关系为NOT_EQUAL的时候,只有运算结果为全0的记录会被放入结果集。
- 字节数组前缀比较器(BinaryPrefixComparator):你提供一段字节数组,然后字节数组前缀比较器会帮你挑出所有以这段字节数组打头的记录。
协处理器(略)
客户端API的管理功能
列族管理
// 列数据生存时间。Put方法也有TTL,是单元格的TTL
newCol.setTimeToLive(10);
// 某个单元格的数据存储达到了最大版本数的数据的时候,再插入新数据会将旧数据删除
newCol.setMaxVersions(100);
// BloomFilter默认开启,且采用行模式。介绍看下面。
setBloomFilterType(BloomType bt);
//每次写入的时候是否更新布隆过滤器。默认为false
setCacheBloomsOnWrite(boolean value);
// 默认为开启
setBlockCacheEnabled(boolean blockCacheEnabled);
// 默认关闭
setMobEnabled(boolean isMobEnabled);
setMobThreshold(long threshold);布隆过滤器
在之前的介绍可知,HFile中可有块索引,让HBase去扫描后再到data块去找,但速度还不够快,便引入布隆过滤器。如下图所示,如果BloomFilter认为某HFile中不存在所需数据,那么HBase就不会去扫描。
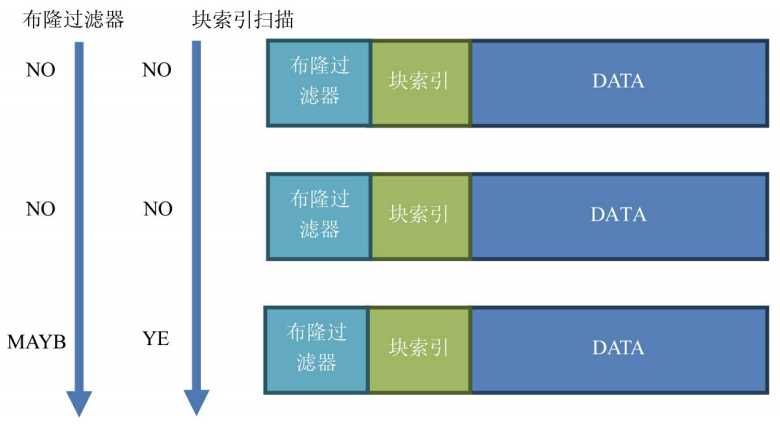
BloomFilter默认开启,且采用行模式,即针对行进行过滤。也有行列(ROWCOL)模式,针对列进行过滤,但如果查询中会遍历很多列,那么就不必要使用。这种行列模式需要存储行和列的信息,所以很占空间。
大字段
MOB(Medium Object):大于100KB小于10MB。HBase存储MOB字段的时候其实也是把该文件直接存储到HDFS上,而在表中只存储了该文件的链接。
该特性只在HFile版本3以上才有,所以使用该特性之前先打开hbase-site.xml确认一下你的HFile版本至少大于等于3
表管理
// 默认10GB,超过就会触发Region拆分。如果设置为null,则无限大。
setMaxFileSize();
setReadOnly();
setMemStoreFlushSize
// 增、改、删列族Region管理
// close region, serverName 为"服务器,服务器端口,服务器启动码",中间是英文逗号
admin.closeRegion(String regionname, String serverName);
// 重新上线
admin.assign(byte[] regionname);
// 获取region列表
admin.getOnlineRegions(ServerName sn);
// ServerName通过ServerName.valueOf(hostAndPort, startCode)获取
// 获取host, port, startCode
admin.getClusterStatus().getServers();
// 获取RegionServer列表,并从中获取素有Regions
Collection<ServerName> serverNames = admin.getClusterStatus().getServers();
Iterator<ServerName> iter = serverNames.iterator();
while (iter.hasNext()) {
ServerName serverName = iter.next();
List<HRegionInfo> regions = admin.getOnlineRegions(serverName);
for (HRegionInfo region : regions) {
System.out.println(region.getRegionNameAsString());
}
}管理region的其他方法(略)
快照管理
将某个表恢复到某个时刻的结构和数据,而且不需要担心创建和恢复的过程会很缓慢。这个过程实际上并没有复制数据,而是保存一份文件列表,通过修改表所链接的文件来改变表的数据。这样不但速度快,而且不额外占用磁盘空间。
