玩转高性能超猛防火墙nf-HiPAC
Posted ksiwnhiwhs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩转高性能超猛防火墙nf-HiPAC相关的知识,希望对你有一定的参考价值。
中华国学,用英文讲的,稀里糊涂听了个大概,不得不佩服西方人的缜密的逻辑思维,竟然把玄之又玄的道家思想说的跟牛顿定律一般,佩服。归家,又收到了邮件,还是关于nf-hipac的,不知不觉就想彻底整理一篇文章说个明白,可是哪有个够啊哪有个够。
匆匆吃完晚饭,碗也没刷,餐桌狼藉,家人都在看电视,玩手机,小小依然捧着iPad...我的摊子如下:
系统中添加了将近20000条的iptables规则,iperf的测试结果如下:
下面我来试一下nf-hipac,由于nf-hipac的命令语法和iptables基本兼容,因此按照下面的命令执行:
如此一来,系统中添加了将近2000条nf-hipac规则,iperf的测试结果如下:
幸运的是,我已经决定将其做成一个可以加载的内核模块了,并且支持2.6.32以及以上的内核。今晚开始了移植工作,基本分为几块的工作量:
a.适配match/target内核API
b.适配netlink内核API
在还没有完成模块化之前,只能在2.6.13上打patch了。能我相当信心的是,nf-hipac的内核补丁事实上是在net/ipv4/netfilter目录下的一个子目录nf-hipac,所有的文件全部在里面,并未对任何内核关键的数据结构打补丁,因此nf-hipac完全可以作为一个模块进行编译。
加入一个版本后缀
General setup ---> (hipac) Local version - append to kernel release
选中nf-HiPAC
Networking ---> Networking options --->
[*] Network packet filtering (replaces ipchains) --->
IP: Netfilter Configuration --->
<M> nf-HiPAC support (High Performance Packet Classification)
[*] Single path optimization
保存.config
系统启动完成
Options:
--proto -p [!] proto protocol: by number or name, eg. `tcp‘
--source -s [!] address[/mask] or
address[:address]
source(s) specification
--destination -d [!] address[/mask] or
address[:address]
destination(s) specification
--in-interface -i [!] devname
network interface name
--jump -j target
target for rule
--numeric -n numeric output of addresses and ports
--out-interface -o [!] devname
network interface name
--verbose -v verbose mode
--line-numbers print line numbers when listing
[!] --fragment -f match second or further fragments only
--version -V print package version.
----------
TCP options:
--syn match when only SYN flag set
--not-syn match when not only SYN flag set
--source-port [!] port[:port]
--sport ...
match source port(s)
--destination-port [!] port[:port]
--dport ...
match destination port(s)
----------
UDP options:
--source-port [!] port[:port]
--sport ...
match source port(s)
--destination-port [!] port[:port]
--dport ...
match destination port(s)
----------
ICMP options:
--icmp-type typename match icmp type
(or numeric type or type/code)
see also: nf-hipac -h icmp
----------
STATE options:
--state [!] [INVALID|ESTABLISHED|NEW|RELATED|UNTRACKED|ESTABLISHED,RELATED]
State to match
----------
TTL options:
--ttl value[:value] match time to live value(s)
----------
如果nf-hipac命令中出现了iptables的match,比如从/lib/iptables目录加载的libipt_set.so中的ipset match以及任何iptables的match模块,最终都要排在dimtree的叶子节点进行独立的iptables匹配过程。代码里面已经很清晰的表明了这一点。nf-hipac的HOOK函数是hipac_match,该函数首先进行例行的高效的HiPAC算法匹配,然后找到一个叶子节点,该叶子节点可能体现出两种行为:
