用6个案例说明如何恢复PXC集群
Posted liuhongru
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用6个案例说明如何恢复PXC集群相关的知识,希望对你有一定的参考价值。
原文链接:https://blog.csdn.net/zengxuewen2045/article/details/51868976
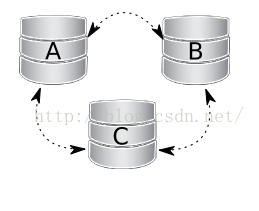
1、 案例一:三个节点,关闭一个
由于维护和配置变更等工作需要,正常关闭节点A,其它节点会收到”good by”信息,cluster size大小会减少,一些属性如仲裁计算和自动增长都会自动改变。一旦我们再次启动节点A,它将会基于my.cnf文件中的wsrep_cluster_address设置加入集群.这个过程是很不同于正常复制---加入者节点不会提供任何请求,直到再次与集群完全同步,所以正连接到集群中提供同等作用的节点是不足的,首次ST必需成功。如果在节点A关闭期间,节点B或节点C的写数据集gcache中仍然存在他们所有执行过的事务,加入集群可能通过增量同步(IST,快和轻量),否则,需要进行全量同步,实际上就是全量二进制数据复制。因此,决定一个最佳贡献者是重要的,如果因贡献者gcache丢失了事务,增量同步是不可能发生,则回退决定由贡献者和全量同步自动代替。
图示如下:

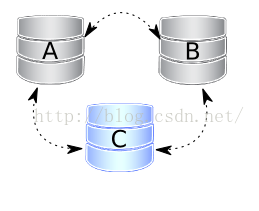
2、 案例二:三个节点,关闭两个
节点A和节点B正常关闭。通过熟悉前面的案例,cluster size减少到1。因此,即使是单个节点C,组成一个主要组件,提供客户端请求。获得这些节点要返回到集群中的需求时,你仅需要启动他们,可是,当它必需提供ST给首个加入的节点时,节点C切换到“Donor/Desynced”状态。在那个过程期间,它仍然是可以读写的,但是它可能非常慢,取决于它发送的st有多大。所以,一些负载均衡器可能认为贡献者节点是不可操作的或是从池中移除了。所以,最好避免当只有一个节点在线时的场景。
需要注意的是,如果你按顺序重启节点A和节点B,当节点A的gcache可能不含有所有需要的写数据集时,你可以想要节点B确保不使用节点A作为ST贡献者。所以指定节点C作为贡献者的方法(你指定一个带有wsrep_node_name变量的节点名为node C):
service mysql start --wsrep_sst_donor=nodeC
图示如下:
3、案例三:三个节点,全部关闭
所有三个节点都正常关闭。集群已废,在这个案例中,这问题是如何再次初始化,这里有一点很重要的要知道,在节点干净关闭期间,PXC节点会将最后一个执行位置写进grastate.dat文件中,通过比较文件里面的seqno号,你会看到最先进位置的节点(最可能是最后关闭的节点),集群必需使用这个节点自举启动,否则,先进位置的节点必需与后进位置节点执行全量同步初始化加入集群(和一些事务将会丢失),
给出一些自举启动第一个节点的脚本:
/etc/init.d/mysql bootstrap-pxc或 service mysql bootstrap-pxc或service mysql start --wsrep_new_cluster或service mysql start --wsrep-cluster-address="gcomm://"
或在centos 7中使用系统服务包:systemctl start [email protected],在老的pxc版本中,自举启动集群,需要在my.cnf文件中将wsrep_cluster_address变量的内容替换为空:wsrep_cluster_address=gcomm:// 。
图示如下:
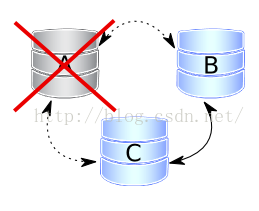
