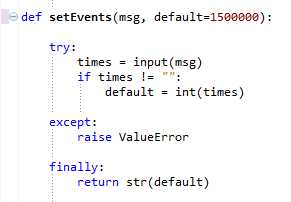
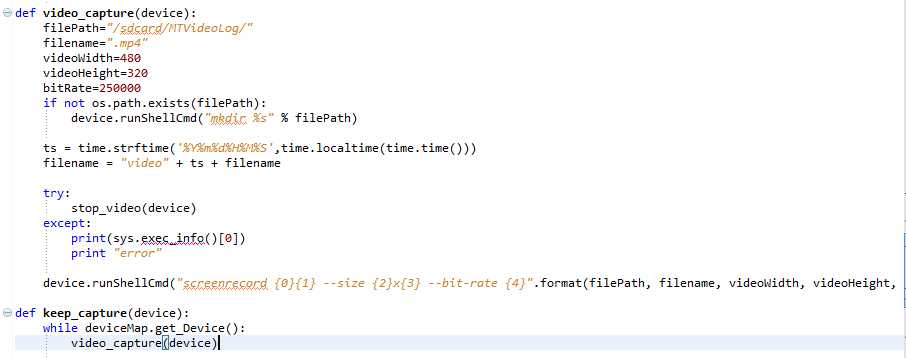
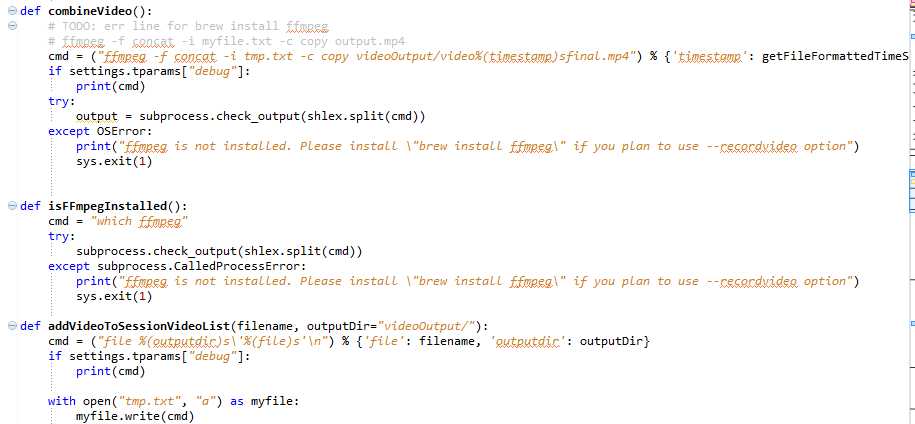
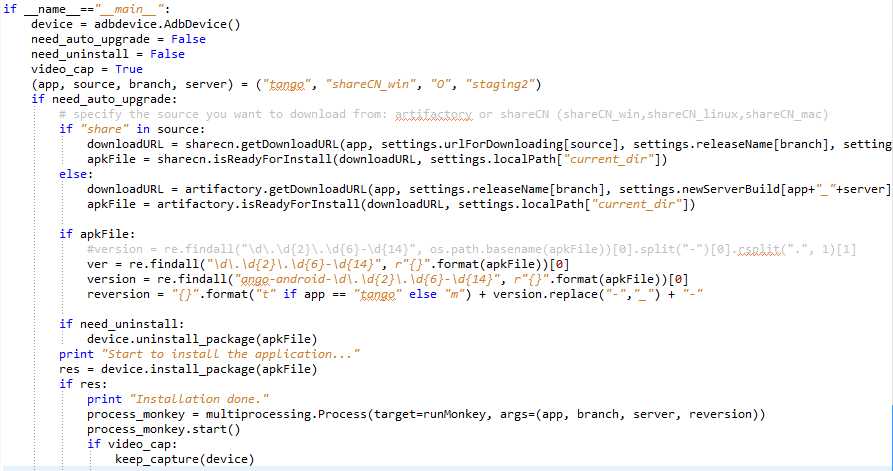
自此,autoMonkey原生的部分就已经介绍完毕了,相对于改进的autoMonkey部分,基本上跟上面的逻辑是一样的,只是涉及到monkey.jar文件的处理以及这个jar文件支持的参数上面有些细微的不同,这里就不一一赘述了。
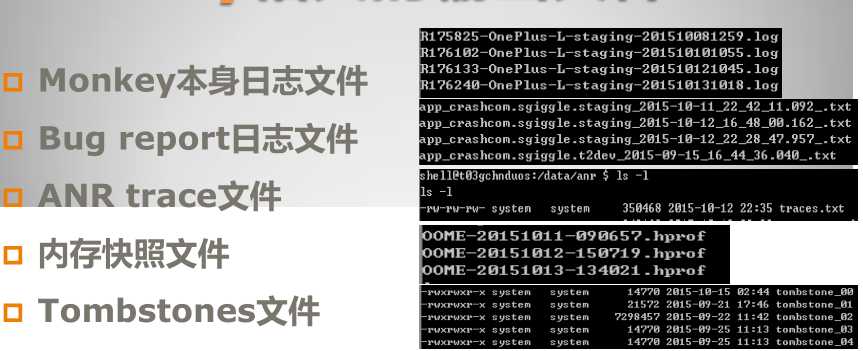
其中Monkey本身的日志文件才是我们重点需要去分析处理的日志,下方的都是单个崩溃或者ANR生成的日志,必要时,我们将这些日志和Monkey本身日志打包后上传到对应的问题单中即可。对于Monkey日志的解析,主要分两方面:
文件名称方面
通过文件名,我们可以得到svn版本号,测试机型号(后来改成序列号了),分支(即版本),测试包的环境(测试环境,预发环境,线上环境等)

文件内容方面
通过文件内容,我们可以得到日志中的Crash/ANR,测试时长,启动的Activity等等,下面分别阐述。
一、Crash
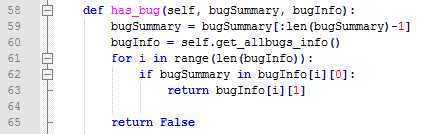
对于Crash和ANR的解析是分析Monkey日志最核心的部分,,我们需要知道一份日志中到底有多少个崩溃或者无响应,然后将这些发现的问题跟我们的bug系统Jira对接处理。大概的难点有两个:第一是如何解析出所有的Crash,解析后应该保存什么内容,第二是如何去重。基本思路如下:
a、读文件(Monkey本身的日志文件)
b、解析出所有的崩溃堆栈
输入:a中的Monkey日志文件
输出:一个堆栈列表crashList,列表里每个元素就是具体的堆栈信息
c、对于每个堆栈提取出一个可以代表这个crash的描述信息
输入1:b中的堆栈列表crashList中的每一个crash堆栈
输出1:一个元组,包含summary和attachFile两部分
输入2:完整的crashList
输出2:按照输入1->输出1的方法,遍历crashList,输出一个列表,该列表每个元素包含summary,attachFile和完整的堆栈三部分
d、去重
输入:c生成的新的列表
输出:最终需要的列表,其中每个元素包含四部分,summary,attachFile,次数和具体的堆栈
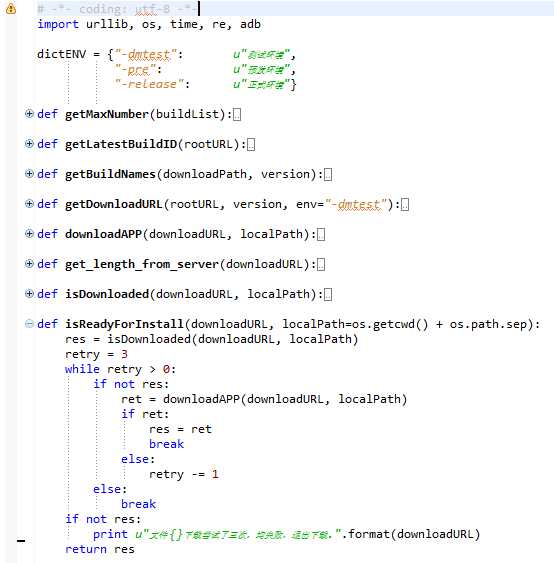
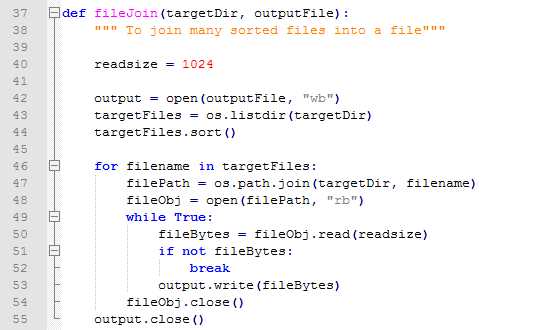
读文件部分,这个没什么好说的,我们在运行Monkey的时候将日志存到了手机中,解析的时候将这日志导入到pc即可,这部分其实也是自动导入的,下面将日志处理的时候会讲到,这里就先不细讲了。
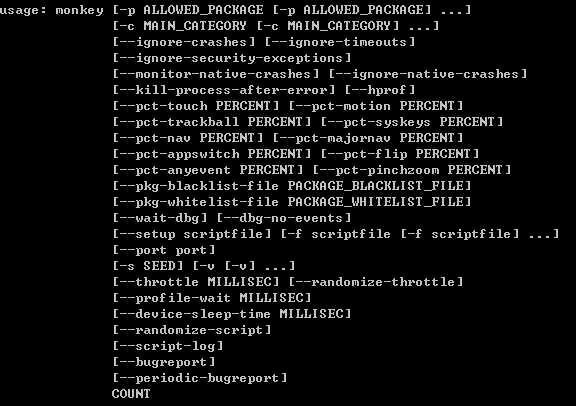
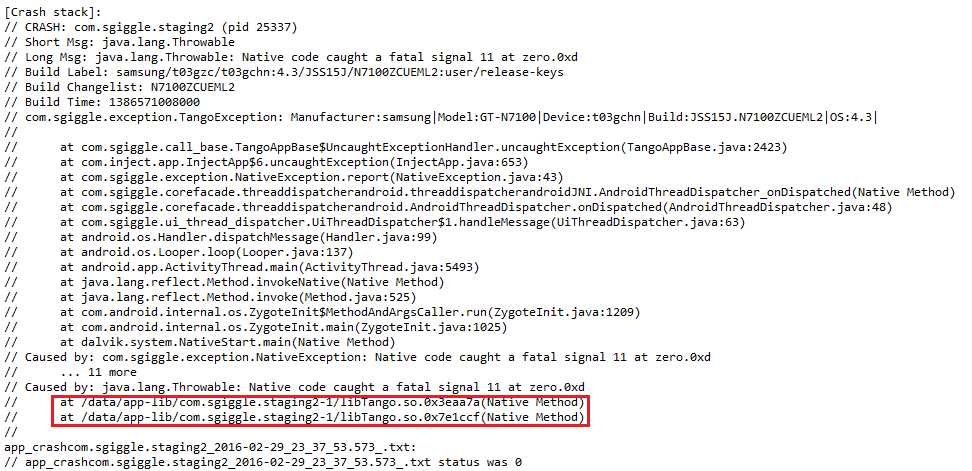
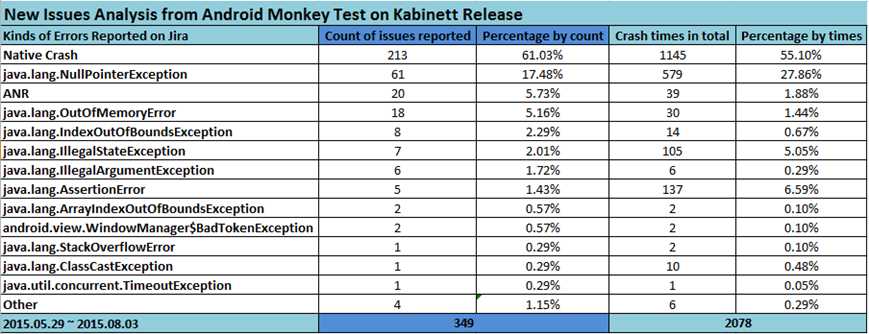