nf-hipac is invoked before iptables
如果你想让iptables首先进行匹配,那么请执行:
iptables的规则在内存中是线性排列的,内核的HOOK通过遍历这些规则链进行逐一匹配,这个逐一匹配的顺序内含了优先级的概念,首先加入的rule首先被匹配到。但是除了这个顺序的排列之外,规则之间再也没有了别的关联,因此很难将它们作为一个整体来进行优化。
ipset将ip地址,端口等统一进行管理,但是同一个集合中的元素只能采取统一的动作,即target,虽然在ip地址的匹配中极端高效,但是使用起来很不灵活,很难做到比如同在set中的ip1和ip2执行不同的-j target动作。ipset是将单一的match统一管理进行优化的,和多条iptables规则没有必然的关系,即它没有将多条iptables规则关联起来。
除了傻傻的线性排列,除了单一match的hash/tree统一管理,iptables和match,target之间还能有别的关系吗?即它们之间还能有别的排列方式吗?当然有,这就是nf-hipac的方式。nf-hipac采用了另一种排列方式,即将固定的match进行排序,也就是说将每一条规则拆开来,这就就可以化不确定为确定。确定的是match的总的种类,不确定的是规则的数量,最终确定的match的数量决定了树的高度,而这个不确定的规则数量影响的仅仅是树的广度,仅此而已。
nf-hipac不更新了,没人维护了,难道是作者因此找到好的工作了,难道是作者结婚了,难道是作者生孩子了...这种判断也太中国化了,反正就是不更新了...单单谈效率,ipset完全可以让nf-hipac下课,但是谈点别的之后,nf-hipac的优势就显现出来了。
如果我们结合上面的图仔细分析为何添加了20000条左右的nf-hipac,性能依然不受任何影响,就会发现,nf-hipac的匹配过程最多经过n层的树深度,而n是match的数量,在这20000条规则中,match的数量只有1个!!注意了,这就是关键,1个!如果使用iptables,那么匹配的过程最多经过m个rule。也就是说,nf-hipac将m个rule拆散了之后,将其中所有的match压缩成了n层的树,每一层拥有m个层的区间交集匹配,这些交集仅仅决定其下层树节点的rule交集。照此说来,很多的数据包从第一个match集合(所有rule的第一个match组成的集合)树根开始匹配,一旦rule的match交集变成空,就可以直接下决断“没有匹配的rule”了,所以即便是少数种类的match集合节点,一个数据包也不一定能从树根匹配到最后一个match集合。这就是nf-hipac超猛的根本原因。
对于nf-hipac树的查找,需要注意的是,如果不是叶子节点,执行流只会碰触到最先配置的那条rule,即最下面的那条,其余的rule被隐藏在该最下面rule的上面,它们的作用仅仅是告诉执行流,该区间的下面的分支树节点是所有这些rule的交集,仅此而已。
从iptables到nf-hipac的变化是:从遍历m*n次(m为rule的数量,n为每一个rule的match的数量)简化为了遍历n次(n为所有rule中最多match的那一条rule的match的数量)。之所以如此就是因为nf-hipac将所有的rule作为一个整体来优化。那么代价是什么?代价就是插入rule,删除rule的开销。插入一条rule,首先需要将其所有的match拆分开来,然后找出每一个树节点的位置,即rule的插入位置,然后准备将这些match分别插入到那些位置中,是否插入取决于那个位置有没有对应rule的match交集,如果没有,则不予插入,删除的过程类似,也需要进行比较复杂的计算。
那么有没有什么办法让nf-hipac变得低效呢?很显然,当你了解了nf-hipac的dimtree的构造之后,你就会明白,n的数量越大,效率越低,n是什么?n是match的种类的数量。整个tree的深度就是n,如果自己构造20000种左右的match,那么试试看,仅仅配置一条nf-hipac规则,整个tree的构造将变成深度为2000的倒立的链表...我之所以仅仅设置一条nf-hipac规则是因为如果设置了多条,反而可能由于中途rule的match交集为空而提前退出遍历树。但是幸运的是,对于一个数据包那么多种的match是不必要的。
匆匆吃完晚饭,碗也没刷,餐桌狼藉,家人都在看电视,玩手机,小小依然捧着iPad...我的摊子如下:
如果说理论分析不足以镇住人,或者说一上来就讲理论可能把人吓跑,还是先来点感官上的体验吧。
0.感官感受
执行下面的命令:for((i=1;i<100;i++));do for((j=1;j<100;j++)); do iptables -A INPUT -s $i.10.193.$j -j DROP;done; done
for((i=1;i<100;i++));do for((j=1;j<100;j++)); do iptables -A INPUT -s $i.11.192.$j -j DROP;done; done系统中添加了将近20000条的iptables规则,iperf的测试结果如下:
下面我来试一下nf-hipac,由于nf-hipac的命令语法和iptables基本兼容,因此按照下面的命令执行:
for((i=1;i<100;i++));do for((j=1;j<100;j++)); do nf-hipac -A INPUT -s $i.10.193.$j -j DROP;done; done
for((i=1;i<100;i++));do for((j=1;j<100;j++)); do nf-hipac -A INPUT -s $i.11.192.$j -j DROP;done; done
二者的对比相当明显,最后我们来看一下既没有iptables又没有nf-hipac规则的时候,iperf的结果:
显而易见,nf-hipac加载20000个条目的结果和裸奔的结果是几乎一致的,这是多么令人兴奋的一件事啊!