4、案例四:一个节点从集群中消失
节点A从集群中消失。消失的意思是指断电、硬件损坏、内核错误,mysql崩溃、kill -9 mysqld进程等,两个剩余的节点注意到连接A节点已关闭,并尝试重新连接到它。一些超时后,两个节点都同意节点A确实关闭和从集群中正式移除它。仲裁保留(三个中的两个正常在线),因此,没有中断服务发生。重启后,节点A按场景一的相同的方法自动加入集群。
图示如下:
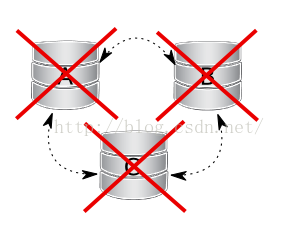
5、案例五:两个节点从集群中消失
节点A和节点B消失,节点C不能组成单独仲裁,所以集群切换进入非主模式,mysql拒绝提供任何SQL查询,在这个状态中,节点C的mysql进程仍然运行,你能连接到它,但任何语句相关的数据失败都带有:
mysql> select * from test.t1;
ERROR 1047 (08S01): Unknown command
实际上节点C在一瞬间读是可能的,直到它决定不能到达节点A和节点B,但没有立即新写入的被允许,由于galera的基于复制的认证。
我们将看到剩余节点的日志是什么:
140814 0:42:13 [Note] WSREP: commit failed for reason: 3
140814 0:42:13 [Note] WSREP: conflict state: 0
140814 0:42:13 [Note] WSREP: cluster conflict due to certification failure for threads:
140814 0:42:13 [Note] WSREP: Victim thread:
THD: 7, mode: local, state: executing, conflict: cert failure, seqno: -1
SQL: insert into t values (1)
单个节点C正等待它的同等作用的伙伴们再次在线,在一些案例中,当网络中断和在所有时间那些节点up时,集群会再自动组成。如果节点B和节点C与第一节点的网络断了,但它们之间仍相互到达,当他们组成仲裁时,他们能保持自己的功能,如果节点A和B崩溃(数据不一致、bug等)或者由于断电下线,你需要人工在节点C上启用主组件,你能将节点A和B带回集群中,这个方法,我们可以告诉节点C,你可以单独组成一个集群,可以忘记节点A和节点B,这个命令是:
SET GLOBAL wsrep_provider_options=‘pc.bootstrap=true‘;
可是,你在做这个操作前,需要多检查确认其它节点是否真正down了,最有可能最终会有两个不同的数据集群。
图示如下:

6、案例6:所有节点不正确地关闭
这个场景可以发生在数据中心电源失败,命中mysql或galera bug以致于所有节点崩溃的案例中,但数据一致性结果要作出让步—--集群检测到每个节点的数据不同,在那些案例的每一个里,grastate.dat 文件不能被更新和不能包含有效的seqno号,它可能看起来像这个:
cat /var/lib/mysql/grastate.dat
# GALERA saved state
version: 2.1
uuid: 220dcdcb-1629-11e4-add3-aec059ad3734
seqno: -1
cert_index:
在这个案例中,我们不能确信所有节点之间是否一致的,所以关键是要找到最前进节点,用它来自举启动集群,在任何节点上启动mysql daemon前,你必须通过检查它的事务状态来提取最后的序列号,你能按下面方法来做:
[[email protected] ~]# mysqld_safe --wsrep-recover
140821 15:57:15 mysqld_safe Logging to ‘/var/lib/mysql/percona3_error.log‘.
