TCP BBR算法的带宽敏感性以及高丢包率下的优化
Posted ksiwnhiwhs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP BBR算法的带宽敏感性以及高丢包率下的优化相关的知识,希望对你有一定的参考价值。
bbr算法比较简单也比较容易理解,所有关于它的优化也就同样不复杂了。
请注意,任何优化都只针对特定场景的,根本不存在一种放任四海而皆准的算法。我们分析Google的测试报告时,比较容易被忽视的是其bbr算法的部署场景。如果可以完美复现Google的B4网络,那么测试结果应该就跟Google是一致的,但不得不说,bbr算法内置了很多的参数(目前的版本中是写死的),Google方面有没有调整这些参数是未知的。我们先看一下bbr算法是怎么利用空余带宽的。
bbr算法最终会稳定在Steady-state,即其PROBE_BW的状态,该状态内置了一个小循环,bbr在这个循环中不停运转:
1.正增益周期,是否在不丢包情况下已经填满了可用带宽,这个旨在提高资源利用率(效率因素);
2.减损周期内,是否已经腾出了部分可以资源,这个旨在满足公平性(公平因素);
3.平稳反馈周期是否足够久,使得共享资源的TCP连接有时间收敛到一个公平的位置(公平因素)。
这是个典型的效率优先兼顾公平的实例,但是我们可以看到,如果上述的第三点,即平稳反馈周期太久会怎样?很显然,这样的话会降低bbr的抢占性和灵活性,bbr发现带宽富余的最短时间就是6个RTT,这对于某些场景而言显然是不足的。因此,我们可以得出第一个结论:
PROBE_BW状态中平稳反馈周期的长度决定了bbr抢占敏感性。
一个最简单且极端的例子,如果我们将bbr在PROBE_BW的pacing gain数组改成下面这个样子,其将会第一时间发现带宽富余,然则代价就是发送速率的颠簸,这对下载业务是好的,但是并不利于直播点播业务:
接下来我们来看第二个话题,那就是bbr的崖点在哪?
我们知道,Reno/CUBIC直接在膝点出采取措施,使得拥塞得以避免,即便是持续保持慢速,也不会到达崖点,Reno/CUBIC将丢包作为到达膝点的标志,然后退出拥塞控制算法,进入拥塞恢复阶段,直到拥塞被认为缓解恢复正常,是不会把控制权再度交给拥塞控制算法的。这也是经典的拥塞控制风格作风,本质就是在膝点采取措施,避免从崖点跌落,这便是经典的锯齿之由来!锯齿尖的位置,那是膝点,而不是崖点!
那么bbr是不是也类似呢?非也!因为bbr不会被接管,bbr自己全程负责所有的拥塞处理!事实上,bbr根本不管什么拥塞不拥塞,它只是单纯的根据自己收到的带宽反馈来计算下面发送的带宽,即便真的发生了拥塞,不也还是可以发送数据的么,只是发送的可能是重传数据而不是新数据而已。
我们来看一张来自Google的bbr测试结果图示:
所以,我一般而言会尽力避开这种争论,无论任何方面,即便我知道的再多,我也会争取做一名沉默的人。
我直接给出答案吧,崖点的存在,正是因为bbr_pacing_gain数组的固定配置。
崖点的存在是一种”资不抵债“的退避措施!我们看到在bbr_pacing_gain数组中,其增益元素的增益比是1/4,也就是25%,可以简单理解为,在增益周期,bbr可以多发送25%的数据!
注意看上面的图的横轴丢包率,当丢包率接近25%的时候,曲线从崖点跌落,这并不是偶然的!过程很容易理解,首先,在增益期,x%的丢包率是否抵消了增益比25%?也就是说,x是否大于25。
我们假设x就是25!那么可想而知,25%的收益完全被25%的丢包所抵消,相当于没有收益,接下来的减损周期,又减少了25%的发送数据,同时丢包率依然是25%...再接下来的6个RTT,持续保持25%的丢包率,而发送率却仅仅基于反馈,即每次递减25%,我们可以看到,在bbr_pacing_gain标识的所有8周期,数据的发送量是只减不增的,并且会一直持续下去,这就是崖点!
