我对TCP协议的一点形而上的看法
Posted ksiwnhiwhs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我对TCP协议的一点形而上的看法相关的知识,希望对你有一定的参考价值。
近期和朋友交流聊到一个话题,即TCP的未来。我的观点很简单,即:
- 从纯技术的角度,TCP已经不再合时宜,早该被淘汰了;
- 从生态的角度,TCP会持续进化下去,且会越来越庞大臃肿。
我们知道,TCP/IP构成的互联网本身就是一个巨大的持续进化的生态系统,其中任何一个组件都不能被统一替换,你想让它变成另外一个样子,只能等着它进化成那个样子,而不能把它直接修改成那个样子,这一点与我们的生物进化论非常一致。
??TCP是一个30年前的协议,在那个时间,TCP/IP仅仅是刚刚开始,基于TCP来进行的数据传输首要的需求就是按序性和正确性,而不是性能。此外,当时的带宽非常昂贵,具体表现在设备昂贵,且耗电,电缆铺设成本高昂…这意味着技术上很难通过粗犷激进的策略去保证数据的正确按序传输,因此问题就转化为:
如何用最少的字节保证数据的正确按序传输?
??好吧,基于单向批量停-等协议的TCP就这样被设计了出来,请注意,这个时候并没有什么所谓的拥塞控制,这就好比新中国刚成立时北京大街上不需要拥塞控制一样,红绿灯存在的目的不是拥塞控制,而是冲突域分时复用。
??在这种先污染后治理的理念下,随着技术的进步,一旦出现了拥塞(不管是TCP/IP还是城市街道),其首先想到的措施永远是错误的。因为这个思路的根基就是错误的。
??不要觉得北京单双号限牌,上海限外,然后深圳,广州跟着学这件事是多么糟糕,其实这是上述思想下应对拥堵的一个典型措施,即限制而不是疏导。先污染后治理的思想决定了后续的应对措施必然是阻而不是疏,同样的事情还发生在安全领域。
??还记得上世纪90年代初的防盗门吗?现在也还有。一般的家挺都有两层门,里面一层朝里开,是个木门,外面一个大铁门朝外开用于防盗,非常不方便…在信息安全领域也是一样。
??回到TCP。作为一个端到端协议,对网络无感知的TCP必须要进行拥塞控制,否则整个网络将会在TCP流量的冲击下崩溃,但是当TCP意识到拥塞问题的时候,协议已经被设计出来了,所以我们从第一版TCP协议可以看到,TCP协议头里没有任何可以用于拥塞控制的字段!于是拥塞控制只能在发送端的状态机里做(而不是在协议本身,因为已经晚了!)。
??怎么做呢?很简单,增加一个限制,即拥塞窗口cwnd!这和北京单双号限牌,上海限外没有任何本质上的区别。cwnd的作用在于,限制数据包发送的数量!北京上海应对交通的措施同样是限制上路车辆的数量!问题是,拥塞的原因真的是因为数据包太多或者车辆太多吗?
??完全不是这样!
??深圳深南大道科技园段从大冲到南山大道这一段算是半快速路,和全快速路不同的是,即便深圳早晚高峰的时候,这段路的中间都显得非常空,很常见一段时间几乎没有任何车辆通过,这场景和北京东三环,上海延安高架内环高架和深圳滨海大道的情形完全不一样:
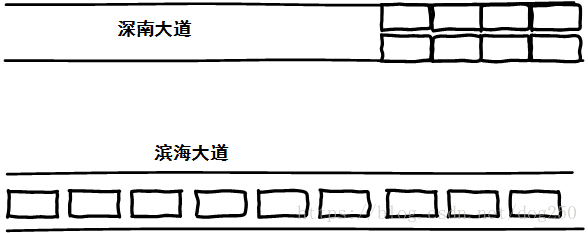
深南大道不是的车辆全部都bloat到前面的红绿灯那里了,而滨海大道的车辆却在缓慢pacing前行,我假设两种情况车辆通过相同长度道路所用的时间一致,请问哪种情况更能加重交通拥堵?
