关于adaboost分类器
Posted xiashiwendao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于adaboost分类器相关的知识,希望对你有一定的参考价值。
我花了将近一周的时间,才算搞懂了adaboost的原理。这根骨头终究还是被我啃下来了。
Adaboost是boosting系的解决方案,类似的是bagging系,bagging系是另外一个话题,还没有深入研究。Adaboost是boosting系非常流行的算法。但凡是介绍boosting的书籍无不介绍Adaboosting,也是因为其学习效果很好。
Adaboost首先要建立一个概念:
弱分类器,也成为基础分类器,就是分类能力不是特别强,正确概率略高于50%的那种,比如只有一层的决策树。boosting的原理就是整合弱分类器,使其联合起来变成一种"强分类器"。
在Adaboost中,就是通过训练出多个弱分类器,然后为他们赋权重;最后形成了一组弱分类器+权重的模型,
那么,关键来了怎么选择弱分类器,怎么来分配权重?据说弱分类器可以是svm,可以是逻辑回归;但是我看到资料和描述都是以决策树为蓝本的。
要想要搞懂adaboost,还要搞懂他的两个层级的权重,第一个权重是上面我们讲到的分类器的权重,成为alpha,是一个浮点型的值;
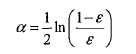
另外一个是样本权重,称之为D,是一个列向量,和每个样本对应。首先讲一下样本权重,在一个分类器训练出来之后,将会重新设置样本权重,首个分类器他的样本权重是一样的,都是1/sample_count,然后每每次训练完,都会调整这个这个样本权重,为什么?我们继续沿用决策树说事。调整的策略就是增大预测错误的样本的权重,为什么?样本权重只有一个作用,就是计算错误权重,错误权重errorWeight=D.T * errorArr,errorArr是预测错误的列向量,预测正确的样本对应值0,预测错误的为1,样本权重D就是做件事情,那么对于决策树模型而言,本轮某个特征判断错了,那么样本其实就上了黑名单,用数学表示就是这个这个样本的权重将会增加,
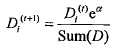
样本权重增加导致了什么?其实不会导致什么,即使说明了某个样本的错误比重要增加。所谓错误权重,都是判断错误,如果历史某个样本已经判读出错过一次,那么这个样本如果再错,它的错误权重就要增加,这种权重的改变(D中元素wi的总和不变,保持为1),将会导致weighterror值更加有意义,判定最小weighterror也会更加准确。如果判断对了,会相应的减小样本的权重。
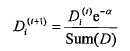
两层的权重介绍完了,基本算法也就明了了。
下面即使就两层权重来说明一下两层算法。内层的算法是遍历样本中的每个特征,然后再从特征值的最小值开始尝试进行分类,逐渐按照等量增加特征值不断地尝试分类一直达到最大值,走完了一轮特征,换下一个特征,在逐次增加特征值...计算下来每次尝试的错误权重,记录下来最小的错误权重的信息,信息包括:特征列索引,特征值以及逻辑比较(大于还是小于),当把所有的特征跑完一遍,到此,一个分类器就横空出世了,设么是分类器?本质就是最小错误权重的信息,就是分类器。
1 # 分类,满足指定取值范围的分类为-1,不满足的为1 2 def stumpClassifier(dataMat, dim, threshValue, inequal): 3 #print("stumpClassifier-dataMat: ") 4 #print(dataMat) 5 retArr = ones((shape(dataMat)[0], 1)) 6 if(inequal=="lt"): 7 retArr[dataMat[:,dim]<=threshValue] = -1 8 else: 9 retArr[dataMat[:,dim]>threshValue] = -1 10 return retArr 11 12 # 返回一个弱分类器,本质上就是一个一层决策树,这棵树包括: 13 # 1.错误权重最低的区分特征以及特征值信息 14 # 2.最小错误权重 15 # 3.