ArrayList
Posted joe-go
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ArrayList相关的知识,希望对你有一定的参考价值。
前言
集合是Java中非常重要而且基础的内容,因为任何数据必不可少的就是对改数据进行如何的存储,集合的作用就是以一定的方式组织、存储数据。
对于集合,我认为比较关心的点有四个:
1.是否允许空
2.是否允许重复数据
3.是否有序,有序的意思就是读取数据的顺序和存放数据的顺序是否一致
4.是否线程安全
ArrayList介绍
ArrayList简介
先来看一下ArrayList类的声明:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
ArrayList是一个数组队列,相当于动态数组。与Java中的数组相比,它的容量能动态增长。它继承了AbstractList,实现了List,RandomAccess,Cloneable,java.io.Serializable这些接口。
ArrayList继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能;
ArrayList实现了RandomAccess接口,即提供了随机访问功能。RandomAccess是Java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象,这就是快速的随机访问;
ArrayList实现了Cloneable接口,即覆盖了函数clone(),能被克隆;
ArrayList实现java.io.Serializable接口,这就意味着ArrayList支持序列化,能通过序列化去传输;
和Vector不同,ArrayList中的操作不是线程安全的。所以,建议在单线程中才使用ArrayList。
ArrayList构造函数
// 默认构造函数 ArrayList() // capacity是ArrayList的默认容量大小。当由于增加数据导致容量不足时,容量会添加上一次容量大小的一半。 ArrayList(int capacity) // 创建一个包含collection的ArrayList ArrayList(Collection<? extends E> collection)
ArrayList的API
// Collection中定义的API boolean add(E object) boolean addAll(Collection<? extends E> collection) void clear() boolean contains(Object object) boolean containsAll(Collection<?> collection) boolean equals(Object object) int hashCode() boolean isEmpty() Iterator<E> iterator() boolean remove(Object object) boolean removeAll(Collection<?> collection) boolean retainAll(Collection<?> collection) int size() <T> T[] toArray(T[] array) Object[] toArray() // AbstractCollection中定义的API void add(int location, E object) boolean addAll(int location, Collection<? extends E> collection) E get(int location) int indexOf(Object object) int lastIndexOf(Object object) ListIterator<E> listIterator(int location) ListIterator<E> listIterator() E remove(int location) E set(int location, E object) List<E> subList(int start, int end) // ArrayList新增的API Object clone() void ensureCapacity(int minimumCapacity) void trimToSize() void removeRange(int fromIndex, int toIndex)
ArrayList的数据结构
ArrayList和Collection的关系如下图所示:
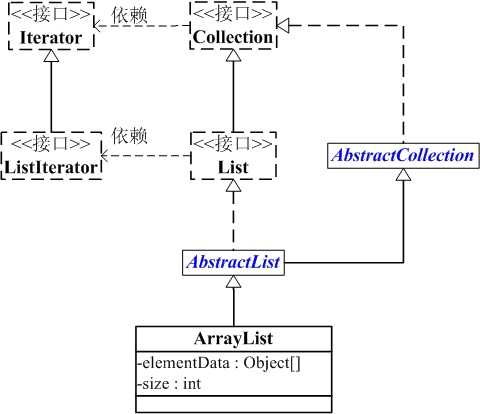
ArrayList包含了两个重要的对象: elementData 和 size 。
transient Object[] elementData; private int size;
elementData:是Object类型的数组,它保存了添加到ArrayList中的元素。实际上,elementData是个动态数组,我们能通过构造函数ArrayList(int initialCapacity)来执行它的初始容量为initialCapacity;如果通过不含参数的构造函数ArrayList()来创建ArrayList,则elementData的容量默认是10;elementData数组的大小会根据ArrayList容量的增长而动态的增长。
size:ArrayList里面元素的个数,这里要注意一下,size是按照调用add、remove方法的次数进行自增或者自减的,所以add了一个null进入ArrayList,size也会加1 。
四个关注点在ArrayList上的答案
| 关 注 点 | 结 论 |
| ArrayList是否允许空 | 允许 |
| ArrayList是否允许重复数据 | 允许 |
| ArrayList是否有序 | 有序 |
| ArrayList是否线程安全 | 非线程安全 |
ArrayList源码解析
1.添加元素
先来看一下源码:
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
我们先不看第二行的 ensureCapacityInternal函数,这个方法是扩容用的,底层实际上在调用add方法的时候只是给elementData的某个位置添加了一个数据而已,用一张图表示的话是这样的:
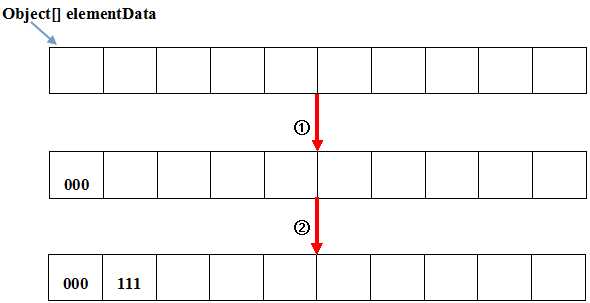
注意: 我这么画图有一定的误导性。elementData中存储的应该是堆内存中元素的引用,而不是实际的元素,这么画给人一种感觉就是说elementData数组里面存放的就是实际的元素,这是不太严谨的。不过这么画主要是为了方便起见,只要知道这个问题就好了。
2.扩容
跟踪ensureCapacityInternal函数,发现实现的逻辑在grow函数中:
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
发现newCapacity的值是oldCapacity加上oldCapacity / 2,也就是原来的1.5倍。(在JDK版本1.6和更早的版本中,扩容是1.5倍+1)。为什么为扩展1.5倍呢?