以上我的假设是x就是25,事实上,丢包率在不足25%的时候,以上的减损现象就已经开始呈现了,在Google的测试中,我们发现从5%的丢包率开始,持续到10%左右的丢包率,然后到15%~20%丢包率的时候,吞吐率持续下跌,一直跌到底。我们可以看到,在bbr_pacing_gain数组中,除了bbr_pacing_gain[0]表示增益之外,在有丢包的情况下,其它的都是减损,特别在高丢包率(我一向觉得5%以上就是很高丢包率了)下更是明显。
好了,我们把上述的论述总结在一个图示上:
1.bbr_pacing_gain数组的bbr_pacing_gain[0]系数(当前是5/4),决定了抗丢包能力;
2.bbr_pacing_gain数组中系数为1(即平稳反馈周期)的元素的多少,决定了抗丢包能力(太久,则会持续衰减,太短,则比较颠簸)。
我们从Google的bbr部署说明里也可以看出:
CUBIC’s loss tolerance is a structural property of the algorithm, while BBR’s is a configuration parameter.
As BBR’s loss rate approaches the ProbeBW peak gain, the probability of measuring a delivery rate of the true BtlBw
drops sharply, causing the max filter to underestimate.
其中为什么会”causing the max filter to underestimate“呢?因为max filter是基于时间窗口的,随着时间的流逝,bbr会忘掉之前的大带宽,只记着现在由于丢包持续减少的小带宽。你要注意,其实只要有丢包,在6个平稳反馈周期内,带宽就是持续减少的,然而,问题是,这些减少的量能不能通过增益周期,即bbr_pacing_gain[0]的收益一次性补偿,如果不能,那么跌入崖点就是必然的。
因此,拿什么来抵抗丢包呢?答案是损失一点公平性,用增益系数去换!我把5/4换成了3/2,效果良好,大概到丢包率30%以后才跌入崖点,要知道30%的丢包率,可用性几乎已经可以说是零了!另外,我为什么不减少bbr_pacing_gain数组中增益系数为1的元素的数量呢?因为这会严重影响公平性!所以我保持其8个元素。
这是bbr不如CUBIC的地方,bbr事实上完全基于反馈,正常来讲按照VJ的数据守恒规则,一个包离开另一个方可进入的情况下,丢包率本身就会持续拉低带宽,bbr有一个5/4的增益,这可能会弥补丢包带来的反馈减损,然而增益系数5/4却是一个配置参数,当丢包率大于25%的时候,就会资不抵债!甚至丢包率在10%~15%的时候,bbr的表现就开始不佳。因此,如果能动态计算丢包率,然后将丢包率反馈给增益系数,动态计算增益系数,我想效果应该会不错。比如丢包率达到25%的时候,增益系数就变成50%,这样就可以避免由于丢包带来的反馈减损,然而,你又如何判断这些丢包是噪声丢包还是拥塞丢包呢?答案在于RTT!只要时间窗口内的RTT不增加,那么丢包就不是拥塞导致的,感谢Gail & Kleinrock给出的模型,感谢Yuchung Cheng & Neal Cardwell证明了这是对的。
顺便说一句,由于CUBIC的表现就是填满所有可以填满的缓存,它们的行为是可怕的,要不是CUBIC还遵循着乘性减窗(只是减到了原来的0.7而不是0.5),网络估计早就崩溃了,即便如此,如果不是因为大量的TCP接收端限制了接收窗口,网络也是要被CUBIC搞崩溃的。现如今,有将近30%~50%的接收端通告了一个比CUBIC计算出来的更小的窗口,感谢这些接收端,使得我们免受CUBIC Flood的危害!