最小错误权重对应的预测分类 16 def buildstump(dataArr, labelArr, D): 17 datamat = mat(dataArr) 18 labelmat = mat(labelArr).T 19 m,n = shape(datamat) 20 errorArr = mat(zeros((m,1))) 21 beststump = {} 22 bestClassEst = mat(zeros((m, 1))) 23 minError = inf 24 numstep = 10.0 # 这里设置了一个float类型 25 # 遍历每一列,寻求最分度最大的特征(维度)自己特征值 26 for i in range(n): 27 minvalue = datamat[:,i].min() 28 maxvalue = datamat[:,i].max() 29 stepsize = (maxvalue - minvalue)/numstep 30 for j in range(-1, int(numstep) + 1): 31 for ineq in ["lt", "gt"]: 32 threshValue = minvalue + int(j) * stepsize 33 predictValue = stumpClassifier(datamat, i, threshValue, ineq) 34 errorArr = mat(ones((m, 1))) # 一个列向量 35 # 这里设置分类正确的矩阵值为0,这样在参与计算错误权重的时候,正确分类就不参与计算,只有错误分类错误的样本才会参与计算 36 errorArr[predictValue==labelmat] = 0 37 # 这里注意,虽然是行向量和列向量相乘结果是累加值,但是形式还是一个矩阵,结果获取方需要通过float等函数进行处理 38 # D在初始化的时候是1/m,之后将会根据学习情况,提高错误样本的权重,减少正确样本点的权重 39 weightError = D.T * errorArr 40 #print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshValue, ineq, weightError)) 41 if(weightError < minError): 42 minError = weightError 43 bestClassEst = predictValue.copy() 44 beststump["dim"] = i 45 beststump["threshVal"] = threshValue 46 beststump["ineq"] = ineq 47 48 return beststump, minError, bestClassEst
作为外层算法,是一个循环调用内层算法的过程,每当获得了一个分类器,都要为他计算权重,权重alpha的计算公式上面已经给出,总之和最小错误权重有关系,错误权重越小,分类器的权重越高,说明是优质分类器(相对的),反之亦然;然后就是累加权重alpha*预测值classEst,累加的目标就是sign和真实的分类器一致,注意是符号一致,真实分类器只有-1,1两种值。如果一致了,退出循环;不一致,说明还要再引入分类器,此时再来计算D值(参见上文公式),然后基于D值再来调用内层算法。
这样不断获得分类器,直到分类一致(或者循环次数达到指定次数)。外层算分目的是获取到一组分类器,这组分类器是经过训练,实现了全来一遍,就可以保证累加权重预测值之和的符号(sign)和真实的分类一致。
1 from numpy import multiply 2 from numpy import exp 3 from numpy import zeros 4 from numpy import log 5 6 # adaboost本质其实就是将多个分类器按照训练的权重进行整合,每个分类器都提供了区分度最高的特征以及特征值区分范围(包括值以及lt/gt) 7 # 在使用的时候因为是二元分类,所以每个分类器都是关注自己的识别出来的关键特征来进行分类,最后通过权重来进行整合。demo中的数据因为特征 8 # 比较少,所以三轮下来就OK了,如果是多特征的需要更多分类器来进行是别的。 9 def adaboostTransDS(dataArr, labelArr, itNum=41): 10 dataMat = mat(dataArr) 11 m = shape(dataMat)[0] 12 D = mat(ones((m, 1))/m) 13 weakClassArr=[] 14 aggClassEst=mat(zeros((m,1))) 15 for i in range(itNum): 16 # classESt代表的是本轮学习中,错误率最低的样本预测分类情况 17 # 获取一个分类器 18 bestStump, error, classEst = buildstump(dataMat, labelArr, D) 19 # 计算该分类器的alpha值,注意这里必须要通过float进行强壮,否则alpha将会是矩阵值形式,无法参与后续的计算。