1、如果一次性扩容扩得太大,必然造成内存空间的浪费
2、如果一次性扩容扩得不够,那么下一次扩容的操作必然比较快地会到来,这会降低程序运行效率,要知道扩容还是比较耗费性能的一个操作
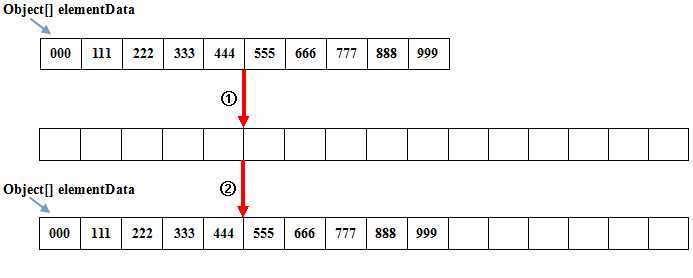
所以扩容扩多少,是JDK开发人员在时间、空间上做的一个权衡,提供出来的一个比较合理的数值。最后跳用到的是Arrays的copyOf方法,将元素组里面的内容复制到新的数组里面去:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { @SuppressWarnings("unchecked") T[] copy = ((Object)newType == (Object)Object[].class) ? (T[]) new Object[newLength] : (T[]) Array.newInstance(newType.getComponentType(), newLength); System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; }
用一张图来表示是这样的:
3.删除元素
ArrayList支持两种删除方式:
(1)按照下标删除
(2)按照元素删除,这会删除ArrayList中与指定要删除的元素匹配的第一个元素
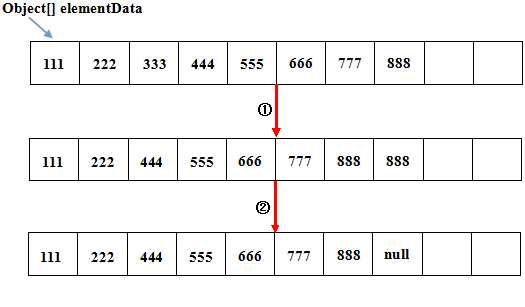
对于ArrayList的删除操作,其实做的就两件事:
(1)把指定元素后面位置的所有元素,利用System.arraycopy方法整体向前移动一个位置
(2)最后一个位置的元素指定为null,这样让GC可以去回收它
比如下面的一段代码:
public static void main(String[] args) { List<String> list = new ArrayList<String>(); list.add("111"); list.add("222"); list.add("333"); list.add("444"); list.add("555"); list.add("666"); list.add("777"); list.add("888"); list.remove("333"); }
用图表示是这样的:
ArrayList的优缺点
从上面的分析来总结一下ArrayList的优缺点,ArrayList的优点如下:
1.ArrayList底层以数组实现,是一种随机访问模式,再加上它实现了RandomAccess接口,因此查找也就是get的时候非常快
2.ArrayList在末尾添加元素的时候非常方便(也就是add(E e)),只是忘数组里面添加了一个元素而已
ArrayList的缺点:
1.删除元素的时候,涉及到一次元素复制,如果复制的元素很多,那么就会比较耗费性能
2.插入指定位置的元素的时候,涉及到一次元素复制,如果要复制的元素很多,那么就会比较耗费性能
因此,ArrayList比较适合顺序添加、随机访问的场景。
为什么elementData是用transient修饰的?
ArrayList的数组,是这样定义的:
transient Object[] elementData;
ArrayList实现了Serializable接口,这意味着ArrayList是可以被序列化的,用transient修饰elementData意味着并不希望elementData数组被序列化。这是为什么?
因为序列化ArrayList的时候,ArrayList里面的elementData未必是满的,比如说elementData有10的大小,但是我们只是用了其中的3个,那么是否有必要序列化整个elementData呢?显然是没有这个必要的,因此ArrayList中重写了writeObject方法:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff int expectedModCount = modCount; s.defaultWriteObject(); // Write out size as capacity for behavioural compatibility with clone() s.writeInt(size); // Write out all elements in the proper order. for (int i=0; i<size; i++) { s.writeObject(elementData[i]); } if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } }
每次序列化的时候调用这个方法,先调用defaultWriteObject()方法序列化ArrayList中的非transient元素,elementData不去序列化它,然后遍历elementData,只序列化那些有的元素,这样:
1、加快了序列化的速度
2、减小了序列化之后的文件大小
不失为一种聪明的做法,如果以后开发过程中有遇到这种情况,也是值得学习、借鉴的一种思路。
以上是关于ArrayList的主要内容,如果未能解决你的问题,请参考以下文章