请注意,任何优化都只针对特定场景的,根本不存在一种放任四海而皆准的算法。我们分析Google的测试报告时,比较容易被忽视的是其bbr算法的部署场景。如果可以完美复现Google的B4网络,那么测试结果应该就跟Google是一致的,但不得不说,bbr算法内置了很多的参数(目前的版本中是写死的),Google方面有没有调整这些参数是未知的。我们先看一下bbr算法是怎么利用空余带宽的。
bbr算法最终会稳定在Steady-state,即其PROBE_BW的状态,该状态内置了一个小循环,bbr在这个循环中不停运转:
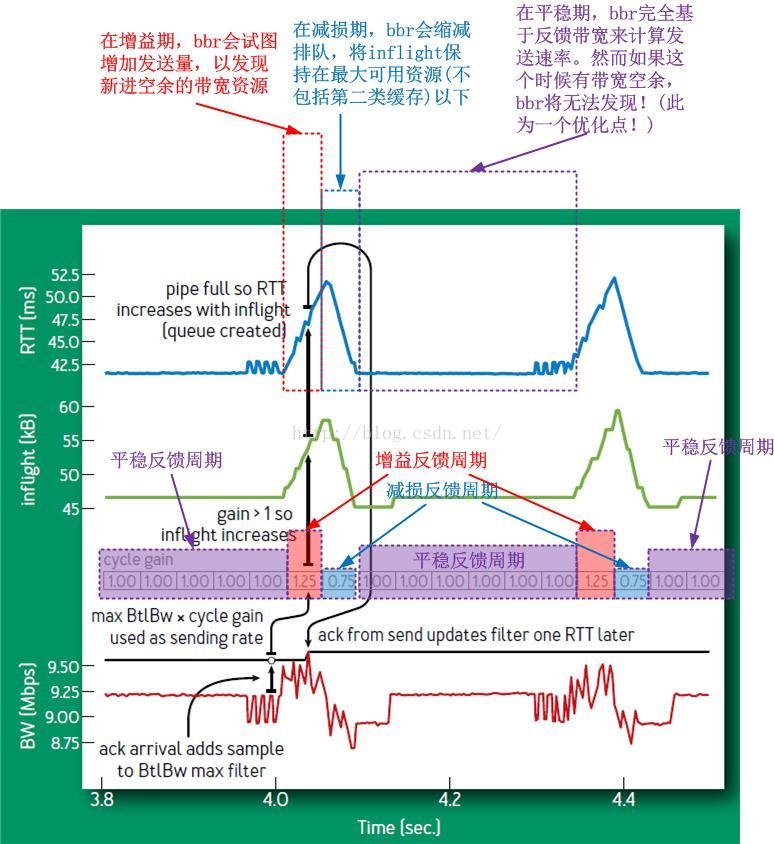
注意其中的速率增益:1|1|1|1|1|1|1.25|0.75|1|1|1|1|1|1|1.25|0.75|1|...这个循环增益完全是bbr自主的循环增益,不受任何外界控制,是否进入下一个增益取决于以下的判断:
1.正增益周期,是否在不丢包情况下已经填满了可用带宽,这个旨在提高资源利用率(效率因素);
2.减损周期内,是否已经腾出了部分可以资源,这个旨在满足公平性(公平因素);
3.平稳反馈周期是否足够久,使得共享资源的TCP连接有时间收敛到一个公平的位置(公平因素)。
这是个典型的效率优先兼顾公平的实例,但是我们可以看到,如果上述的第三点,即平稳反馈周期太久会怎样?很显然,这样的话会降低bbr的抢占性和灵活性,bbr发现带宽富余的最短时间就是6个RTT,这对于某些场景而言显然是不足的。因此,我们可以得出第一个结论:
PROBE_BW状态中平稳反馈周期的长度决定了bbr抢占敏感性。
一个最简单且极端的例子,如果我们将bbr在PROBE_BW的pacing gain数组改成下面这个样子,其将会第一时间发现带宽富余,然则代价就是发送速率的颠簸,这对下载业务是好的,但是并不利于直播点播业务:
// 将8个元素的数组改成2个元素的数组,是的bbr在Steady-state处于颠簸徘徊状态。
static const int bbr_pacing_gain[2] = {
BBR_UNIT * 5 / 4, /* probe for more available bw 油门*/
BBR_UNIT * 3 / 4, /* drain queue and/or yield bw to other flows 刹车*/
// BBR_UNIT, BBR_UNIT, BBR_UNIT, /* cruise at 1.0*bw to utilize pipe, */
// BBR_UNIT, BBR_UNIT, BBR_UNIT /* without creating excess queue... */
};接下来我们来看第二个话题,那就是bbr的崖点在哪?
我们知道,Reno/CUBIC直接在膝点出采取措施,使得拥塞得以避免,即便是持续保持慢速,也不会到达崖点,Reno/CUBIC将丢包作为到达膝点的标志,然后退出拥塞控制算法,进入拥塞恢复阶段,直到拥塞被认为缓解恢复正常,是不会把控制权再度交给拥塞控制算法的。这也是经典的拥塞控制风格作风,本质就是在膝点采取措施,避免从崖点跌落,这便是经典的锯齿之由来!锯齿尖的位置,那是膝点,而不是崖点!
