TCP SYN-Cookie的原理和扩展
Posted ksiwnhiwhs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TCP SYN-Cookie的原理和扩展相关的知识,希望对你有一定的参考价值。
SYN-Cookie概述
预防半连接攻击,SYN-Cookie是一种有效的机制,它的基本原理非常简单,那就是“完成三次握手前不为任何一个连接分配任何资源”,它是怎么做到的呢?也是非常简单。1.编码信息
将一些本应该在本地保存的信息编码到返回给客户端的SYN-ACK的初始化序列号或者时间戳里面。握手尚未完成不分配任何资源(Linux即不分配request结构体)。2.解码信息
等到客户端的ACK最终到来的时候,再从ACK序列号里面解码出保存的信息。3.建立连接
利用第2步解码出来的信息建立一个TCP连接,此时因为握手已经完成,可以分配资源了。我们接下来通过图示和代码来看一下编码和解码的过程。
编码过程图示
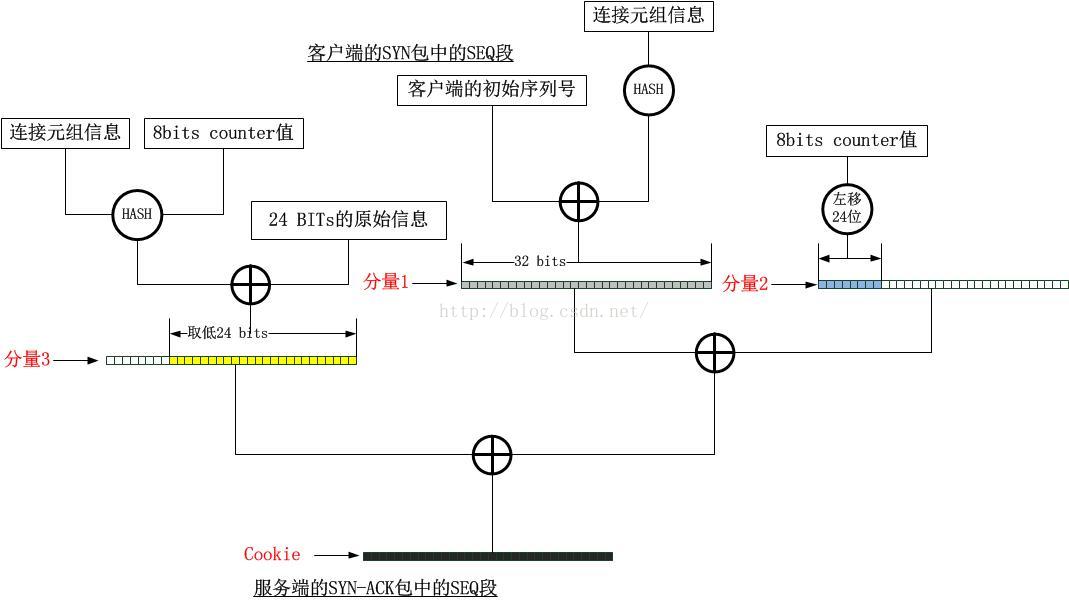
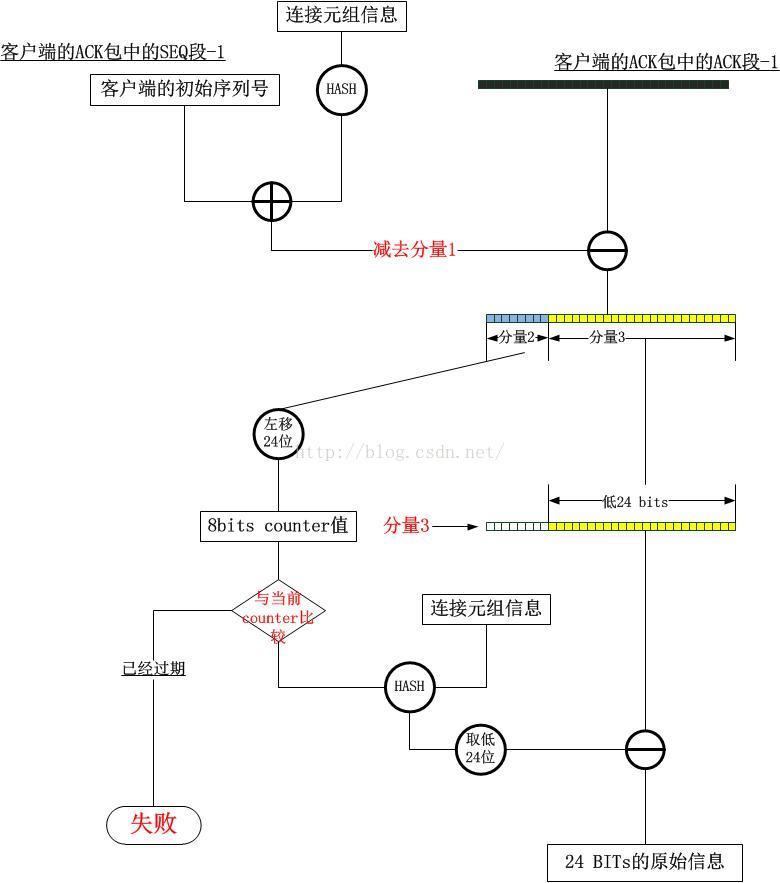
解码过程图示
问题
通过上面的编码解码过程中好像没有什么check/compare操作,一般而言,对于类似HASH或者摘要的算法,都需要对信息进行比对,比如对一段信息生产一个摘要,为了确保该信息没有被篡改,需要再次使用相同的算法生成摘要,如果两段摘要的值不同,说明信息被篡改了!对于上面的算法,在生产Cookie的时候,我们注意到使用hash算法对元组生产了一个值,但是对于解码的过程,它并没有再次计算这个值与原始携带的值做比对,这样合理吗?这事实上是Linux的一个hack!Linux将一段data做了限定,比如它的值严格在0-7之间,将这个data一同参与运算,而不是仅仅将其编码到固定的某几个bit,算法寄希望于:如果数据是伪造的或者被篡改了,那么解码出来的data的值仍然处在规定的严格区间里的可能性微乎其微!