使用:
// 修改配置,开启快照功能(默认开启)
// 创建快照
admin.snapshot("snapshot_name", TableName.valueOf("table"));
// 获取快照,如果这个集群之前没有创造过快照,那么得到的是空列表。
List<HBaseProtos.SnapshotDescription> snapshots = admin.listSnapshots();
// 使用快照前要将表下线
admin.disableTable(TableName.valueOf("table_name"));
while (true) {
Thread.sleep(1000);
if (admin.isTableDisabled(TableName.valueOf("table_name"))) {
admin.restoreSnapshot("snapshotName");
admin.enableTable(TableName.valueOf("table_name"));
break;
}
}维护工具管理
均衡器
移动Region到不同的RegionServer上。HBase使用StochasticLoadBalancer来实现,它考虑了下面5个因素:
- Region Load:Region的负载。
- Table Load:表的负载。
- Data Locality:数据本地化。
- Memstore Sizes:Memstore(存储在内存中)的大小。
- Storefile Sizes:Storefile(存储在磁盘上)的大小。
相关参数:
- hbase.balancer.period:默认300000毫秒,即5分钟。均衡器会启动一个叫BalancerChore的线程,该线程会定时去扫描是否有RegionServer需要做重均衡。
影响Region的拆分/合并的参数:
- hbase.regions.slop:均衡容忍值,如果某个RS上的region个数大于
average + (average * slop)个region,那么就进行rebalance。 - 拆分Region的策略定义hbase.regionserver.region.split.policy。
- 单个Region下的最大文件大小hbase.hregion.max.filesize。
- hbase.regions.slop:均衡容忍值,如果某个RS上的region个数大于
规整器
当某个Region太大了,或者太小了就称其为不标准的Region。规整器就是为了调整region大小的。
步骤:
- 获取该表的所有Region。
- 计算出该表的Region平均大小。
- 如果某个Region大于平均大小的2倍,则需要被拆分。
- 不断合并最小的两个Region,只要最小的两个Region大小之和小于Region平均大小,这两个Region就会被合并。
- 空Region(大小小于1MB)并不参与规整过程。
目录管理器
目录指的就是hbase:meta表中存储的Region信息。当HBase在拆分(Split)或者合并(merge)的时候,为了确保数据不丢失都会保留原来的Region信息。等拆分或者合并过程结束后,再使用目录管理器(catalog janitor)来清理这些旧的Region信息。
拆分过程:创建两个子Region,将数据复制到子Region中,删除父Region。
集群状态以及负载
通过Admin的getClusterStatus方法可以获取集群状态(ClusterStatus)类。该类可以做很多事情,比如可以获取当前活着的RegionServer的数量、当前所有Region的数量、当前集群中的请求TPS等。
服务器负载对象
通过服务器负载对象(ServerLoad),大家可以获取当前服务器的负载信息,比如内存使用情况、磁盘使用情况、请求数量等信息。不过更丰富的信息需要从UI,即<servername>:16030/jmx获取
其他管理(略)
可见性标签管理
实现简单的权限控制。开启该功能前确保HBase使用的HFile版本达到3以上,同时在配置中开启VisibilityController。