那么bbr是不是也类似呢?非也!因为bbr不会被接管,bbr自己全程负责所有的拥塞处理!事实上,bbr根本不管什么拥塞不拥塞,它只是单纯的根据自己收到的带宽反馈来计算下面发送的带宽,即便真的发生了拥塞,不也还是可以发送数据的么,只是发送的可能是重传数据而不是新数据而已。
我们来看一张来自Google的bbr测试结果图示:
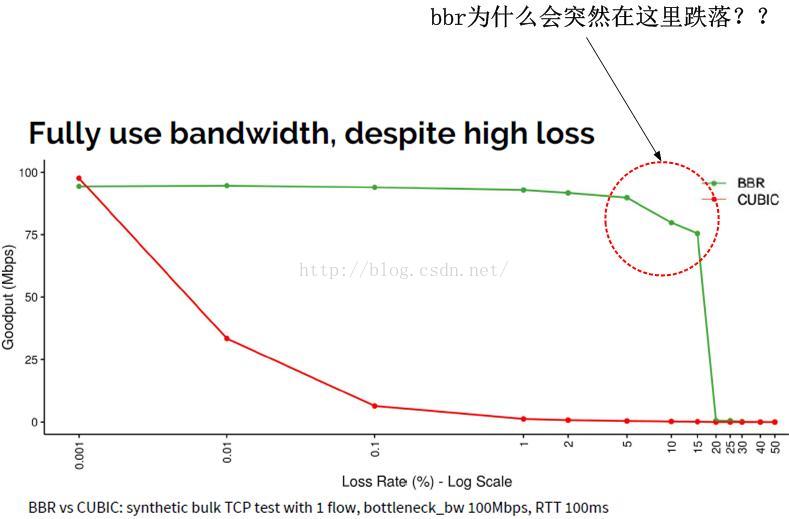
问题我已经标在上面了,为什么bbr会面临一个崖点,此后完全不可恢复!虽然CUBIC最终也是归于同一结局,但是它是按比例滑落的,而不像bbr那样跌落一般。这个怎么解释呢?这个问题有同事和坛子里的都问过我,但我并没有给出正面回答,因为我觉得我们自己很难模拟真实的丢包环境。第一,我们没有模拟任意丢包率的独立仪器(丢包不受TCP发送量的影响,就算只发一个包,该丢也得丢),我们所谓的丢包几乎都是由于我们自己造成的,是我们自己的TCP造成的,其次,能认识到第一点事实的人很少,明白现有Linux TCP拥塞状态机逻辑和拥塞控制算法逻辑关系的人更少。这样一来如果测出的结果没有发现崖点,那便是无休止的毫无意义的争论。无神论者永远都只能是个什么什么者,那只是它们自己相信没有神,让他们去说服基督徒,那是会被打死的,虽然,基督徒也不能证明有神!
所以,我一般而言会尽力避开这种争论,无论任何方面,即便我知道的再多,我也会争取做一名沉默的人。
我直接给出答案吧,崖点的存在,正是因为bbr_pacing_gain数组的固定配置。
崖点的存在是一种”资不抵债“的退避措施!我们看到在bbr_pacing_gain数组中,其增益元素的增益比是1/4,也就是25%,可以简单理解为,在增益周期,bbr可以多发送25%的数据!
注意看上面的图的横轴丢包率,当丢包率接近25%的时候,曲线从崖点跌落,这并不是偶然的!过程很容易理解,首先,在增益期,x%的丢包率是否抵消了增益比25%?也就是说,x是否大于25。
我们假设x就是25!那么可想而知,25%的收益完全被25%的丢包所抵消,相当于没有收益,接下来的减损周期,又减少了25%的发送数据,同时丢包率依然是25%...再接下来的6个RTT,持续保持25%的丢包率,而发送率却仅仅基于反馈,即每次递减25%,我们可以看到,在bbr_pacing_gain标识的所有8周期,数据的发送量是只减不增的,并且会一直持续下去,这就是崖点!