1.如何使用nf-hipac
1.0.确认内核版本
很不幸,nf-hipac并非以一个可加载的内核模块存在,它是内核的一个patch。需要重新配置内核和重新编译内核才能使用它。除此之外,它对内核版本特别挑剔,官网可下载的最新版本早在2005年就终结了,因此它只是在2.6.13内核版本上可用(说是14,15,16,18都可以,我没有试)。因此我不得不退回到Debian4上去,然后在kernel.org上下载一个2.6.13版本的内核并着手nf-hipac的编译工作。幸运的是,我已经决定将其做成一个可以加载的内核模块了,并且支持2.6.32以及以上的内核。今晚开始了移植工作,基本分为几块的工作量:
a.适配match/target内核API
b.适配netlink内核API
在还没有完成模块化之前,只能在2.6.13上打patch了。能我相当信心的是,nf-hipac的内核补丁事实上是在net/ipv4/netfilter目录下的一个子目录nf-hipac,所有的文件全部在里面,并未对任何内核关键的数据结构打补丁,因此nf-hipac完全可以作为一个模块进行编译。
1.1.下载它
在网站http://www.hipac.org/上下载最新的nf-hipac-0.9.1.tar.bz2,这个版本是个终结版,此后再也没有更新,不知道作者哪去了。1.2.编译它
解压缩nf-hipac-0.9.1.tar.bz2,进入user目录,执行make install PREFIX=/usr/local IPT_LIB_DIR=/usr/local/lib/iptables,很容易就编译成功了。1.3.为内核打patch
进入新下载的2.6.13内核的根目录:cd /home/kernel/linux-2.6.13patch -p1 -F3 < /home/kernel/nf-hipac-0.9.1/nf-hipac-0.9.1.patchcp /boot/config-2.6.8-4-686-smp /home/kernel/linux-2.6.13/.config加入一个版本后缀
General setup ---> (hipac) Local version - append to kernel release
选中nf-HiPAC
Networking ---> Networking options --->
[*] Network packet filtering (replaces ipchains) --->
IP: Netfilter Configuration --->
<M> nf-HiPAC support (High Performance Packet Classification)
[*] Single path optimization
保存.config
1.4.编译内核
直接编译:cd /home/kernel/linux-2.6.13
make -j4
make modules_install
mkinitrd -o /boot/initrd.img-2.6.13hipac /lib/modules/2.6.13hipac
depmod -a 2.6.13hipac系统启动完成
1.5.执行命令
除了iptables换成nf-hipac之外没有任何别的区别,但是要注意,所有的iptables的match都被nf-hipac支持,但是并不意味着iptables的match可以内置到nf-hipac的dimtree中实现高效匹配,只有nf-hipac内置的match才可以实现高效dimtree匹配,这些match的共同特点就是它们的值域可以“区间化”。下面是一个nf-hipac支持的列表:Options:
--proto -p [!] proto protocol: by number or name, eg. `tcp‘
--source -s [!] address[/mask] or
address[:address]
source(s) specification
--destination -d [!] address[/mask] or
address[:address]
destination(s) specification
--in-interface -i [!] devname
network interface name
--jump -j target
target for rule
--numeric -n numeric output of addresses and ports
--out-interface -o [!] devname
network interface name
--verbose -v verbose mode
--line-numbers print line numbers when listing
[!] --fragment -f match second or further fragments only
--version -V print package version.
----------
TCP options:
--syn match when only SYN flag set
--not-syn match when not only SYN flag set
--source-port [!] port[:port]
--sport ...
match source port(s)
--destination-port [!] port[:port]
--dport ...
match destination port(s)
----------
UDP options:
--source-port [!] port[:port]
--sport ...
match source port(s)
--destination-port [!] port[:port]
--dport ...
