谈谈我对 归一化 与 标准化 作用 区别 的理解
Posted lin-yi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谈谈我对 归一化 与 标准化 作用 区别 的理解相关的知识,希望对你有一定的参考价值。
为什么要做归一化或者标准化?
主要是为了调整样本数据每个维度的量纲,让每个维度数据量纲相同或接近。 为什么要调整量纲?目的是什么?
1 量纲不一样的情况是什么?
比如一个2分类任务,预测一批零件是合格品还是残次品。
这个零件把他假象成是细长细长的棍子,有两个维度特征, 半径都是 1 cm左右, 长度都是1000cm左右
合格的零件半径都在1cm左右差距不大, 长度都在1000cm左右差距不大, 差距稍微大了点 可能就不合格了。 至于差距多少算不合格, 要建立模型自己去学一下。
一个特征1cm左右 一个特征1000cm左右, 这个就叫量纲不一样。
1cm左右的特征,上差下差 也都是0.几cm的差距, 1000cm的特征上差下差可能差出10cm多 或者更多, 这就是量纲不一样!
2 量纲不一样会造成什么样的后果?
会误导误导我们的模型学习过程!!
比如这个零件合不合格的问题, 用k近邻算法,或者svm算法,或者什么其他算法,
当算 点到点距离 或者 点到超面距离 的时候,
半径带来的差的平方 可能是(0.75 - 1)^2 = 0.25^2 基本连1都不到
长度带来的差的平方 可能是 (1020-1000)^2 = 400, 它很大, 甚至可能都超过1000这个数量级
再把 半径的残差和长度的残差加和 400.00xx
结果 半径的残差 可以忽略不计了!!
模型认为 长度差距带来的影响巨大!
get不到半径细小的差距 也是导致合不合格的原因! 可能学不明白到底因为啥合格因为啥不合格!
3 怎么解决这个问题??
把每个维度特征的量纲调整到一样或者相近!
目前,最常用的两个方法是:
归一化
标准化
4 归一化 和 标准化 是咋回事?干了什么? 怎么做到缩放的量纲?
在这里我只说说最简单常用的标准化和归一化, 变形的形式我就不说了,
因为我了解的也不深入!简单的我都整不明白呢! 整复杂的再整错了挨揍啥的不好。
对于一个样本X 是n行*d列 的矩阵, 有n条样本数据,每个数据占一行, 每条数据有d个的特征
比如刚才内个零件的 X 就是n行*2列的矩阵, 有n个零件的数据 每个零件有2个特征 分别是半径和长度
用Xi 表示所有n个样本的第i列特征,
归一化和标准化他俩分别干啥了呢? 不要急 且听我继续胡说八道。
归一化:
对样本X的每个列Xi,
Xi = (Xi - min(Xi)) / ( max(Xi) - min(Xi) )
把Xi这列的每个数都减去 这列的最小值 再 除以 这列最大值和最小值的差
结果: 所有列的数据,都缩放到 0到1之间,且最大值是1,最小值是0
这个变换 保留了 这列中每个数 到最小值的差距的比例,
量纲大的给缩小了,量纲小的给扩大了 全都在0到1之间, 量纲严格相等
标准化:
对样本X的每个列 Xi
Xi = (Xi - mean(Xi)) / 方差(Xi)
把这列的每个数都 减去 这列的均值 再 除以这列的方差
结果: 所有列的数据 均值为0 方差为1
这个变换,保留了每列原本的分布, 保留了每个数 距离均值的差距比例
所有数在 均值 为中心周围分布, 并且方差为1
对于不同列 最大值与最小值之间的差距 不一定是多少,
量纲大的列被缩小 量纲小的列被放大, 量纲不严格相等,只是比原来更接近 而且很接近了。
5 归一化和标准化 怎样选择用哪个预处理数据? 有什么区别??
1 现实中,用归一化更多, 因为需要严格要求数据在0到1之间且量纲相等。
比如现在在深度学习中 cnn中的分类任务,都使用梯度下降BP反向传播算法更新参数,
在梯度下降中是为了逼近最优解,如果不同维度特征的量纲差距大,在超空间中,会形成超椭球的形状
梯度下降过程会反复震荡,如下:
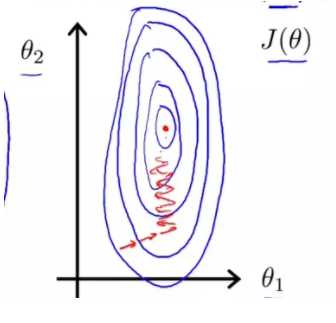
当量纲完全一致,样本分布在空间是超正圆,梯度下降才最高效,如图:
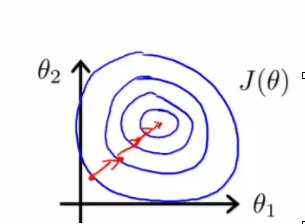
2 但是不尽然! 有的时候真的需要使用标准化, 归一化效果不好。
比如 就预测零件是否合格的问题,
往往合格的零件,长度和半径 都在样本均值附近 才最好 才是合格的。
长度过短或者过长都不合格, 半径太大太小也都不合格。
我们需要保留样本距离均值的差距比例,
如果使用归一化,
我们只考虑样本到最小值的距离比例,最小值估计应该是个残次品,
我们丢失了最想要的 均值 周围的分布情况。
均值左侧的被缩放程度小, 均值右侧被缩放程度大!
3 总结一下:
有的人说,一般只用 标准化! 这个保留了样本原来的分布!!
有的人说, 一般只用 归一化! 这个梯度下降收敛效果好!!
我个人的理解,
如果样本噪声不大,污染不严重, 采用归一化比较好, 量纲缩放到严格相同, 计算距离的时候带来的影响是等价的。
如果 均值的信息是有意义的, 建议不实用归一化,实用标准化。 量纲不同但很接近, 不要丢失核心关键!!
以上内容纯属个人理解! 欢迎批评指正!
谢谢阅读。
以上是关于谈谈我对 归一化 与 标准化 作用 区别 的理解的主要内容,如果未能解决你的问题,请参考以下文章