测试代码
我们来看一个用户态的测试代码,说明一下24比特数据的编码和解码的过程:
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
typedef unsigned int u32;
#define COOKIEBITS 24 /* Upper bits store count */
#define COOKIEMASK (((u32)1 << COOKIEBITS) - 1)
// 简单hash函数,只为测试!
static u32 cookie_hash(u32 saddr, u32 daddr, u32 count, int c)
{
u32 tmp = (saddr + daddr - c) & ((u32)-1);
return tmp;
}
// 编码过程
static u32 syn_cookie(u32 saddr, u32 daddr, u32 sseq, u32 count, u32 data)
{
return (cookie_hash(saddr, daddr, 0, 0) +
sseq + (count << COOKIEBITS) +
((cookie_hash(saddr, daddr, count, 1) + data) & COOKIEMASK));
}
// 解码过程
static u32 check_syn_cookie(u32 cookie, u32 saddr, u32 daddr, u32 sseq, u32 count, u32 maxdiff)
{
u32 diff;
cookie -= cookie_hash(saddr, daddr, 0, 0) + sseq;
diff = (count - (cookie >> COOKIEBITS)) & ((u32) - 1 >> COOKIEBITS);
if (diff >= maxdiff) {
return (u32)-1;
}
return (cookie - cookie_hash(saddr, daddr, count - diff, 1)) & COOKIEMASK;
}
int main()
{
u32 saddr = 0x11223344, daddr = 0x23456789;
u32 cnt, seq, data = 0, data2 = 0, cookie;
int i, j, k = 0;;
for (i = 0; i < 0xffffffff; i++) {
//srandom(time(NULL));
saddr = random()&0xffffffff;
daddr = random()&0xffffffff;
seq = random()&0xffffffff;
cnt = random()&0xffffffff;
data = random()&0xffffff;
cookie = syn_cookie(saddr, daddr, seq, cnt, data);
data2 = check_syn_cookie(cookie, saddr, daddr, seq, cnt + 3, 4) & 0xffffff;
if (data == data2) {
k++;
}
}
printf("%0x
", k);
}
声明
到此为止,我并没有描述任何关于SYN-Cookie的HASH生成算法以及其安全性问题,并且直至文章的最后也不会描述。这是因为它们并不属于SYN-Cookie机制的核心,只是一个实现问题,因此它们甚至都不属于TCP/IP,这里的安全性指的是,SYN-Cookie伪造的难以程度,这在另一方面挑战了HASH算法的抗碰撞能力,这些HASH算法(一定程度的摘要算法)可能包括SHA1,MD5,甚至SM3,也可能只是简单的取模,JHASH等,取决于你对性能和抗碰撞能力之间的一个平衡,二者肯定是此消彼长的。声明到此为止,后续如果我有足够的时间,我会专门写一些关于密码,摘要,认证方面的文章的。以下我们来看一下SYN-Cookie关于实现的Tips以及其问题所在。
标准规范与Linux实现
注意,以上描述的仅仅是Linux的SYN-Cookie的实现,标准的实现并不是这样,以下标准的实现,摘自WIKI:发起一个 TCP 连接时,客户端将一个 TCP SYN 包发送给服务器。作为响应,服务器将 TCP SYN + ACK 包返回给客户端。此数据包中有一个序号(sequence number,TCP头中的第二个32 bit),它被 TCP 用来重新组装数据流。根据 TCP 规范,由端点发送的第一个序号可以是由该端点决定的任何值。SYN Cookies 是根据以下规则构造的初始序号:
令 t 为一个缓慢递增的时间戳(通常为 time() >> 6 ,提供 64 秒的分辨率);