Crash发生时,Monkey日志中会有日志打印,我们可以通过关键字“Crash”来发现,但我们是针对某个特定的app来跑的,所以在检索崩溃关键字的时候,需要加上App的名字,这样可以过滤掉那些非测试app的崩溃,比如系统UI的,输入法之类的,像我之前的项目,App的名字就是com.sgiggle.xxx(xxx是对应的环境,当时我们有10+的dev环境,2个staging环境和1个production环境,也基本上对应了测试环境,预发环境和生产环境),我们需要做的就是将一份日志中所有的Crash堆栈都找出来。其实Monkey日志堆栈的部分是由规律的,以“// CRASH”开头,下面的堆栈也都是以"/"开头的,最后一般是个换行符,所以主逻辑就是匹配这样的行就行了,只是需要考虑几种情况:
- bugreport生成的2行包含有时间戳的日志行,都是以app_crash开头的;
- 有的堆栈特别长(最长的超过300行),所以需要限定最大的行数,一般180足以;
- 有的时候app比较脆弱,一个堆栈还没打印完毕又来一个崩溃,所以需要限定我们截出来的堆栈信息中只包含一个崩溃,因此往下遍历的时候需要判断是否以“// CRASH”开头和"// NOT RESPONDING”开头的。
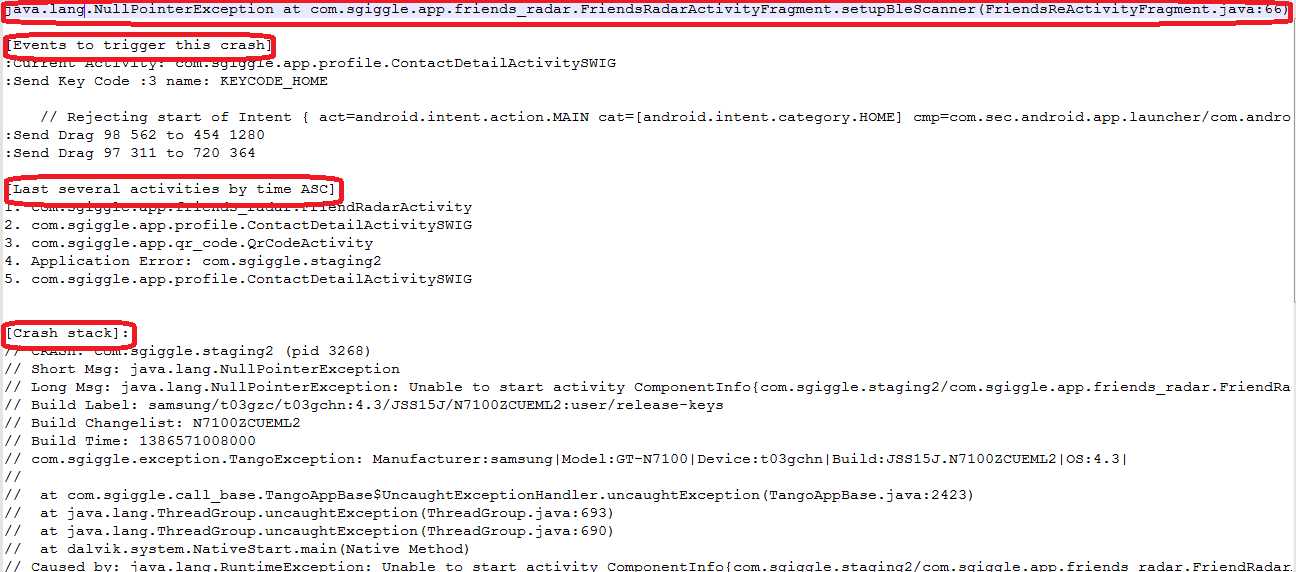
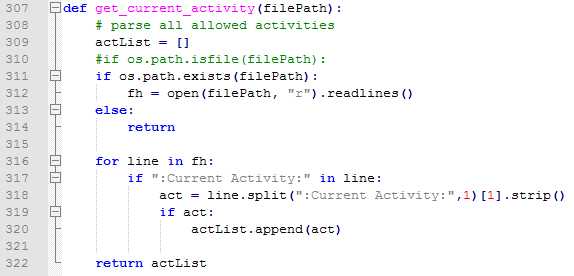
这是最早的一个版本,后来基于此,我在解析日志的时候,加入了另外两个功能:崩溃之前的几个activity和引起崩溃的事件。这两个功能都需要解析崩溃之前的日志,崩溃堆栈是"//CRASH"之后取的180行,崩溃之前的信息我则是取的这行之前的180行。引起崩溃的事件这个好办,180行日志逆序查找,得到最后一个":Current Activity",然后从中解析出具体是哪个activity名字即可;而崩溃之前的几个activity,方法基本上跟之前一样,就是按":Current Activity"查找然后解析,解析后放到一个列表中,最后按照我们需要的数量输出几个,我这里统计的是5个,所以只取倒数5个即可,如果需要更多,把这个数字改大些就行了,对应的则可能需要将倒数的行数写大一些,避免这180行里没有你想要的那么多activity,不过对于我之前的测试App来说,最后5个已经足以。
就这样,一个完整的堆栈就能拿到,遍历文件之后,该文件中所有的崩溃堆栈就全部拿到了,存到一个列表中,我们再对每个堆栈进行分析即可。下面贴出这部分的代码:
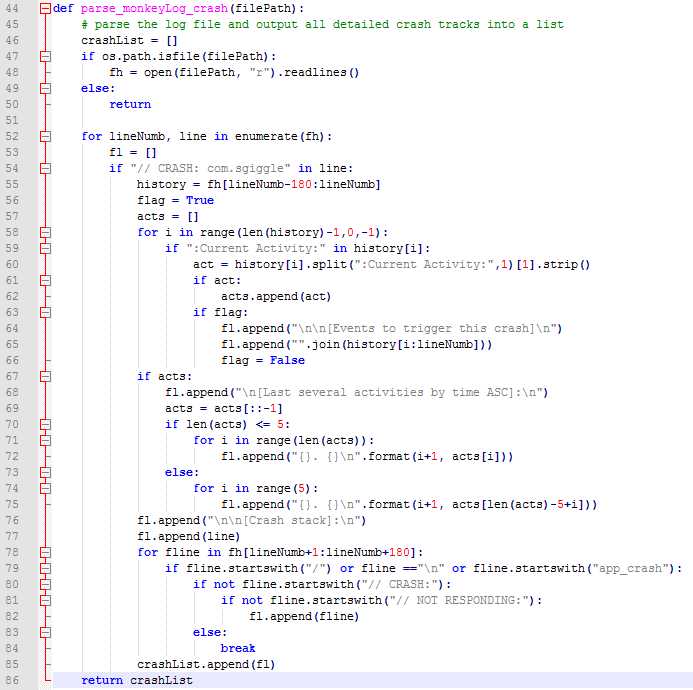
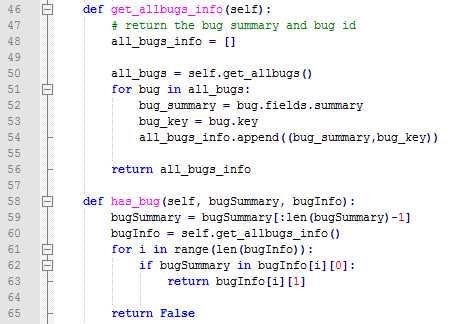
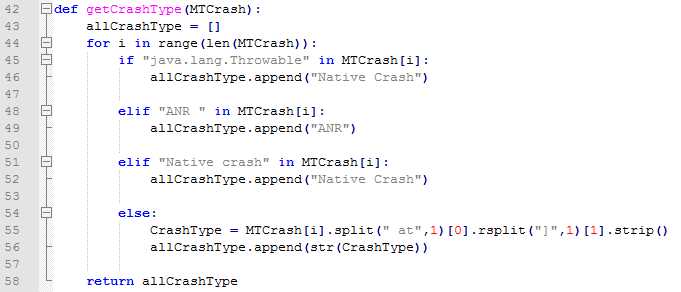
我们拿到一份日志中所有的崩溃堆栈后,需要对这些堆栈进行统一处理,目的主要由两个:一是我们需要本地去重,以减少后面和jira的交互次数;二是我们需要知道这些堆栈是否已经处理过了。按照之前的逻辑,一个堆栈里差不多几十行到180行不等,于是我想到了这样的一个方法:对于每个堆栈,我按照崩溃类型+at+崩溃的代码行来提取出一个summary出来,而这个summary又正好可以作为jira中提交问题单的描述,需要注意的几个地方:
1、崩溃的类型:从"Short Msg"中可以拿到,然后解析出即可
2、崩溃的代码行:从"Caused by"中拿到,但这个就略微复杂些,大概分两种情况,堆栈里有测试App代码的和堆栈里没有测试App代码。后者比较简单,既然没有测试App的代码,那我就取第一行,对于有测试App代码行的,那我就去取堆栈里包含有测试App代码的第一行
3、堆栈里没有测试App代码行的,这部分很大程度上是系统的一些API或者代码,这些代码的行号不像App代码那样,同样的一段代码他们在不同手机上行号很有可能就不一样,所以对于这种情况我就去掉了行号
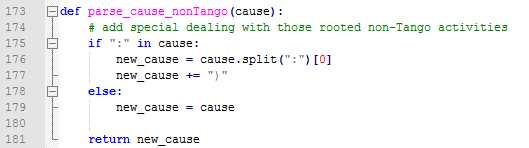
4、一个堆栈里有可能有多个"Caused by",所以我这里加了个flag来做判断,不然的话代码只会去查找最后一个
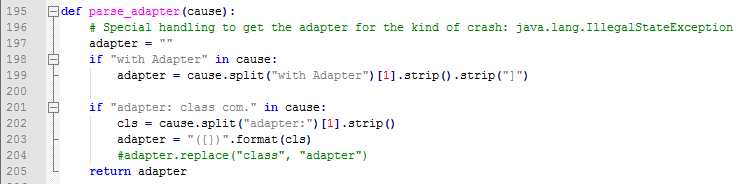
5、对于"java.lang.IllegalStateException"这种崩溃,实际测试发现,很多时候通过上面的方法生产的summary都一样,最后仔细对比了堆栈,发现其中出问题的adapter不一样,所以最好针对这类的问题在生成summary的逻辑上再加入了adapter的解析。
6、堆栈里有该崩溃发生时候的系统日志:上面也有提到,2行以"app_crash"开头的日志,我们需要解析出完整的文件名,后续的话就可以直接从手机中自动导出这个日志并和Monkey本身日志合并压缩打包了。

考虑到上面的几种情况,最后的堆栈解析部分代码如下,每个堆栈输出解析好的summary和attachFile:
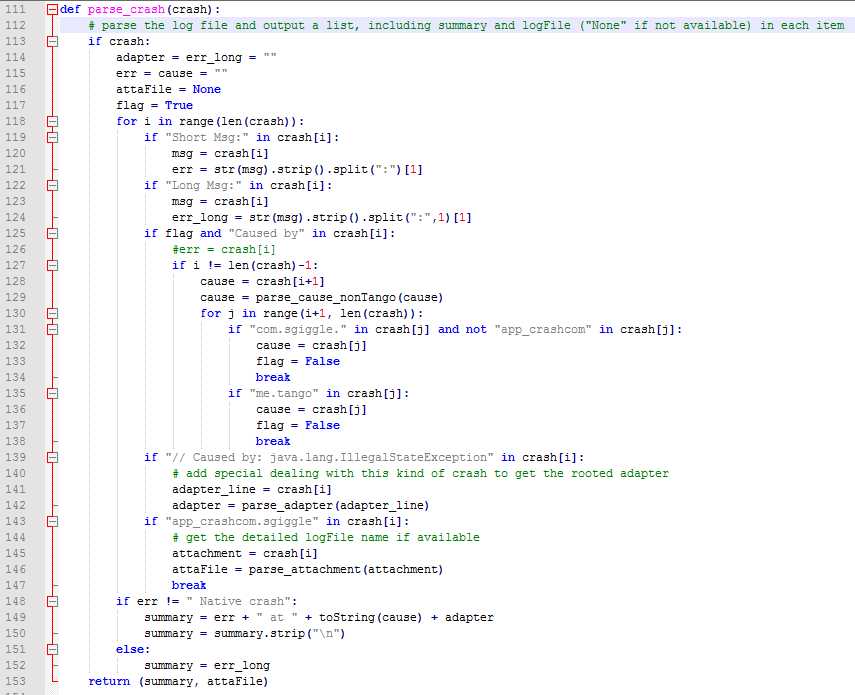
然后遍历crashList,每个crash堆栈生成的包含summary和attachFile元组放到一个list中,加上原本的堆栈,于是就得到了一个每个列表元素包含三部分内容的新的列表:

最后一步就是去重的工作。很明显,我们只需要按照summary来做对比即可,而且在对比的同时,我们可以直接得到去重后的summary的次数(可以直接用内置的count方法),于是一个全新的也是我们最后要用到的包含有我们所需要的全部信息的列表就得到了,这个列表的每个元素包含了4部分,即:崩溃的描述文件summary,具体的崩溃日志文件attachFile,该崩溃的次数和该崩溃详细的堆栈信息。去重的代码如下:
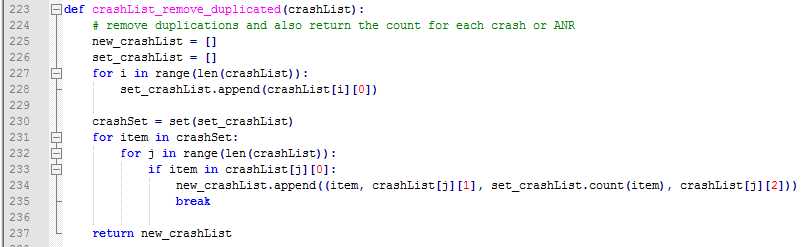
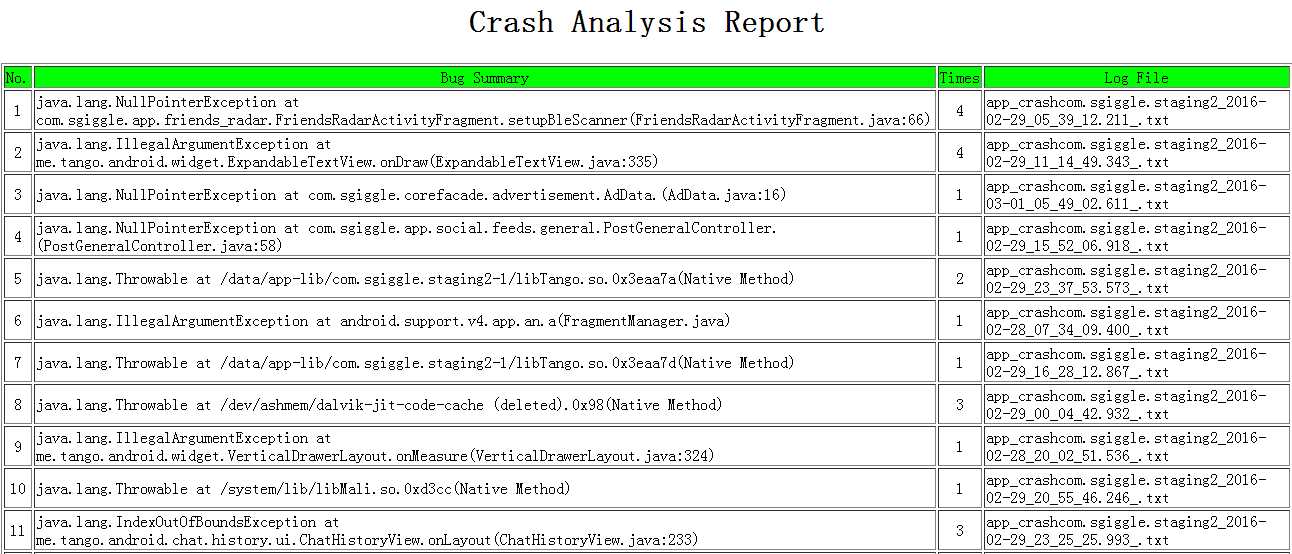
为了给大家看的更清楚,我把一份Monkye日志解析出来的信息前三部分生成了一个
html文档,具体的堆栈部分也打印了下,可以直接参考:
1、前三部分(summary,次数和attachFile)

补充:python可以用pyh这个module来生成html文档,具体的说明部分可以参考官方文档:http://code.google.com/p/pyh/wiki/UserManual。关于这部分的代码,我也贴出来了,大家可以看看,以方便在别的地方也可以用得上。关于html样式部分,我们可以用css来做,更具体的这里不是重点,所以就不深了讲这块了,代码如下:
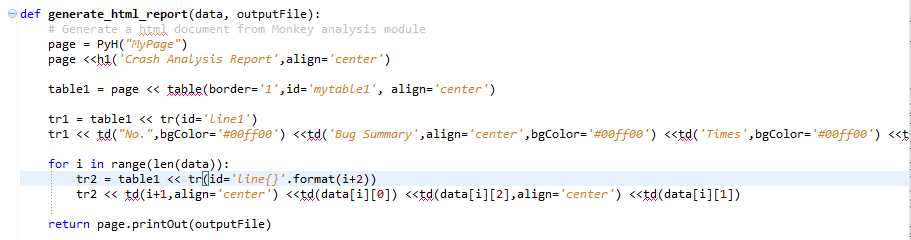
2、最后一部分(详细的堆栈信息,description)
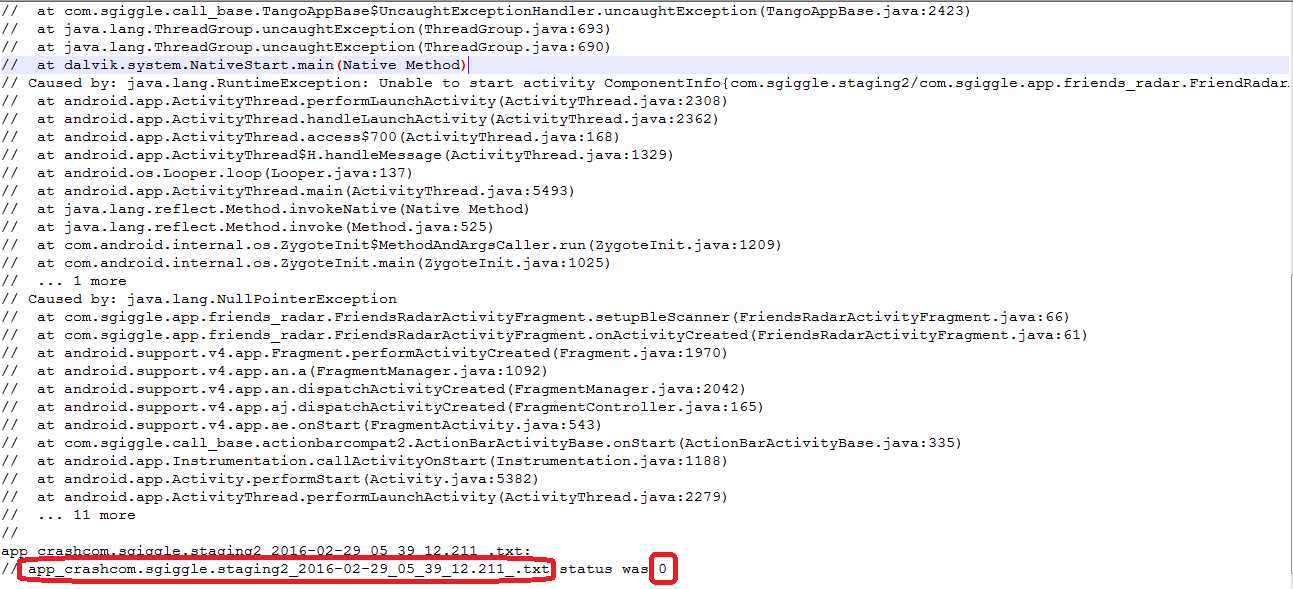
自此,一份Monkey运行产生的日志文件中的崩溃就全部解析完毕了,一个文件到一个列表,这就是这部分的核心内容,另外需要提一下,长时间的Monkey可能会产生大容量的日志文件,如果遇到这种情况,我们需要按照一定大小分割文件后再行处理,一来是太大的文件很容易引起解析脚本的性能甚至错误,二来太大的文件也不方便上传。如下是分割大文件的代码:
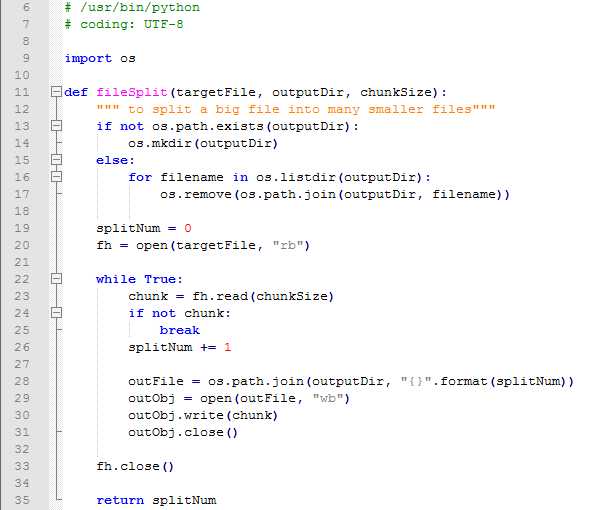
既然有了分割文件,自然也有了合并文件:
二、ANR
ANR的部分跟Crash部分处理流程上差不多,我们也是按照提取summary的思路来处理ANR的,详细的就不一一细说了,只说和Crash不同的几个地方:
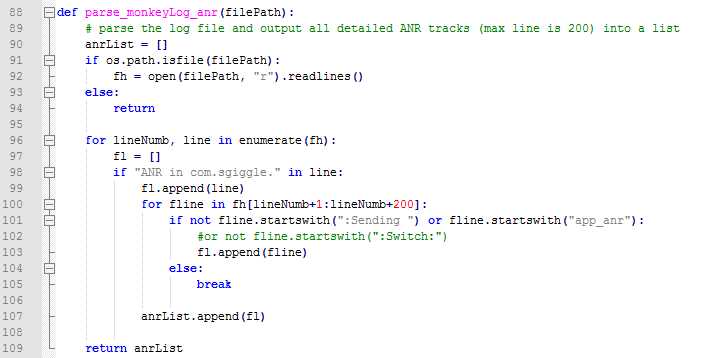
1、ANR的堆栈一般比较长,我之前取的是200行,如果不够的话,可以取更长的
2、出现ANR的activity一般在ANR堆栈的第一行,原因可能在第二行,以“Reason”开头的,分别提取处理后生成summary即可
3、reason部分可能会有很长,jira中提交问题单的时候summary最长是128个字符,所以如果生成的summary长度大于这个数的话,会有截断,不过这部分我交由后面统一处理了。
下面就分别把日志解析ANR和ANR堆栈处理两部分的日志代码贴下面,至于去重部分就和Crash完全一样了:
日志解析ANR:
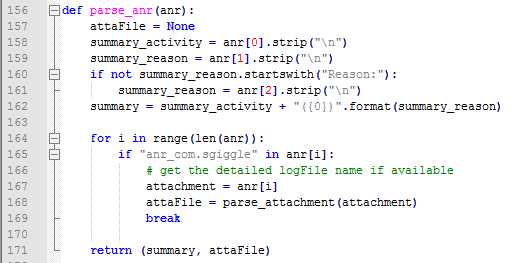
解析ANR堆栈生成summary:
就这样,一份日志中最为关键和重要的Crash和ANR就全部解析完毕了,测试时长和activity的覆盖率我会在数据上报部分再行讲解。从一份Monkey日志中,我们得到了两个列表,里面有我们需要的Crash和ANR的所有信息,接下来我们就需要跟我们的bug系统对接了。
一份生成好的日志经过上面部分的处理之后变成了两个列表,这部分的重点就是如何处理这两个列表了,即和Bug系统(之前公司用的是Jira)的交互了,主要步骤是:
1、Jira模块:连接Jira并封装一些rest api
2、日志导出模块:从手机中导出Monkey日志,崩溃日志
3、日志分析模块:Crash处理,ANR处理
4、崩溃处理模块:新问题时提交问题单,已有问题单更新状态
5、数据汇总模块:测试手机,activity覆盖,测试时长,崩溃次数累计,提交问题单号等
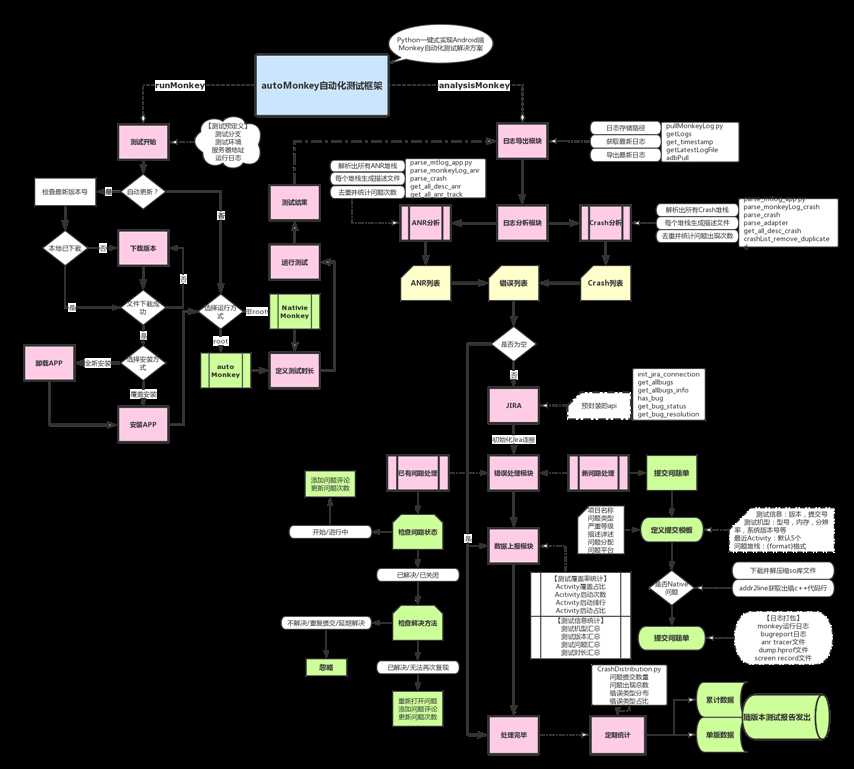
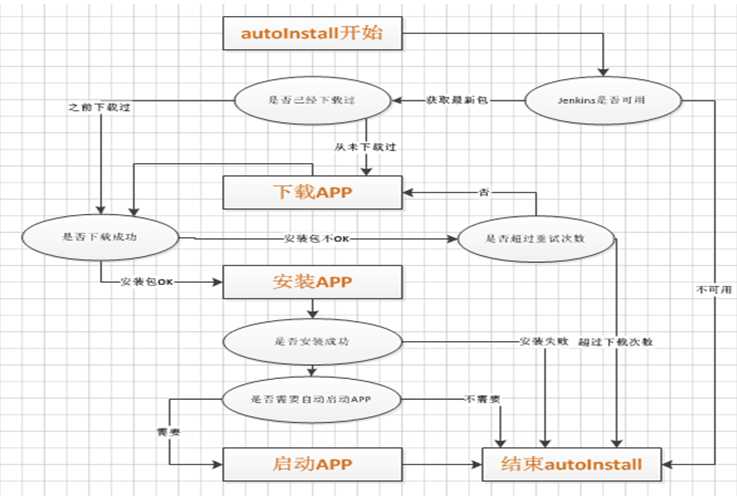
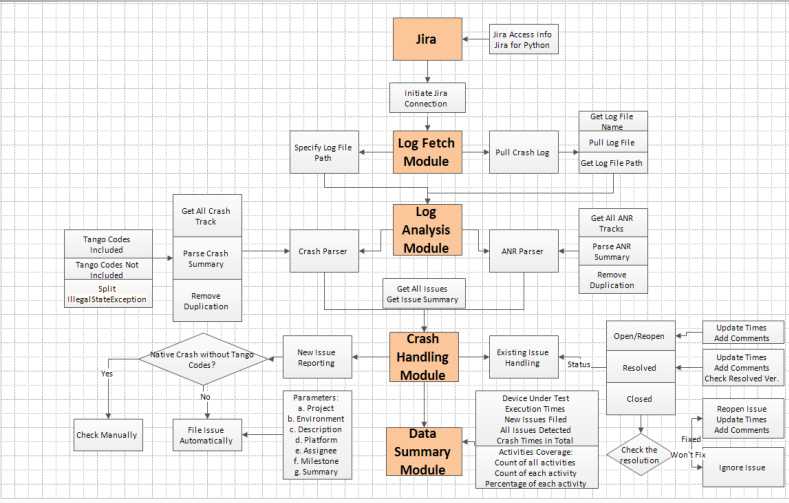
流程图如下:
一、Jira模块(jira_tango.py)
下面贴几个我写的几个方法:
1、获取Jira中提交的崩溃bugList