以上我的假设是x就是25,事实上,丢包率在不足25%的时候,以上的减损现象就已经开始呈现了,在Google的测试中,我们发现从5%的丢包率开始,持续到10%左右的丢包率,然后到15%~20%丢包率的时候,吞吐率持续下跌,一直跌到底。我们可以看到,在bbr_pacing_gain数组中,除了bbr_pacing_gain[0]表示增益之外,在有丢包的情况下,其它的都是减损,特别在高丢包率(我一向觉得5%以上就是很高丢包率了)下更是明显。
好了,我们把上述的论述总结在一个图示上:
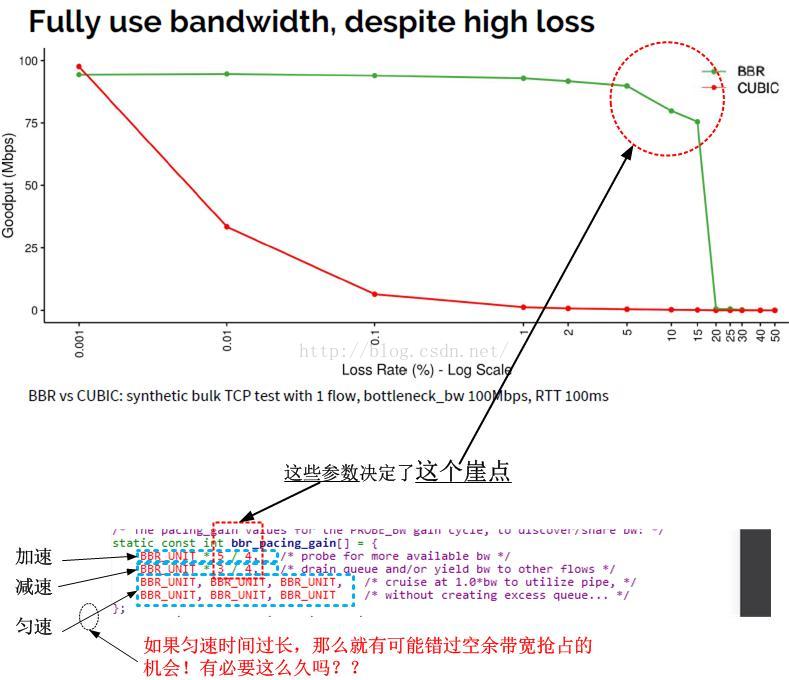
然后我们得到的新结论是:
1.bbr_pacing_gain数组的bbr_pacing_gain[0]系数(当前是5/4),决定了抗丢包能力;
2.bbr_pacing_gain数组中系数为1(即平稳反馈周期)的元素的多少,决定了抗丢包能力(太久,则会持续衰减,太短,则比较颠簸)。
我们从Google的bbr部署说明里也可以看出:
CUBIC’s loss tolerance is a structural property of the algorithm, while BBR’s is a configuration parameter.
As BBR’s loss rate approaches the ProbeBW peak gain, the probability of measuring a delivery rate of the true BtlBw
drops sharply, causing the max filter to underestimate.
其中为什么会”causing the max filter to underestimate“呢?因为max filter是基于时间窗口的,随着时间的流逝,bbr会忘掉之前的大带宽,只记着现在由于丢包持续减少的小带宽。你要注意,其实只要有丢包,在6个平稳反馈周期内,带宽就是持续减少的,然而,问题是,这些减少的量能不能通过增益周期,即bbr_pacing_gain[0]的收益一次性补偿,如果不能,那么跌入崖点就是必然的。
因此,拿什么来抵抗丢包呢?答案是损失一点公平性,用增益系数去换!我把5/4换成了3/2,效果良好,大概到丢包率30%以后才跌入崖点,要知道30%的丢包率,可用性几乎已经可以说是零了!另外,我为什么不减少bbr_pacing_gain数组中增益系数为1的元素的数量呢?因为这会严重影响公平性!所以我保持其8个元素。
这是bbr不如CUBIC的地方,bbr事实上完全基于反馈,正常来讲按照VJ的数据守恒规则,一个包离开另一个方可进入的情况下,丢包率本身就会持续拉低带宽,bbr有一个5/4的增益,这可能会弥补丢包带来的反馈减损,然而增益系数5/4却是一个配置参数,当丢包率大于25%的时候,就会资不抵债!甚至丢包率在10%~15%的时候,bbr的表现就开始不佳。因此,如果能动态计算丢包率,然后将丢包率反馈给增益系数,动态计算增益系数,我想效果应该会不错。比如丢包率达到25%的时候,增益系数就变成50%,这样就可以避免由于丢包带来的反馈减损,然而,你又如何判断这些丢包是噪声丢包还是拥塞丢包呢?答案在于RTT!只要时间窗口内的RTT不增加,那么丢包就不是拥塞导致的,感谢Gail & Kleinrock给出的模型,感谢Yuchung Cheng & Neal Cardwell证明了这是对的。
顺便说一句,由于CUBIC的表现就是填满所有可以填满的缓存,它们的行为是可怕的,要不是CUBIC还遵循着乘性减窗(只是减到了原来的0.7而不是0.5),网络估计早就崩溃了,即便如此,如果不是因为大量的TCP接收端限制了接收窗口,网络也是要被CUBIC搞崩溃的。现如今,有将近30%~50%的接收端通告了一个比CUBIC计算出来的更小的窗口,感谢这些接收端,使得我们免受CUBIC Flood的危害!
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow
以上是关于TCP BBR算法的带宽敏感性以及高丢包率下的优化的主要内容,如果未能解决你的问题,请参考以下文章