??非常显然,是深南大道!因为假象会让更多的人选择这条道路,然后快速通过无人区后直接堵在红绿灯处!TCP的拥塞与此类似。因此,造成拥塞的原因并不是你发送的包太多,而是你发送的包太快!这里值得澄清一下的是,从30年前到现在,数据包通过电缆的速度几乎没有改变,但是数据包通过路由器交换机的速度却时刻发生质的飞跃。在30年前,你可以认为一个数据包的80%的RTT都是排队延时。
??以上,我们已经知道,如果cwnd过大,就会发生深南大道的情形,造成拥塞,但是一旦TCP发现了拥塞(我们这是在讨论本质,所以如何发现拥塞并不重要,管你是基于丢包还是基于延时),TCP会迅速降低cwnd,其实这是一种错误的自省式做法,这等于说你承认了拥塞是你造成的,至少你是帮凶,你是作案人员的一份子。TCP的收敛模型几乎就是这种罪与罚的轮回。
??其实,TCP的MD机制还有一点自私的味道。迄今为止,最终倡导的类似CUBIC这种基于丢包的算法,但是TCP端到端流量控制的滑动窗口要求TCP必须及时恢复丢包,不然协议将不可用,所以采用保守的策略去恢复丢包几乎是唯一的选择。所以从本质上来讲,TCP协议就是一个优化版的停等协议。
真正的拥塞控制就应该像城市快速路那样,在拥塞时排队缓行而不是造成bufferbloat!
??所以说,正确的做法是基于速率来控制,而不是基于数量来控制。让我不明白的是,IP骨干网早就采用了类似令牌桶pacing这种速率控制机制,为什么端到端的TCP却丝毫不跟进,依然我行我素地基于cwnd来控制数量。
??不管怎样吧,2016年9月是一个里程碑,Google放出了一个叫做BBR的TCP拥塞控制算法,该算法彻底重构了整个TCP拥塞控制的框架,算是一个创举,虽然它很简单,但从零到一难道不都是从简单开始吗?看到了你会觉得简单,看不到时思维定势很难让你想到,不是跪舔Google,但这就是Google!
??BBR是什么我不再多说,中文版普及资源几乎都有我的影子,再说这个就显得罗嗦。其它文章没有提到的是,BBR作为拥塞控制的2.0版本(1.0当然是原始Reno,其优化版进化到了CUBIC),这只是一个开始,我们每个人都期待能看到BBR时代的CUBIC,令人兴奋的是,BBR本身的2.0就要来了,熟悉QUIC的可以先睹为快了。我这里就给出几个链接:
- 关于BBR 2.0的链接
https://datatracker.ietf.org/meeting/101/materials/slides-101-iccrg-an-update-on-bbr-work-at-google-00
https://www.ietf.org/proceedings/99/slides/slides-99-iccrg-iccrg-presentation-2-00.pdf - 关于BBR 2.0之QUIC patch的链接
https://chromium.googlesource.com/chromium/src/net/+/0fe3a4ca32029b23947e29f072cc857293a98dd7%5E%21/#F0 - 我自己写的一个简易版
https://blog.csdn.net/dog250/article/details/80203520
那么,回到主题,TCP未来会被QUIC取代吗?
??按照生态系统的进化,TCP不会被取代,不是没法取代它,而是取代不起,必须考虑兼容性以及投资!只要有一人还在用TCP,互联网就要支持,更要命的是,TCP从来都不是自己!
??那么,QUIC如何?我认为QUIC这种协议将来一定会大行其道。因为它代表了一种新的东西。如果说TCP是一个单向停等协议的话,QUIC就是状态机同步协议的1.0版本!
??我们想象一个把一系列数据传输给对端这件事意味着什么?这意味着数据在两端发生了同步!我们把传输过程中的每一个状态作为一个步骤,那么整个传输过程就是一个同步的过程。发送端和接收端要做的就是不断交换自己本端的状态,然后查漏补缺,这正是OSPF协议的思想!这可以单向瞎猜的TCP协议猛烈多了吧。
??TCP之所以在单边拥塞控制领域很难出成绩,其硬伤就是TCP协议本身携带的信息太少,即便加上后来为了优化协议而添加的timestamt,sack这种,也无法和传递大量同步信息的QUIC协议相提并论。这一切发生的现实是,如今的带宽非常廉价。
在互联网的世界里,爹很难死掉,但是孩子必须成长。Together with IPv4 vs. IPv6!让我们拭目以待!
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow
以上是关于我对TCP协议的一点形而上的看法的主要内容,如果未能解决你的问题,请参考以下文章