说到权限控制,在shell中可以用whoami来得知自己的身份和用户组。在Java调用API中,利用System.getProperty("user.name")来获知。
// 列出所有系统标签
VisibilityLabelsProtos.ListLabelsResponse resp = VisibilityClient.listLabels(conn, ".*");
List<ByteString> lables = resp.getLabelList();
for (ByteString lable : lables) {
System.out.println(lable.toStringUtf8());
}
// 添加标签,需要超级用户才能操作。超级用户可在配置文件中设置。
String[] labels2 = {"manager", "developer"};
VisibilityClient.addLabels(conn, labels2);测试(详细看书)
性能优化
Master和RegionServer的JVM调优
内存分配
由于默认的RegionServer的内存才1GB,而Memstore默认是占40%,所以分配给Memstore的才400MB,在实际场景下,很容易就写阻塞了。在hbase-env.sh调大Master和RS各自的堆大小。
ambari例子:对于16GB的机器
- 2GB:留给系统进程。
- 8GB:MapReduce服务。平均每1GB分配6个Map slots + 2个
- Reduce slots。
- 4GB:HBase的RegionServer服务。
- 1GB:TaskTracker。
- 1GB:DataNode。
如果没有MapReduce的话,RegionServer可以调整到大概一半的服务器内存。
GC调优
Full GC时间过长可能导致RS自杀(被ZK判断为宕机)。JVM提供下面4种回收器:
- 串行回收器(SerialGC)。
- 并行回收器(ParallelGC),主要针对年轻带进行优化(JDK 8默认策略)。
- 并发回收器(ConcMarkSweepGC,简称CMS),主要针对年老带进行优化。
- G1GC回收器,主要针对大内存(32GB以上才叫大内存)进行优化
HBase比较合适的方案是ParallelGC和CMS的组合。
对于RS内存大于32GB的,G1GC比较适合。因为CMS在下面两种情况都会出发Full GC
- 同步模式失败(concurrent mode failure):在CMS还没有把垃圾收集完的时候空间还没有完全释放,而这个时候如果新生代的对象过快地转化为老生代的对象时发现老生代的可用空间不够了。此时收集器会停止并发收集过程,转为单线程的STW(Stop The World)暂停,这就又回到了Full GC的过程了。可通过
XX:CMSInitiatingOccupancyFraction=70缓解,代表堆内存占用了百分之几时启动回收。 - 碎片化造成的失败:老年代内存空间没有足够大的连续空间。Memstore是会定期刷写成为一个HFile的,在刷写的同时这个Memstore所占用的内存空间就会被标记为待回收,一旦被回收了,这部分内存就可以再次被使用,但CMS只做回收不做合并,所以只要你的RegionServer启动得够久一定会遇上Full GC。
G1GC策略通过把堆内存划分为多个Region,然后对各个Region单独进行GC,这样整体的Full GC可以被最大限度地避免(Full GC还是不可避免的,我们只是尽力延迟Full GC的到来时间),而且这种策略还可以通过手动指定MaxGCPauseMillis参数来控制一旦发生Full GC的时候的最大暂停时间,避免时间太长造成RegionServer自杀。
如果内存在4~32GB之间,则需要试验,试验期间记得加上下列参数
-XX:PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy
Justin Kestelyn在文章Tuning Java Garbage Collection for HBase中的调优参考结果看书。
Memstore的专属JVM策略MSLAB(MSLAB是在G1前发明的,G1与其类似,但两者可配合使用)
解决这个问题不能完全靠JVM的GC回收策略,最好的解决方案是从应用本身入手,自己来管好自己的内存空间。HBase的MSLAB机制完全沿袭了TLAB的实现思路:
- 引入chunk的概念,所谓的chunk就是一块内存,大小默认为2MB。
- RegionServer中维护着一个全局的MemStoreChunkPool实例,一个chunk池。
- 每个MemStore实例里面有一个MemStoreLAB实例。
- 当MemStore接收到KeyValue数据的时候先从ChunkPool中申请一个chunk,然后放到这个chunk里面。
- 如果这个chunk放满了,就新申请一个chunk。
- 如果MemStore因为刷写而释放内存,则按chunk来清空内存。
这种机制会降低内存利用率,因为就算chunk里面只放1KB的数据,这个chunk也要占2MB的大小。不过可以完全避免Full GC。
相关参数(略)
Region的拆分与合并
拆分
为了避免传统关系型数据库把大量数据存储到同一磁盘而导致读取速度下降的问题。
拆分分为自动和手动:
自动:
- ConstantSizeRegionSplitPolicy,默认10GB
- IncreasingToUpperBoundRegionSplitPolicy(默认):上限为
Math.min(tableRegionsCount^3 * initialSize, defaultRegionMaxFileSize)。如果设置了hbase.increasing.policy.initial.size,initialSize就用它,否则为hbase.hregion.memstore.flush.size * 2。defaultRegionMaxFileSize=默认10GB。假设flush.size为128MB,那么只有一个文件时,上限为256MB,两个2GB,三个6.75Gb,4个10GB。 - KeyPrefixRegionSplitPolicy:上者的增强,保证了有相同前缀的rowkey不会被拆分到两个不同的Region里面。该策略会根据KeyPrefixRegionSplitPolicy.prefix_length所定义的长度来截取rowkey作为分组的依据。如果rowkey的前缀划分比较细而导致查询容易发生跨Region查询时才考虑,即这个策略适合:数据有多种前缀且查询多是针对前缀,比较少跨越多个前缀来查询数据。另外,此时别用时间戳来做rowkey。
- DelimitedKeyPrefixRegionSplitPolicy:同样继承自IncreasingToUpperBoundRegionSplitPolicy。通过分隔符来获得前缀,适用rowkey非定长的情景。
- BusyRegionSplitPolicy:计算一段时间的请求阻塞率是否大于阈值。根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
- hbase.busy.policy.blockedRequests:请求阻塞率,取值范围是0.0~1.0,默认是0.2。
- hbase.busy.policy.minAge:为了防止在判断是否要拆分的时候出现了短时间的访问频率波峰。默认值是600000,即10分钟
- hbase.busy.policy.aggWindow:计算是否繁忙的时间窗口。默认值是300000,即5分钟
- DisabledRegionSplitPolicy:手动拆分时用。
手动:
预拆分:在建表的时候就定义好了拆分点。Linux命令为
hbase org.apache.hadoop.hbase.util.RegionSplitter split_table splitAlg -c 10 -f mycf。splitAlg:
- HexStringSplit:据从“00000000”到“FFFFFFFF”之间的数据长度按照n等分
- UniformSplit:有点像HexStringSplit的byte版
- 手动指定拆分点:
create ‘table‘, ‘mycf‘, SPLITS=>[‘aaa‘,‘bbb‘,‘fff‘]
强制拆分:用split命令
推荐:
- 用预拆分导入初始数据。
- 然后用自动拆分来让HBase来自动管理Region。
合并
分为offline和online:
- offline需要下线整个集群,用Linux命令进行合并
