reduceByKeygroupByKey和combineByKey
Posted wwcom123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了reduceByKeygroupByKey和combineByKey相关的知识,希望对你有一定的参考价值。
在spark中,reduceByKey、groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结:
?reduceByKey
用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义;
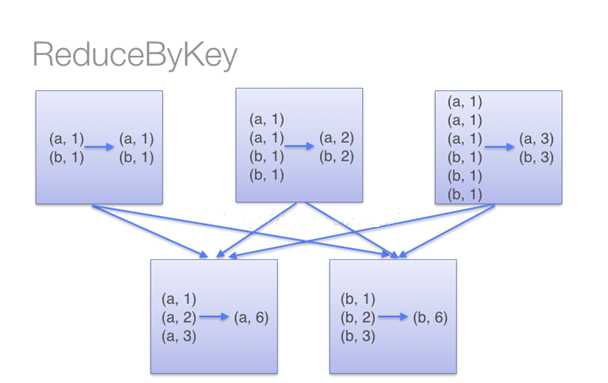
?groupByKey
也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
使用groupByKey时,spark会将所有的键值对进行移动,不会进行局部merge,会导致集群节点之间的开销很大,导致传输延时。
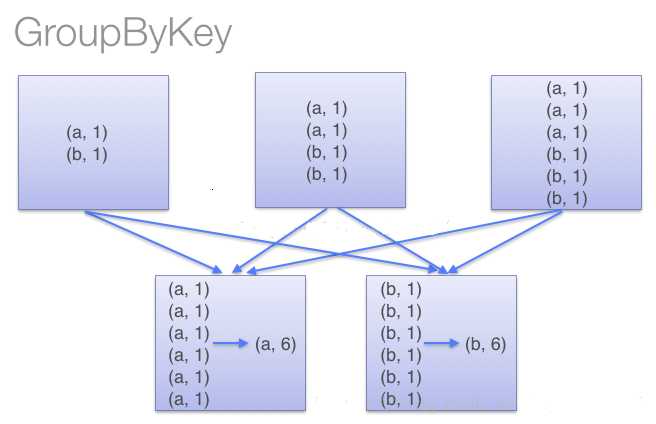
?combineByKey
一个相对底层的基于键进行聚合的基础方法(因为大多数基于键聚合的方法,例如reduceByKey,groupByKey都是用它实现的),所以感觉这个方法还是挺重要的。
该方法的入参主要为前三个:
- createCombiner:遍历一个分区中每个元素,如果不存在,createCombiner创建累加器C,把原变量V放入,对相同K,把V合并成一个集合,例如将(key,88),映射建立集合(key,(88,1))
- mergeValue:遍历一个分区中每个元素,如果已存在,将相同的值累加,例如将(key,(88,1)),(key,(88,1)),mergeValue累加集合为(key,(88,2))
- mergeCombiners:createCombiner 和 mergeValue 是处理单个分区中数据, mergeCombiners是每个分区处理完了,多个分区合并数据使用,例如分区1累加集合值为(key,(88,2)),分区2累加集合值为(key,(88,3)),mergeCombiners累加集合为(key,(88,5))
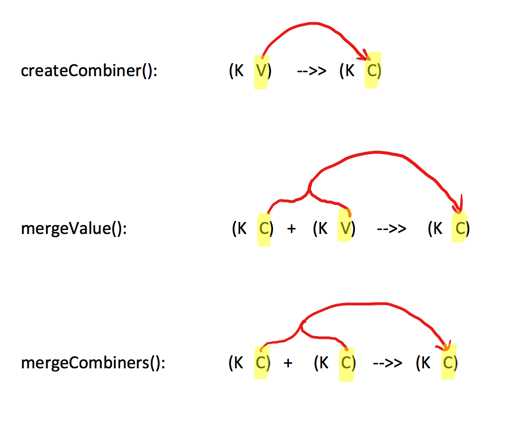
写个求每个学生的平均成绩的例子
//2个学生及他们的成绩
val scoreList = Array(("ww1", 88), ("ww1", 95), ("ww2", 91), ("ww2", 93), ("ww2", 95), ("ww2", 98))
//将2个学生成绩转为RDD,分2个partition存储
val scoreRDD: RDD[(String, Int)] = sc.parallelize(scoreList, 2)
println("【scoreRDD.partitions.size】:" + scoreRDD.partitions.size)
//分区数,【scoreRDD.partitions.size】:2
println("【scoreRDD.glom.collect】:" + scoreRDD.glom().collect().mkString(",")) //每个分区的内容
//使用combineByKey,按每个学生累积分数和科目数量
val rddCombineByKey: RDD[(String, (Int, Int))] = scoreRDD.combineByKey(v => (v, 1),
(param1: (Int, Int), v) => (param1._1 + v, param1._2 + 1),
(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2))
println("【combineByKey】:" + rddCombineByKey.collect().mkString(","))
//【combineByKey】:(ww2,(377,4)),(ww1,(183,2))
//在map中使用case是scala的用法,按每个学生总成绩/科目数量,得到平均分
val avgScore = rddCombineByKey.map { case (key, value) => (key, value._1 / value._2.toDouble) }
println("【avgScore】:" + avgScore.collect().mkString(","))
//【avgScore】:(ww2,94.25),(ww1,91.5)
说明:
1.首先:各个分区createCombiner 和 mergeValue先干活
第一个分区遍历开始: 数据为
Array(("ww1", 88), ("ww1", 95), ("ww2", 91))
--> 处理(ww1,88), 因为是第一次遇到键“ww1”, 所以调用createCombiner方法 (v)=> (v,1) , 这里就是(ww1,88) =>( ww1, (88,1))
--> 处理(ww1,95),不是第一次遇到键“ww1”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww1,(88,1)),(ww1,95)=>(ww1,(88+95, 1+1))= (ww1,(183,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,91),因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,91) => (ww2, (91,1))
第一个分区遍历结束:返回 (ww1,(183,2) ), ( ww2,(91,1))
第二个分区遍历开始: 数据为
Array(("ww2", 93), ("ww2", 95), ("ww2", 98))
--> 处理(ww2,93), 因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,93 )=>(ww2, (93,1))
--> 处理(ww2,95),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(93,1)),(ww2,95)=>(ww2,(93+95, 1+1))= (ww2,(188,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,98),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(188,2)),(ww2,98)=>(ww2,(188+98, 2+1))= (ww2,(286,3) ) ---(成绩相加,科目数量+1)
第二个分区遍历结束:返回 (ww2,(286,3) )
2.然后:各个分区干完了, mergeCombiners方法汇总处理
--> 处理分区1的ww1,(183,2) ww2,(91,1) ,分区2的ww2,(286,3) , 会调用mergeCombiners方法(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2)),这里就是
( (ww1,(183,2)),(ww2,(91,1)) , (ww2,(286,3)) )=> ( (ww1,(183,2)) , (ww2,(91+286,1+3)) ) = ( (ww1,(183,2)) , (ww2,(377,4)) )
以上是关于reduceByKeygroupByKey和combineByKey的主要内容,如果未能解决你的问题,请参考以下文章
如何仅混淆 com.foo.* 和 com.bar.* (ProGuard)?
如何为顶点(example.com)和子域(www.example.com)配置相同的来源 - aws Route53 和 CloudFront