令 m 为服务器会在 SYN 队列条目中存储的最大分段大小(maximum segment size,简称为 MSS);
令 s 为一个加密散列函数对服务器和客户端各自的 IP 地址和端口号以及 t 进行运算的结果。返回得到的数值 s 必须是一个24位值。
初始 TCP 序号,也就是所谓的 SYN cookie,按照如下算法得到:
头五位:t mod 32;
中三位:m 编码后的数值;【注意,Linux并不是这么实现的】
末24位:s 本身;
注:由于 m 必须用 3 位进行编码,服务器在启用了 SYN Cookie 时只能为 m 发送八种不同的数值。
根据 TCP 规范,当客户端发回 TCP ACK 包给服务器以响应服务器的 SYN + ACK 包时,客户端必须使用由服务器发送的初始序号加1作为数据包中的确认号。服务器接着从确认号中减去 1 以便还原向客户端发送的原始 SYN Cookie。
接下来服务器进行以下检查:
根据当前的时间以及 t 来检查连接是否过期。
重新计算 s 来确认这是不是一个有效的 SYN Cookie。
从 3 位编码中解码 m,以便之后用来重建 SYN 队列条目。在此之后,连接照常进行。
对照上面的编码,解码图,我们发现,标准的做法只是散列了32位序列号中的低24位,相比而言,Linux的实现可能更加安全一些,因为它在整个结果中叠加一个关于五元组的散列值分量以及counter值分量,根据向量叠加的理论,反过来你很难将其分离开来。相比Linux的实现,标准的实现方式更像是传统的方式,一段根据元组信息计算出来的摘要padding到低24位作为SYN-ACK的序列号,然后在ACK返回时,根据数据包获取元组信息,根据序列号的高5位获取conter信息,然后重新计算摘要,最后比对。这是一种标准的方式,而Linux则是一种优化的方式。
SYN-Cookie的副作用
1.针对CPU的DDOS攻击
虽然SYN-Cookie避免了内存空间被爆掉,但是却引来了CPU时间被爆掉的机会,这又是一种时间-空间之间的权衡!如果攻击者发送大量的ACK包过来,那么被攻击机器将会花费大量的CPU时间在计算Cookie上,造成正常的逻辑无法被执行,同时即便是大量的SYN包也可以将CPU爆满。解决之道有吗?想当然的做法是将计算Cookie这件事从CPU上卸载掉,使用硬件来完成。那么有这种硬件吗?我们知道Intel都有CPU可以做AES了,那么做HASH运算应该也不在话下,其实就是SIMD指令的支持。Linux目前在计算SYN-Cookie的时候使用的是SHA1算法,利用硬件(或者协处理器)加速的话,应该可以带来不少的收益,具体可参见这篇文章《Improving the Performance of the Secure Hash Algorithm (SHA-1)》
如果不想用硬件加速或者不想跟硬件绑的太死,那就优化一下HASH算法吧,个人觉得使用SHA1算法有点太重了。
2.TCP选项的协商
我们知道,由于SYN-Cookie编码空间有限(标准中只有3比特),在启用SYN-Cookie的时候,很多的TCP选项都无法支持了,但这只说对了一方面,事实上,在启用timestamps支持的情况下,TCP的选项支持信息是可以编码到时间戳里面的,也就是说,只要你能确认接下来会被客户端echo过来的字段,都可以作为信息编码的空间!这是不是意味着,如果没有支持时间戳选项,其它的选项也都不能支持了呢?虽然目前的Linux实现是这样的,但是我不认为它们不能支持。因为Linux并没有按照规范使用3个比特来编码MSS!这个从上面的图示和例子中都可以看出来。所有的24个比特都可以用来编码需要的数据(取模,越界,溢出并不是问题,因为计算机内所有的数据类型都是在钟表上计数的)。我们来看一下双方协商的MSS是怎么编码到Cookie中的。如上编码图所示,它将MSS的数组索引编码到了一个24BIT的空间中,但是一个索引可以用到那么大的空间吗?实际上8个比特就足够索引256个MSS了(SYN-Cookie标准中的MSS编码位只有3个比特,不过Linux并没有规定)。于是剩下的24-8=16个比特可以作为其它的用途了。我们知道,目前的TCP选项一共是9个,16个比特足够存储了。这就是将MSS索引进行一种再编码的方式,来支持TCP选项的协商。
对24比特再编码的一个合理的图示如下:
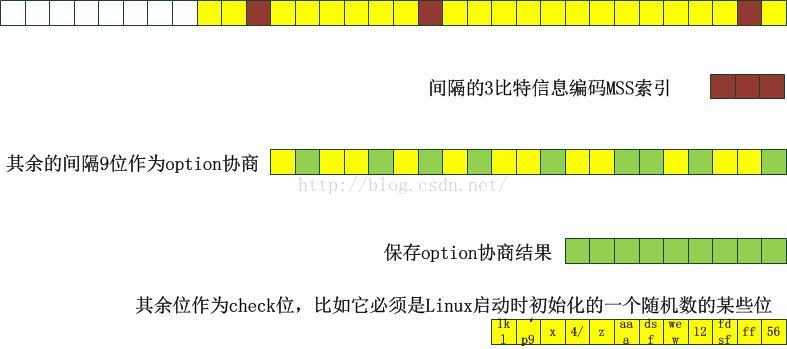
这丝毫没有降低安全性,相反,它提升了安全性,使得伪造更加困难!
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow
以上是关于TCP SYN-Cookie的原理和扩展的主要内容,如果未能解决你的问题,请参考以下文章