- online需要进入hbase shell,利用merge_region合并
WAL优化(略,在新版本中实质没什么可优化的)
BlockCache的优化
BlockCache的原理:读请求到HBase之后先尝试查询BlockCache,如果获取不到就去HFile(StoreFile)和Memstore中去获取。如果获取到了则在返回数据的同时把Block块缓存到BlockCache中。这些block有多种,参考HFile中的块种类。
LRUBlockCache:将Cache分为三个区域/阶段。BlockCache目前的堆内内存方案只有这个,而且无法关闭,只能调整大小。默认0.4。LRUBlockCache的问题在于可能引发Full GC。
BlockCache配置和Memstore配置的联动影响:Memstore + BlockCache的内存占用比例不能超过0.8,为必须要留20%作为机动空间。而Memstore也是默认0.4,所以调大Memstore或BlockCache时都需要调小另一个。
BucketCache(阿里员工提出):堆外缓存,默认开启。一上来就分配了14种(可自定义)区域,如4KB、8KB、16KB…,每种区域的大小都等于最大规格的4倍。缓存位置可以是堆(heap)、堆外(offheap)、文件(file,针对SSD硬盘)。BucketCache的长处是它自己来划分内存空间、自己来管理内存空间,Block放进去的时候是考虑到offset偏移量的(具体可以看源码的BucketAllocator),所以内存碎片少
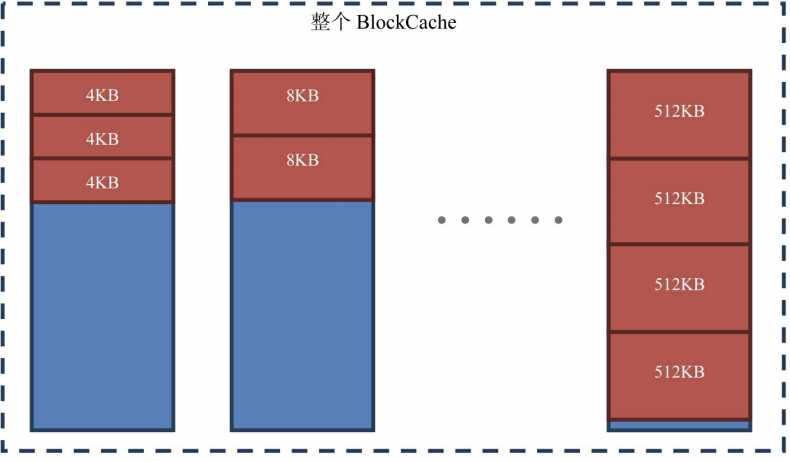
每一种类型的Bucket至少要有一个Bucket,否则报错。
- 两者组合:Index Block和Bloom Block会被放到LRUCache中Data Block被直接放到BucketCache中,所以数据会去LRUCache查询一下,然后再去BucketCache中查询真正的数据。考虑到成本和性能的组合,比较合理的介质是:LRUCache使用内存->BuckectCache使用SSD->HFile使用机械硬盘。
看缓存命中率:hadoop metrics,查看hbase.regionserver.blockCacheHitRatio
Memstore的优化
Memstore fush的五种情况:
单个memstore大小达到阈值
hbase.hregion.memstore.flush.size默认128MB:因为刷写是定期检查的,所以无法及时地在数据到达阈值时触发刷写。如果数据增加到阈值的好几倍(这个倍数通过hbase.hregion.memstore.block.multiplier设置,默认4,所以默认阻塞机制的阈值为512MB)就会触发flush,但这个flush会阻塞所有写入该Store的写请求。HBase的这个机制本身的目的是应对如果数据再继续急速增长会带来更可怕的灾难性后果,所以不能因此而盲目增大阻塞阈值。整个RegionServer的memstore总和达到阀值:
globalMemStoreLimitLowMarkPercent * globalMemStoreSize,前者通过hbase.regionserver.global.memstore.size.lower.limit设置,默认0.95;后者通过hbase_heapsize(RegionServer占用的堆内存大小)* hbase.regionserver.global.memstore.size默认0.4。一旦达到这个global.memstore.size便同样会触发一次阻塞写入的flush。例如16G堆内存,上面lower.limit默认0.95,memstore.size默认0.4,那么触发flush的阈值是16 x 0.4 x 0.95 = 6.08,而触发阻塞的阈值为16 x 0.4 = 6.4。
WAL的数量大于maxLogs:这个flush不会阻塞,只是开启滚动,并创造新的memstore内存空间来加载WAL中的数据
Memstore达到刷写时间间隔:如果以上的所有条件都没有被触发到,HBase还是会按照一个特定的频率来flush。
hbase.regionserver.optionalcacheflushinterval,默认值为3600000,即1个小时。如果设定为0,则意味着关闭定时自动刷写。也有手动flush(略)