备注:笔者后来又让同事也帮忙跑Monkey,所以查找所有崩溃的bug列表时需要加上这位同事的jira账号;另外就是search_issue这个api默认只返回50条数据,所以需要制定maxResult参数,但上限是1000条,由于项目后期我在Jira中提交的崩溃bug已经超过1000个,所以就按时间段分开查询,然后合并即可。
2、查看summary是否已经在Jira中存在
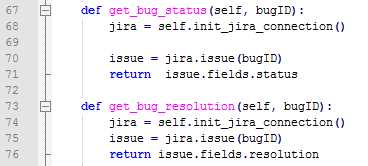
3、获取指定Bug的状态status和resolution
二、日志导出模块(pullMonkeyLog.py)
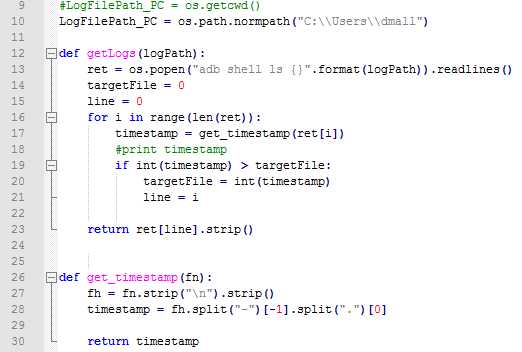
主要处理Monkey日志和崩溃日志两部分,这两部分其实是一样的而且都存在手机中,我们只需要告诉脚本日志存放的位置以及文件的名称即可。对于崩溃日志,我们之前已经讲过了,在解析日志的时候已经得到了完整的文件名,而这种日志都是存在手机的/sdcard目录下,所以就剩下Monkey的日志了。
前面也提到,我们在运行Monkey的时候,日志的命名中已经加入了时间戳的概念,所以一般情况下我只需要去取最新的一份日志即可:
1、按照最新的时间戳解析出文件名
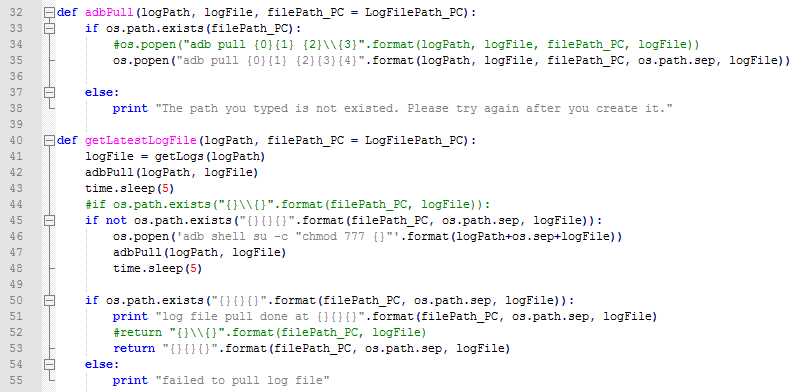
备注:日志从手机导出到PC端是需要指定一个PC目录的,默认是脚本的当前目录,但也支持手动设置一个本地的目录,不过需要注意的是,Windows和Mac下路径的设置是完全不同的。
2、自动导出日志:
备注:Windows下路径的写法是"\\",而Linux和Mac上是"/",不过我们都可以用os.path.sep来替代。
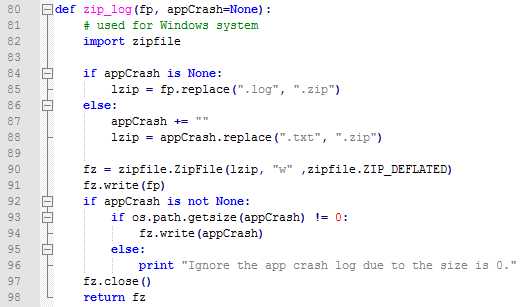
3、日志(合并)压缩
为了上传方便,需要将日志压缩,如果有崩溃日志,更合理的情况是将这两部分日志合并压缩到一个压缩文件中,最早我在Mac上用的是tar模块,后来切换到Windows上用的是zipfile模块。
备注:Monkey的日志我存的是.log文件,崩溃日志这个是.txt文件。
三、日志分析模块
参考上一章节。
四、崩溃处理模块
这部分主要就是跟Jira的对接部分了,基本的流程如下:
1、获取Jira中提交的所有Monkey Crash的Bug列表
2、检查新发现的问题是否已经存在,存在则返回bugID
3、如不存在,则新提交问题单
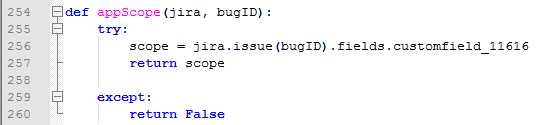
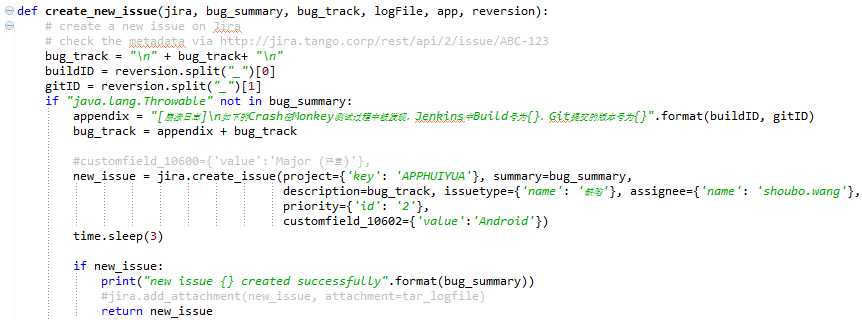
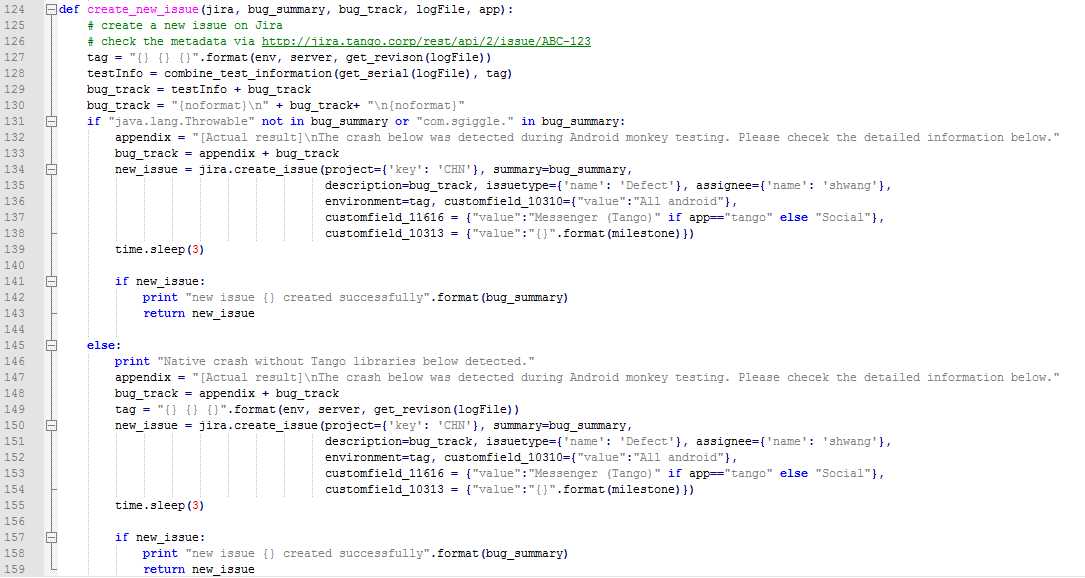
新提交一个问题单最重要的一点是把提交问题单所需要填写的字段都给找出对应的方法并赋值,大家需要明白的一点是,每个Jira项目需要填写的内容是完全不一样的,而且很多项目都有自定义的一些字段,所以除了通用的一些字段能直接使用之外,其他的字段(一般都是以customfield_xxx)都需要通过查询api来获取,具体的方法就是找到该Jira项目中存在的一个问题单然后去查询即可,查询的样式是jira地址/rest/api/2/bugID,例如我之前的项目就是:
http://jira.tango.corp/rest/api/2/issue/ABC-123,拿到字段之后,我们再对他们进行相应的赋值,最后提交即可。
备注:
- 我这里最早是针对Native的崩溃做了单独处理的,所以先做了个判断,后续的话其实全部合并到一起了。大家也能看到,这里面有大量的customfield字段,这些都是Jira的管理员自定义的,每个项目完全都是不一样的。
- 问题单的描述也就是我们之前处理日志生成的summary部分,另外加上了一个标志"Android-Crash",测试App的名字,发生问题的机型(通过序列号映射过来的)
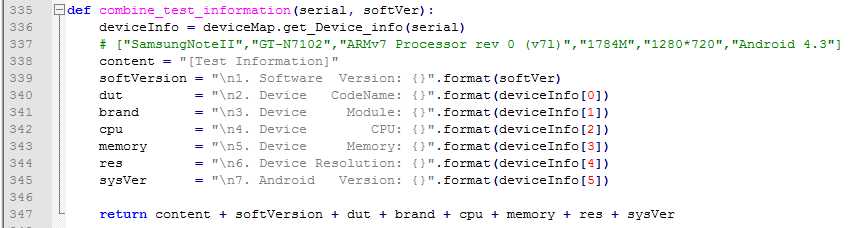
- 问题单的详细描述部分,这个取的就是我们处理完的每个崩溃中详细的堆栈部分,里面包含了最近的几个activity,引起问题的事件序列和错误的堆栈,但我在这个基础上还加了一个测试手机的配置信息,比如内存,系统版本,分辨率等等,这个也是通过映射得来的,这个表需要人工添加。

然后把这些内容分字段分别整合,最后添加到我们之前的问题单详细描述部分,这样,我们在Jira中看到我们提交的问题单就包含了四部分,即【测试手机信息】,【崩溃之前的几个Activity】,【引起崩溃的事件】和【详细的堆栈】,这样对开发来说,也能更好的了解问题发生的原因,也让他们能更好的去分析和解决问题。
- 另外补充一个小技巧,详细描述部分,在堆栈的前后分别加上"{noformat}",整个堆栈就能被很好的展示出来,可以局部滑动查看
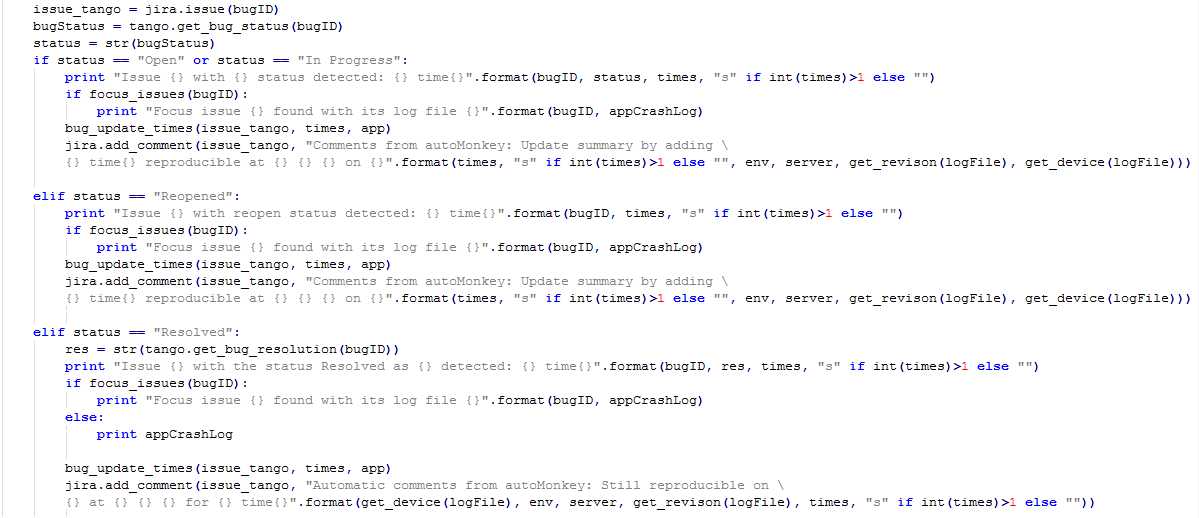
4、若存在,则检查根据其问题单号查找当前状态
5、当前状态为非关闭时,添加评论并更新问题出现次数
非关闭状态的Bug处理:
更新Bug出现次数:
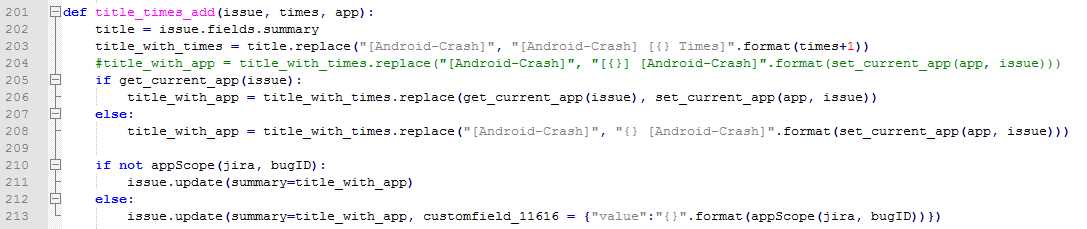
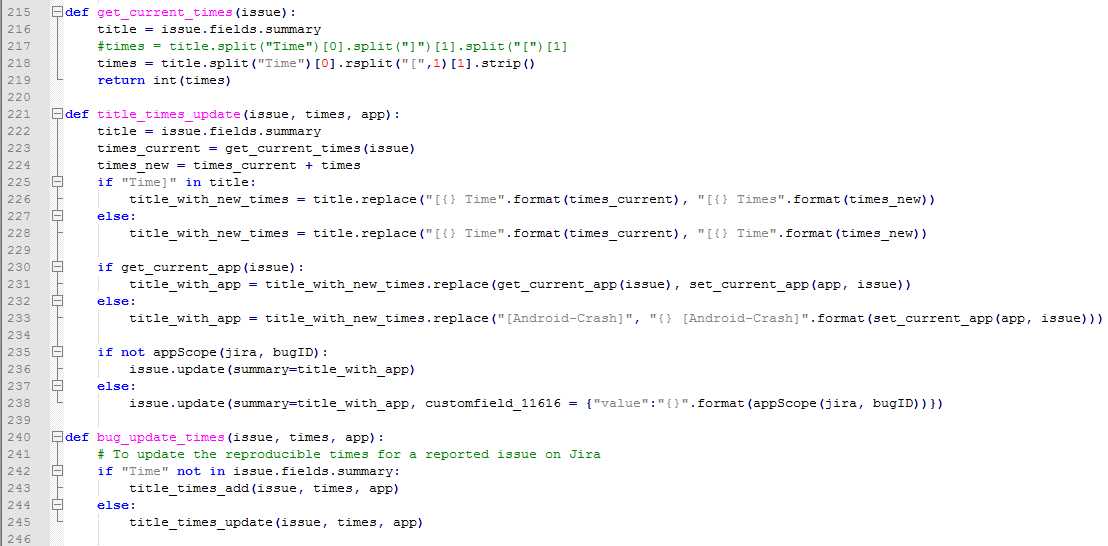
由于autoMonkey框架前期没有加入次数统计的功能,所以最早提交的问题单没有这个字段,也就导致了后来需要兼容这部分的问题单,逻辑上也不难,主要也就是判断心焦的Time这个关键字是否在summary中存在,如果不存在,则先添加这个字段并把之前的次数都初始化为1次,然后加上现在的次数;如果存在这个字段,则直接更新次数即可。
兼容不存在次数字段的问题单:
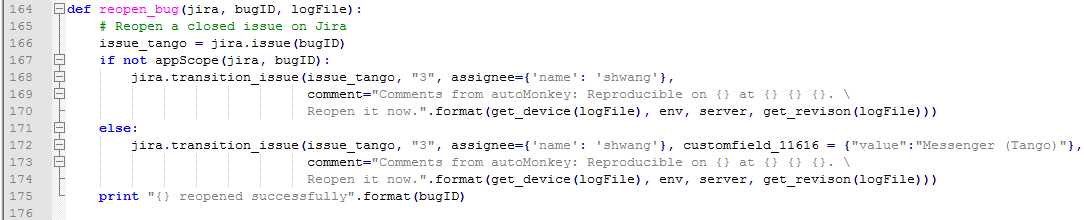
6、当前状态为关闭时,则继续查看其关闭问题单时的方案(resolution),若因为已解决或者不复现等原因关闭时,重新打开问题单并添加评论和更新出现次数,同时本地导出Monkey和崩溃日志进行压缩打包,否者不进行处理(最早是放到本地的一个won‘t fix的列表中的,后来也都不需要了)
Bug状态为已关闭时:
Reopen已关闭的Bug:
备注:Jira中改变Bug状态是通过transition_issue来进行的,需要找到状态转换之后的值并且符合Bug流转的流程才行,比如已关闭的问题单,我们可以重新打开,但不能解决
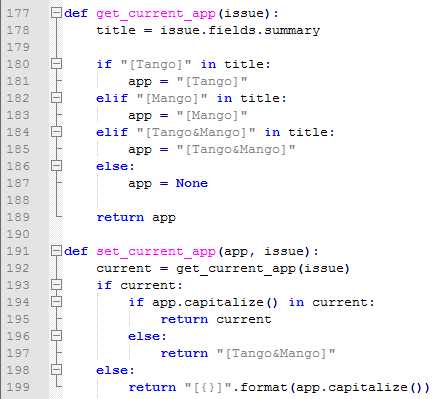
