keepalived,heartbeat,lvs,haproxy
Posted kingle-study
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了keepalived,heartbeat,lvs,haproxy相关的知识,希望对你有一定的参考价值。
一, keeplived @
keepalived是集群管理中保证集群高可用的一个服务软件
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。
keepalived只有一个配置文件keepalived.conf,里面主要包括以下几个配置区域,
分别是global_defs、static_ipaddress、static_routes、vrrp_script、vrrp_instance和
virtual_server。
配置文件实例:


1 global_defs { 2 notification_email { #故障发生时给谁发邮件通知。 3 [email protected] 4 [email protected] 5 ... 6 } 7 notification_email_from [email protected] #通知邮件从哪个地址发出。 8 smtp_server smtp.abc.com #通知邮件的smtp地址。 9 smtp_connect_timeout 30 # 连接smtp服务器的超时时间。 10 enable_traps #连接smtp服务器的超时时间。 11 router_id host163 #标识本节点的字条串,通常为hostname,但不一定非得是hostname。故障发生时,邮件通知会用到。 12 } 13 14 15 static_ipaddress { 16 10.210.214.163/24 brd 10.210.214.255 dev eth0 配置的是是本节点的IP和路由信息 17 ... 18 } 19 20 21 static_routes { 22 10.0.0.0/8 via 10.210.214.1 dev eth0 配置的是是本节点的IP和路由信息 23 ... 24 } 25 26 vrrp_script chk_http_port { #用来做健康检查的,当时检查失败时会将vrrp_instance的priority减少相应的值。 27 28 script "</dev/tcp/127.0.0.1/80" 29 interval 1 30 weight -10 31 } 32 33 34 vrrp_sync_group VG_1 { 35 group { 36 inside_network # name of vrrp_instance (below) 37 outside_network # One for each moveable IP. 38 ... 39 } 40 notify_master /path/to_master.sh #分别表示切换为主/备/出错时所执行的脚本 41 notify_backup /path/to_backup.sh 42 notify_fault "/path/fault.sh VG_1" 43 notify /path/notify.sh 44 smtp_alert 表示是否开启邮件通知 45 } 46 vrrp_instance VI_1 { 47 state MASTER #可以是MASTER或BACKUP,不过当其他节点keepalived启动时会将priority比较大的节点选 举为MASTER,因此该项其实没有实质用途。 48 interface eth0 #节点固有IP(非VIP)的网卡,用来发VRRP包。 49 use_vmac <VMAC_INTERFACE> #是否使用VRRP的虚拟MAC地址。 50 dont_track_primary $#忽略VRRP网卡错误 51 track_interface { #监控以下网卡,如果任何一个不通就会切换到FALT状态 52 eth0 53 eth1 54 } 55 mcast_src_ip <IPADDR> #修改vrrp组播包的源地址,默认源地址为master的IP。(由于是组播,因此即使修改了源地址,该master还是能收到回应的) 56 lvs_sync_daemon_interface eth1 #绑定lvs syncd的网卡。 57 garp_master_delay 10 #当切为主状态后多久更新ARP缓存,默认5秒 58 virtual_router_id 1 #取值在0-255之间,用来区分多个instance的VRRP组播。 59 priority 100 #用来选举master的,要成为master,那么这个选项的值最好高于其他机器50个点,该项取值范围是1-255(在此范围之外会被识别成默认值100) 60 advert_int 1 #发VRRP包的时间间隔,即多久进行一次master选举(可以认为是健康查检时间间隔)。 61 authentication { #认证区域,认证类型有PASS和HA(IPSEC),推荐使用PASS(密码只识别前8位)。 62 auth_type PASS 63 auth_pass 12345678 64 } 65 virtual_ipaddress { 66 10.210.214.253/24 brd 10.210.214.255 dev eth0 67 192.168.1.11/24 brd 192.168.1.255 dev eth1 68 } 69 virtual_routes { #虚拟路由,当IP漂过来之后需要添加的路由信息。 