HFile的合并
合并的原因想尽量减少碎片文件,进而减少查询数据时的寻址。HFile合并操作就是在一个Store里面找到需要合并的HFile,然后把他们合并起来,最后把之前的碎文件移除。
合并策略
Minor:将Store中多个HFile合并为一个HFile。在这个过程中达到TTL的数据会被移除,但是被手动删除的数据不会被移除。这种合并触发频率较高。
0.96之后的合并策略ExploringCompactionPolicy:待合并文件挑选条件:
文件 < (所有文件大小总和 - 该文件大小) * 比例因子和文件大小小于最小合并大小hbase.hstore.compaction.min.size(没设置就用hbase.hregion.memstore.flush.size)都会进入待合并列表。从待合并文件中挑出多个文件进行穷举组合,组合要处于hbase.hstore.compaction.min/max之间。挑选完组合后,比较哪个文件组合包含的文件更多,就合并哪个组合。如果出现平局,就挑选那个文件尺寸总和更小的组合。FIFOCompactionPolicy:效果是过期的块被整个删除掉了。没过期的块完全没有操作。所以它实际上是一个删除策略。有些情况下HFile是没必要合并,比如TTL特别短,有些表只是业务中间表(而且一般不会出现跨几个HFile读取数据);BlockCache够大,可以把整个RegionServer上存储的数据都放进去。这个策略不适合TTL很长,或者MIN_VERSIONS > 0的情况。
MIN_VERSIONS就是当TTL到来的时候单元格需要保存的最小版本数。当版本达到TTL需要被删除的时候会先看一下单元格里面的版本数是不是等于MIN_VERSIONS,如果是的话就放弃删除操作。注意MIN_VERSIONS只是针对TTL,其他delete操作可以使版本数小于MIN_VERSIONS。
DateTieredCompactionPolicy:
- 目的:假设场景是最新的数据最有可能被读到,从而需要达到新旧程度的文件相互合并,但太旧的文件就不管了。
- 该策略涉及三个参数:基本时间窗长度和增长倍数,例如基本的时间窗长度是1小时,增长倍数是2,那么最新的时间窗的边界线就是当前时间减去1小时;次新的时间窗是当前时间减去2个小时,以此类推。在同一个窗口里面的文件如果达到最小合并数量(hbase.hstore.compaction.min)就会进行合并(在文件跨时间线的时候,将该文件计入下一个时间窗口),合并策略默认为
ExploringCompactionPolicy,也可以设置FIFO。最后一个参数是最老的层次时间。 - 场景:这个策略适用于专注最新的数据的系统和基本不删除数据的系统。最后一点详细看书,“可能”是因为,如果文件超过最老的层次后TTL才到期,那这些文件就无法被删除。不适用于数据改动很频繁,并且连很老的数据也会被频繁改动。经常边读边写数据。
StripeCompactionPolicy:
目的:提高查询速度的稳定性,让Major Compaction可以只针对部分数据,从而克服了Major Compaction因涉及HFile文件过多而造成的IO不稳定。
- 数据从Memstore刷写到HFile上后先落在L0,然后随着时间的推移,当L0大小超过一定的阀值的时候就会引发一次合并。这次合并会把KeyValue从L0读出来,然后插入到Strips层的HFile中去,而Strips的块是根据键位范围(KeyRange)来划分的。
- 场景:Region至少大于2GB,Rowkey要具有统一格式,能够均匀分布。
Major:合并Store中的所有HFile为一个HFile。在这个过程中被手动删除的数据会被真正地移除。同时被删除的还有单元格内超过MaxVersions的版本数据。这种合并触发频率较低,默认为7天一次。不过由于Major Compaction消耗的性能较大,你不会想让它发生在业务高峰期,建议手动控制MajorCompaction的时机。
以上是关于HBase的主要内容,如果未能解决你的问题,请参考以下文章
Hbase 出现 org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet 错误(示例代码