140821 15:57:15 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
140821 15:57:15 mysqld_safe WSREP: Running position recovery with --log_error=‘/var/lib/mysql/wsrep_recovery.6bUIqM‘ --pid-file=‘/var/lib/mysql/percona3-recover.pid‘
140821 15:57:17 mysqld_safe WSREP: Recovered position 4b83bbe6-28bb-11e4-a885-4fc539d5eb6a:2
140821 15:57:19 mysqld_safe mysqld from pid file /var/lib/mysql/percona3.pid ended
所以在这个节点上的最后提交的事务序列号是2,现在你需要先从最后节点上自举启动,然后再启动其它节点。 然而,以上方法在新的galera版本3.6及以上是不需要的,自pxc 5.6.19是可用的。
有一个新的选项--- pc.recovery(默认是启用),它用于保留集群状态到每个节点上的gvwstate.dat文件里,当作变量名说明(pc – primary component),它只保留一个主要状态的集群。
那个文件的内容看起来像如下:
cat /var/lib/mysql/gvwstate.dat
my_uuid: 76de8ad9-2aac-11e4-8089-d27fd06893b9
#vwbeg
view_id: 3 6c821ecc-2aac-11e4-85a5-56fe513c651f 3
bootstrap: 0
member: 6c821ecc-2aac-11e4-85a5-56fe513c651f 0
member: 6d80ec1b-2aac-11e4-8d1e-b2b2f6caf018 0
member: 76de8ad9-2aac-11e4-8089-d27fd06893b9 0
#vwend
我们能看到以上三个节点集群是启动的,多亏了这项新功能,在我们的数据中心停电的情况下,上电后回来,节点将读取启动最后的状态,将尝试恢复主组件一旦所有成员再次开始看到对方。这使得PXC集群自动被关闭而无需任何人工干预恢复。在log中,我们可以看到:
140823 15:28:55 [Note] WSREP: restore pc from disk successfully
(...)
140823 15:29:59 [Note] WSREP: declaring 6c821ecc at tcp://192.168.90.3:4567 stable
140823 15:29:59 [Note] WSREP: declaring 6d80ec1b at tcp://192.168.90.4:4567 stable
140823 15:29:59 [Warning] WSREP: no nodes coming from prim view, prim not possible
140823 15:29:59 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 2, memb_num = 3
140823 15:29:59 [Note] WSREP: Flow-control interval: [28, 28]
140823 15:29:59 [Note] WSREP: Received NON-PRIMARY.
140823 15:29:59 [Note] WSREP: New cluster view: global state: 4b83bbe6-28bb-11e4-a885-4fc539d5eb6a:11, view# -1: non-Primary, number of nodes: 3, my index: 2, protocol version -1
140823 15:29:59 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
140823 15:29:59 [Note] WSREP: promote to primary component
140823 15:29:59 [Note] WSREP: save pc into disk
140823 15:29:59 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = yes, my_idx = 2, memb_num = 3
140823 15:29:59 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
140823 15:29:59 [Note] WSREP: clear restored view
(...)
140823 15:29:59 [Note] WSREP: Bootstrapped primary 00000000-0000-0000-0000-000000000000 found: 3.
140823 15:29:59 [Note] WSREP: Quorum results:
version = 3,
component = PRIMARY,
conf_id = -1,
members = 3/3 (joined/total),
act_id = 11,
last_appl. = -1,
protocols = 0/6/2 (gcs/repl/appl),
group UUID = 4b83bbe6-28bb-11e4-a885-4fc539d5eb6a
140823 15:29:59 [Note] WSREP: Flow-control interval: [28, 28]
140823 15:29:59 [Note] WSREP: Restored state OPEN -> JOINED (11)
140823 15:29:59 [Note] WSREP: New cluster view: global state: 4b83bbe6-28bb-11e4-a885-4fc539d5eb6a:11, view# 0: Primary, number of nodes: 3, my index: 2, protocol version 2
140823 15:29:59 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
140823 15:29:59 [Note] WSREP: REPL Protocols: 6 (3, 2)
140823 15:29:59 [Note] WSREP: Service thread queue flushed.
140823 15:29:59 [Note] WSREP: Assign initial position for certification: 11, protocol version: 3
140823 15:29:59 [Note] WSREP: Service thread queue flushed.
140823 15:29:59 [Note] WSREP: Member 1.0 (percona3) synced with group.
140823 15:29:59 [Note] WSREP: Member 2.0 (percona1) synced with group.
140823 15:29:59 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 11)
140823 15:29:59 [Note] WSREP: Synchronized with group, ready for connections
图示如下:
以上是关于用6个案例说明如何恢复PXC集群的主要内容,如果未能解决你的问题,请参考以下文章