再补充一点:由于之前公司的App拆分成2个独立的App,所以后来autoMonkey框架为了兼容两个App的日志处理,统一加入了从属于哪个App的逻辑,如果只在某个App出现,则在summary中只有该App的名字,但如果两者都有,则两者都加上。
同样的,也需要兼容最早没有这个字段的问题单:
自此,从日志中发现的崩溃或者ANR就处理完毕了,整个过程都基本上不需要人为再干预了,但这里面有几个问题,也请大家注意:
1、提交问题单时无法自动添加附件的问题:这应该是jira rest api的问题,使用add_attachment一直报错,所以这块我都是代码自动合并压缩之后手动上传的;
2、关于提交问题单分配的问题:个人建议所有新提交的问题单都先分配给自己,检查下没有问题之后再分配给对应的开发;
3、一个良好的Jira问题单处理流程真的很重要;
4、如果Jira项目是中文的,这块需要考虑中文字符的问题,如果是这样,建议通过python3来搞,autoMonkey最早是在2.7的版本做的,后来移植到现在的App测试项目上,在中文处理这块遇到了很多编码的问题,不过不用着急,慢慢处理就是了。下面贴两个中文的代码:
新提交问题单:
根据不同Bug状态处理:
第七部分【Monkey数据上报篇】
发现的问题都已经在Jira中处理完毕了,但我们还可以做得更多一些,那就是做一些数据统计的工作,例如测试机型,测试时长,测试版本,启动activity次数,发现的问题单号,新提交问题单号,测试执行次数以及累计崩溃次数等等。做法也比较简单,现在Jira中创建一个任务单,按照上面需要统计的字段做个模板然后放到这个任务单的description中,每次处理完Crash或者ANR之后,再去处理这些字段,拿到数据之后,更新Jira中这个任务单即可。
数据统计的字段包括:
统计启动Activity的次数:
Monkey日志中启动activity都有日志的,按照"// Allowing start of Intent"来查找即可,查找完了按照惯例,需要做去重然后统计的事情:
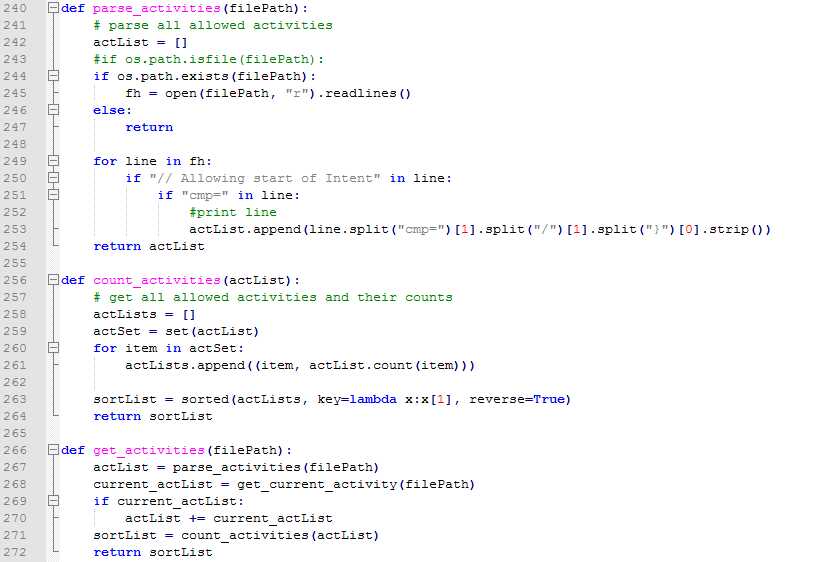
新的Monkey也可以按照"Current Acticity"来查找:
最后,按照activity级别统计次数以及占比:
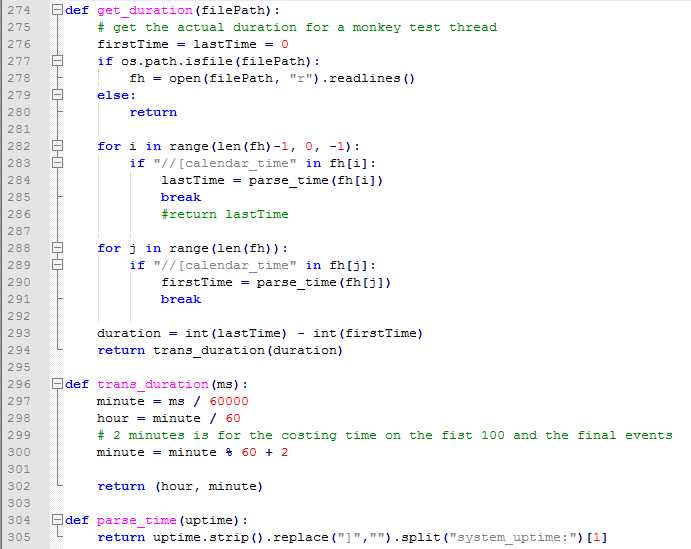
统计单次测试执行时长:
时间的处理是按照日志中最后一次"calendar_time"的时间减去第一次的时间,然后换算成小时和分,最后累计处理即可。
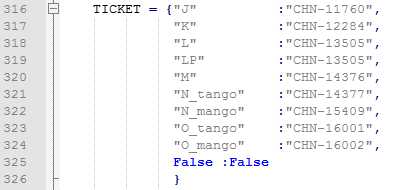
就这样,当一个版本测试结束的时候,Jira中的这个任务单就会累计更新了N次,最后稍微整理下,就可以当做这个版本的Monkey测试报告发给项目组的人员了。当然,除了这个,我们其实还可以分析的更深入一些,比如单个版本甚至整个App项目的问题单分析,这部分就留到下面再说了。注意一点的是,我们是每个版本独自创建在Jira中创建了一个任务单来做数据的统计的,所以每个版本需要创建这么一个而且不能弄错了,不然数据就不准确了,我专门写了个变量来存储这些任务单,而且也不需要我每次都去改配置,比如下面的"O_tango",这完全是当前的版本+测试App拼接的,所以主逻辑我压根就不需要改动,仅仅需要在新创建一个任务单的时候,更新下这个表即可,当然,最好的方式还是用数据库来做,但目前对于这个框架来说,这种方式也基本上够用了,所以就没再继续写数据库的东西了:
第八部分【Monkey数据分析篇】
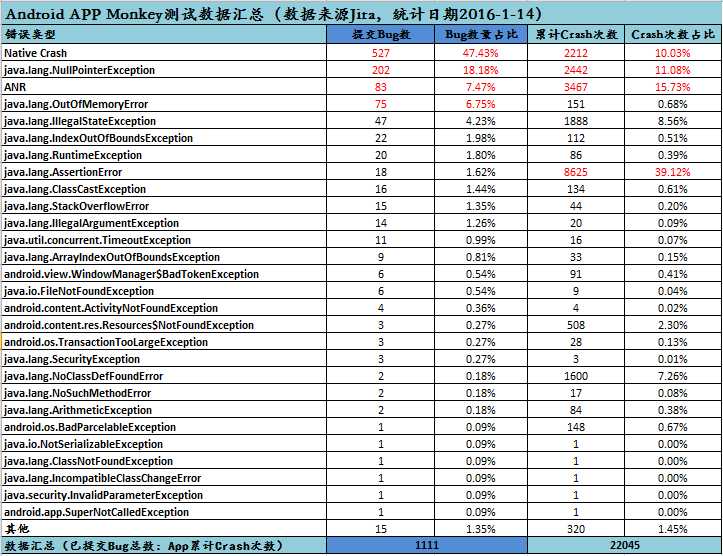
我在这里主要针对我提交在Jira中的问题单按照崩溃类型做了筛选,并统计该类型下提交问题单的个数和崩溃的次数,以及对应到所有纳入统计数据中的占比。大概分两部分:先按照我们之前的查询条件导出提交到Jira中所有的Monkey测试的Bug并按照需要的字段存到一个csv文件,然后用excel做一个我们想要输出的一个模块(涉及到数据的部分必须用公式来做),替换下新的数据之后对应的数字都会自动更新了。
一、Jira问题单处理并导出到csv文件
主要统计了问题单号,描述summary,错误类型,问题出现次数,当前状态,解决方案,提交人,分配人,提交日期等字段,上面的字段除了错误类型和次数之外,其他的都能通过rest api直接或者间接拿到,所以这里简单写下这两部分的。
1、错误类型
解析summary中“at”之前的部分,注意需要考虑ANR和Native这两种特殊的情况:
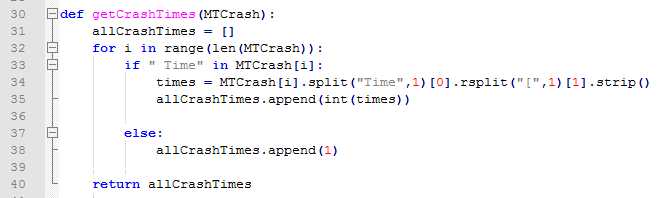
2、问题单出现的次数:
解析summary中“Time”之前的部分:
最后将上面的所有字段一一存下来,最后写入到一个csv文件中:
二、生成深入统计的数据报告
将上面生成的新的数据替换掉之前的数据,由于这都用的是公式,所以数据就会自动更新了,指定版本的话,则需要在问题单导出的时候设置查询条件,比如时间或者版本。就这样,整个App项目以及单个版本的数据分析报告就出来了。
1、测试App项目的数据分析报告:
2、测试App单个版本(一)的数据分析:
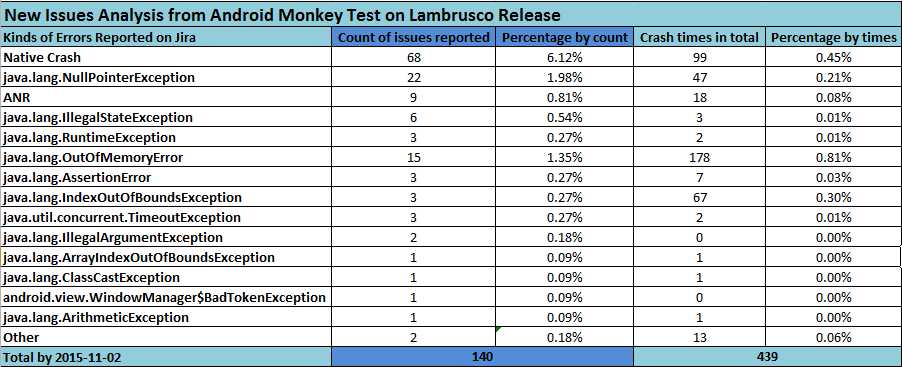
3、测试App单个版本(二)的数据分析:
第九部分【写在最后】
这个框架(姑且叫框架吧)都是我一个人慢慢码出来的,前后更新了5,6版,很多功能都是一步步慢慢添加完善起来的,正好也是对我自学Python效果的一个检验吧,说实话,我的代码功底其实很弱,正是边学边用于项目的实践让我对Python有了一个更深刻也更检验实际效果的理解,当然,这里面还有太多的东西值得我们去深入学习和挖掘,就像我今年年初的时候出去找工作,曾经有一个面试官问我这个框架有哪些缺点,是的,这个框架也有很多问题,不知道看过的各位有什么想法,有的话可以找我或者留言交流吧。
写在最后的最后
本着服务于更多APP测试的想法,如果大家所在的APP测试有需要我协助帮忙测试的话,可以私下和我联系,相信我,这个框架能发现很多各位手工或者自动化发现不了的诸多APP Crash问题,而且不需要各位提供任何源码,使用任意官方渠道的安装包即可。之前一个朋友告知了我他的APP的名字,于是在应用宝中下载安装后运行了10个小时,在我的测试机上发现了4个累计8次的APP Crash问题,我用脚本已经解析出来了,如下:
目前为尝试阶段,不收取任何费用,完成后会提供相应的错误日志,后期的话如果效果好,考虑到设备损耗问题,可能会考虑收费,请各位知晓。
文字略多,后续会把大部分的代码开源,也借此文缅怀我的大Tango~