match destination port(s)
----------
ICMP options:
--icmp-type typename match icmp type
(or numeric type or type/code)
see also: nf-hipac -h icmp
----------
STATE options:
--state [!] [INVALID|ESTABLISHED|NEW|RELATED|UNTRACKED|ESTABLISHED,RELATED]
State to match
----------
TTL options:
--ttl value[:value] match time to live value(s)
----------
如果nf-hipac命令中出现了iptables的match,比如从/lib/iptables目录加载的libipt_set.so中的ipset match以及任何iptables的match模块,最终都要排在dimtree的叶子节点进行独立的iptables匹配过程。代码里面已经很清晰的表明了这一点。nf-hipac的HOOK函数是hipac_match,该函数首先进行例行的高效的HiPAC算法匹配,然后找到一个叶子节点,该叶子节点可能体现出两种行为:
a.它就是纯粹的nf-hipac的rule,此时叶子指示一个target:
if (likely(IS_RULE(t))) {
return ((struct dt_rule *) t)->spec.action;
}/* initialization required to prevent compiler warning */
action = 0;
for (i = 0; i < ((struct dt_elem *) t)->ntm_rules.len; i++) {
rule = ((struct dt_elem *) t)->ntm_rules.p[i];
if (HAS_EXEC_MATCH(rule)) {
for (j = 0; j < rule->exec_match->len; j += 2) {
// 此处的match_fn就是常规的在一条iptables规则中遍历匹配所有的
// match,iptables中拥有很多不可区间化的match这是可以理解的
action = match_fn(packet,
rule->exec_match->p[j],
rule->exec_match->p[j + 1]);
if (action != MATCH_YES) {
break;
}
}
if (action == MATCH_NO) {
continue;
}
if (action == MATCH_HOTDROP) {
return TARGET_DROP;
}
...
}
}1.6.procfs中的统计信息