具体原因参见buildstump 20 # 注意alpha是分类器级别的权重,D则是分类器中样本的权重;而且error越小,alpha越大,分类器的权重也越大 21 alpha = float(0.5 * log((1 - error)/ max(error, 1e-16))) 22 bestStump["alpha"] = alpha 23 # 添加该分类器的信息 24 weakClassArr.append(bestStump) 25 26 # 计算下一个分类器中样本的D值(权重),D值是 27 labelMat = mat(labelArr).T 28 alphaLabel = -1 * alpha * labelMat 29 # labelMat和classEst要么-1,要么1,这里的乘法就是要解决一个问题:判断正确的是-alpha,判断错误的是alpha,这个逻辑是 30 # 根据D的公式来的,通过这个符号实现如果是判断正确,则减轻权重,判断错误则家中权重; 31 # 之所以要加重错误列的权重是为了让下一个分类器注意了,如果下一个分类器还是在此特征上面预测错误,那么错误权重会增加,这个 32 # 特征就作为最小错误权重(weihterror)特征出现的可能性就降低了。 33 expon = multiply((-1)*alpha * labelMat, classEst) 34 D = multiply(D ,exp(expon)) 35 # D是如何保证D集合的值之和是1的呢?因为D/D.sum(),就像1/6,2/6,3/6之和为1的道理一样的 36 D = D/D.sum() 37 print("alpha is: " + str(alpha)) 38 #print("D is: ") 39 #print(D) 40 print("classEst:") 41 print(classEst) 42 # 计算Error值,这里其实是累加每个分类器的预测值,直到他们的累加值的符号和目标分类目标一致,所以错误率并不是每个分类器的错误率 43 # 而是分类器的分类预估*alpha的累加列向量vs原始分类列向量的错误率。 44 # 之类classEst是由-1和1组成,所以是带有符号的 45 aggClassEst += alpha * classEst 46 #print("aggClassEst") 47 #print(aggClassEst) 48 errorMat = sign(aggClassEst) != labelMat 49 #print("errorMat") 50 #print(errorMat) 51 aggErrors = multiply(errorMat, ones((m,1))) 52 errorRate = aggErrors.sum() / m 53 print("error rate: %f" % errorRate) 54 55 if(errorRate == 0.0): 56 break 57 58 return weakClassArr
有了这组分类器,即adaboost classifieies,那么就可以进行分类了。
首先是获取训练数据集,然后通过外层算法获取到adaboost classifieies(组分类器),这个是训练过程;获得了组分类器之后,在获取测试数据集,然后遍历分类器,让每个分类器都对这批测试数据进行分类,每个分类器都会使用自己最好的分类方式(权重错误最低)来进行分类,即根据指定的特征,利用指定特征值进行比较分类;得到的分类结果(-1,1集合)将会乘以他们的权重(alpha),成为权重分类向量(weightClassEst);然后将各个分类器的权重分类向量进行累加(aggClassEst),最后取aggClassEst的符号作为分类结果。到此,分类结束。
1 def adaClassifier(dataToClass, classifierArr): 2 dataTestMat = mat(dataToClass) 3 print("handler dataset is: ") 4 print(dataTestMat) 5 classifer_count = shape(classifierArr)[0] 6 data_count = shape(dataTestMat)[0] 7 aggClassEst = mat(zeros((data_count, 1))) 8 for i in range(classifer_count): 9 classifier = classifierArr[i] 10 print(classifier) 11 classEst = stumpClassifier(dataTestMat, classifier["dim"], classifier["threshVal"], classifier["ineq"]) 12 aggClassEst += classifier["alpha"]*classEst 13 print("aggClassEst") 14 print(aggClassEst) 15 return sign(aggClassEst) 16 17 # 开始分类 18 dataMat, labelArr = loadSimpData() 19 classifierArr = adaboostTransDS(dataMat, labelArr, 9) 20 adaClassifier([[0,0],[5,5]], classifierArr)
以上是关于关于adaboost分类器的主要内容,如果未能解决你的问题,请参考以下文章