nf-hipac模块加载了之后,会在procfs的net目录下注册自己,其中的/proc/net/nf-hipac下的info文件中有下面一行:nf-hipac is invoked before iptables
如果你想让iptables首先进行匹配,那么请执行:
echo iptables-first> /proc/net/nf-hipac/info2.nf-hipac是怎么做到的
nf-hipac相比较iptables,性能那叫一个帅!相比ipset则不相上下,然而nf-hipac在综合效果上则是介于iptables和ipset之间的一个being。它是怎么做到的。iptables的规则在内存中是线性排列的,内核的HOOK通过遍历这些规则链进行逐一匹配,这个逐一匹配的顺序内含了优先级的概念,首先加入的rule首先被匹配到。但是除了这个顺序的排列之外,规则之间再也没有了别的关联,因此很难将它们作为一个整体来进行优化。
ipset将ip地址,端口等统一进行管理,但是同一个集合中的元素只能采取统一的动作,即target,虽然在ip地址的匹配中极端高效,但是使用起来很不灵活,很难做到比如同在set中的ip1和ip2执行不同的-j target动作。ipset是将单一的match统一管理进行优化的,和多条iptables规则没有必然的关系,即它没有将多条iptables规则关联起来。
除了傻傻的线性排列,除了单一match的hash/tree统一管理,iptables和match,target之间还能有别的关系吗?即它们之间还能有别的排列方式吗?当然有,这就是nf-hipac的方式。nf-hipac采用了另一种排列方式,即将固定的match进行排序,也就是说将每一条规则拆开来,这就就可以化不确定为确定。确定的是match的总的种类,不确定的是规则的数量,最终确定的match的数量决定了树的高度,而这个不确定的规则数量影响的仅仅是树的广度,仅此而已。
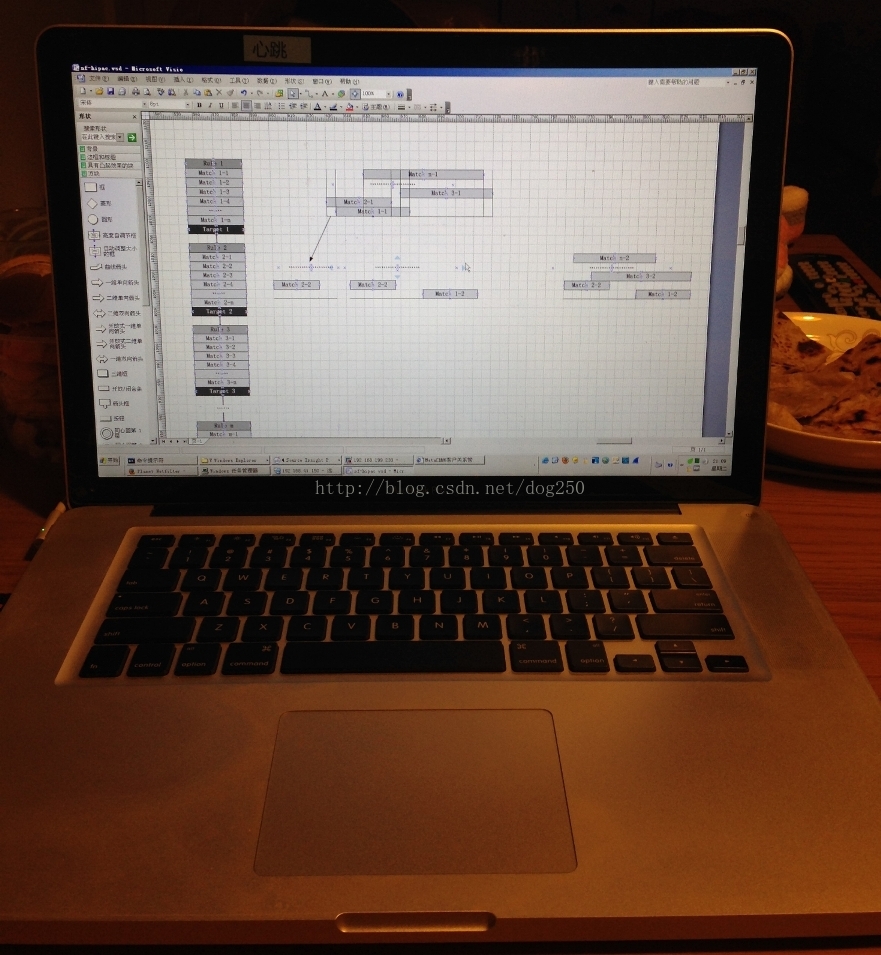
下面的一幅图非常复杂,是我听完嘉定中华国学后在我的餐桌上画的,已经很晚了,无所事事,睡不着,也没喝酒,所以就兴奋了。图示如下:
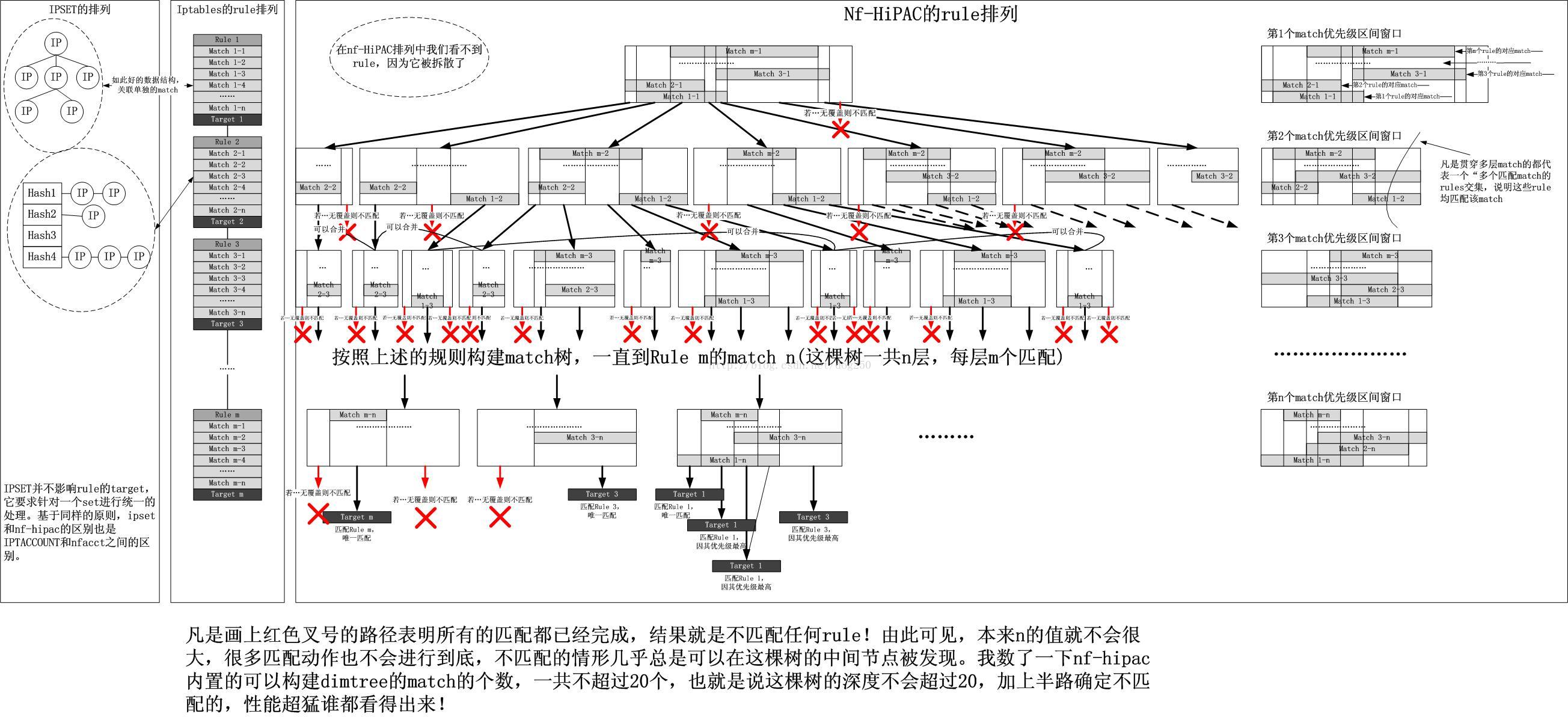
拆散了一条条的rule之后,剩下的就是将match和target组成一棵树了,事实上rule并没有被拆散,所谓的rule就是若干的match和一个target,在右边这棵树中体现的就是每一个树节点的match层次,最下层的优先级最高,这就体现了rule的配置顺序,rule的配置顺序体现的就是优先级。
nf-hipac不更新了,没人维护了,难道是作者因此找到好的工作了,难道是作者结婚了,难道是作者生孩子了...这种判断也太中国化了,反正就是不更新了...单单谈效率,ipset完全可以让nf-hipac下课,但是谈点别的之后,nf-hipac的优势就显现出来了。
3.破除超猛nf-hipac的神话
有破有立,方可不败。如果我们结合上面的图仔细分析为何添加了20000条左右的nf-hipac,性能依然不受任何影响,就会发现,nf-hipac的匹配过程最多经过n层的树深度,而n是match的数量,在这20000条规则中,match的数量只有1个!!注意了,这就是关键,1个!如果使用iptables,那么匹配的过程最多经过m个rule。也就是说,nf-hipac将m个rule拆散了之后,将其中所有的match压缩成了n层的树,每一层拥有m个层的区间交集匹配,这些交集仅仅决定其下层树节点的rule交集。照此说来,很多的数据包从第一个match集合(所有rule的第一个match组成的集合)树根开始匹配,一旦rule的match交集变成空,就可以直接下决断“没有匹配的rule”了,所以即便是少数种类的match集合节点,一个数据包也不一定能从树根匹配到最后一个match集合。这就是nf-hipac超猛的根本原因。
对于nf-hipac树的查找,需要注意的是,如果不是叶子节点,执行流只会碰触到最先配置的那条rule,即最下面的那条,其余的rule被隐藏在该最下面rule的上面,它们的作用仅仅是告诉执行流,该区间的下面的分支树节点是所有这些rule的交集,仅此而已。
从iptables到nf-hipac的变化是:从遍历m*n次(m为rule的数量,n为每一个rule的match的数量)简化为了遍历n次(n为所有rule中最多match的那一条rule的match的数量)。之所以如此就是因为nf-hipac将所有的rule作为一个整体来优化。那么代价是什么?代价就是插入rule,删除rule的开销。插入一条rule,首先需要将其所有的match拆分开来,然后找出每一个树节点的位置,即rule的插入位置,然后准备将这些match分别插入到那些位置中,是否插入取决于那个位置有没有对应rule的match交集,如果没有,则不予插入,删除的过程类似,也需要进行比较复杂的计算。
那么有没有什么办法让nf-hipac变得低效呢?很显然,当你了解了nf-hipac的dimtree的构造之后,你就会明白,n的数量越大,效率越低,n是什么?n是match的种类的数量。整个tree的深度就是n,如果自己构造20000种左右的match,那么试试看,仅仅配置一条nf-hipac规则,整个tree的构造将变成深度为2000的倒立的链表...我之所以仅仅设置一条nf-hipac规则是因为如果设置了多条,反而可能由于中途rule的match交集为空而提前退出遍历树。但是幸运的是,对于一个数据包那么多种的match是不必要的。
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow
以上是关于玩转高性能超猛防火墙nf-HiPAC的主要内容,如果未能解决你的问题,请参考以下文章