70 172.16.0.0/12 via 10.210.214.1 71 192.168.1.0/24 via 192.168.1.1 dev eth1 72 default via 202.102.152.1 73 } 74 track_script { 脚本 75 chk_http_port 76 } 77 nopreempt #允许一个priority比较低的节点作为master,即使有priority更高的节点启动 78 preempt_delay 300 #启动多久之后进行接管资源(VIP/Route信息等),并提是没有nopreempt选项。 79 debug 80 notify_master <STRING>|<QUOTED-STRING> 81 notify_backup <STRING>|<QUOTED-STRING> 82 notify_fault <STRING>|<QUOTED-STRING> 83 notify <STRING>|<QUOTED-STRING> 84 smtp_alert 85 }
二,heartbeat @
作用: 通过它可以将资源(IP及程序服务等资源)从一台故障计算机快速转移到另一台运转正常的机器继续提供服务,在实际生产应用场景中,heartbeat的功能和另一个高可用开源软件keepalived有很多相同之处。
原理:
集群成员一致性管理模块(CCM)用于管理集群节点成员,同时管理成员之间的关系和节点间资源的分配,
heartbeat模块负责检测主次节点的运行状态,以判断节点是否失效。ha-logd模块用于记录集群中所有
模块和服务的运行信息。 本地资源管理器(LRM)负责本地资源的启动,停止和监控,一般由LRM守护进程lrmd和节点监控
进程(Stonith Daemon)组成,lrmd守护进程负责节点间的通信,Stonith Daemon通常是一个Fence
设备,主要用于监控节点状态,当一个节点出现问题时处于正常状态的节点会通过Fence设备将其重启
或关机以释放IP、磁盘等资源,始终保持资源被一个节点拥有,防止资源争用的发生。 集群资源管理模块(CRM)用于处理节点和资源之间的依赖关系,同时,管理节点对资源的使用,
一般由CRM守护进程crmd、集群策略引擎和集群转移引擎三个部分组成,
集群策略引擎(Cluster policy engine)具体实施这些管理和依赖,
集群转移引擎(Cluster transition engine)监控CRM模块的状态,当一个节点出现故障时,
负责协调另一个节点上的进程进行合理的资源接管。 在Heartbeat集群中,最核心的是heartbeat模块的心跳监测部分和集群资源管理模块的资源接管部分,
心跳监测一般由串行接口通过串口线来实现,两个节点之间通过串口线相互发送报文来告诉对方
自己当前的状态,如果在指定的时间内未受到对方发送的报文,那么就认为对方失效,这时资源接管模块
将启动,用来接管运行在对方主机上的资源或者服务。 Heartbeat仅仅是个HA软件,它仅能完成心跳监控和资源接管,不会监视它控制的资源或应用程序,
要监控资源和应用程序是否运行正常,必须使用第三方的插件,例如ipfail、Mon、Ldirector等。
Heartbeat自身包含了几个插件,分别是ipfail、Stonith和Ldirectord,介绍如下: ipfail的功能直接包含在Heartbeat里面,主要用于检测网络故障,并作出合理的反应,为了实现
这个功能,ipfail使用ping节点或者ping节点组来检测网络连接是否出现故障,从而及时的做出转移措施
。 Stonith插件可以在一个没有响应的节点恢复后,合理接管集群服务资源,防止数据冲突,
当一个节点失效后,会从集群中删除,如果不使用Stonith插件,那么失效的节点可能会导致集群服务
在多于一个节点运行,从而造成数据冲突甚至是系统崩溃。因此,使用Stonith插件可以保证共享存储
环境中的数据完整性。 Ldirector是一个监控集群服务节点运行状态的插件。Ldirector如果监控到集群节点中某个服务
出现故障,就屏蔽此节点的对外连接功能,同时将后续请求转移到正常的节点提供服务,这个插件经常用
在LVS负载均衡集群中。
通过修改配置文件,指定哪一台Heartbeat服务器作为主服务器,则另一台将自动成为备份服务器
。然后在指定备份服务器上配置Heartbeat守护进程来监听来自主服务器的心跳。如果备份服务器在
指定时间内未监听到来自主服务器的心跳,就会启动故障转移程序,并取得主服务器上的相关资源服务
所有权,接替主服务器继续不间断的提供服务,从而达到资源服务高可用性的目的。 keepalived主要控制IP飘移,配置应用简单,而且分层,layer3,4,5,各自配置极为简单。
heartbeat不但可以控制IP飘移,更擅长对资源服务的控制,配置,应用比较复杂。lvs的高可用建议
用keepavlived;业务的高可用用heartbeat。
配置文件说明:
debugfile /var/log/ha-debug #用于记录heartbeat的调试信息 logfile /var/log/ha-log #用于记录heartbeat的日志信息 logfacility local0 #系统日志级别 keepalive 2 #设定心跳(监测)间隔时间,默认单位为秒 warntime 10 ##警告时间,通常为deadtime时间的一半 deadtime 30 # 超出30秒未收到对方节点的心跳,则认为对方已经死亡 initdead 120 #网络启动时间,至少为deadtime的两倍。 hopfudge 1 #可选项:用于环状拓扑结构,在集群中总共跳跃节点的数量 udpport 694 #使用udp端口694 进行心跳监测 ucast eth1 192.168.9.6 #采用单播,进行心跳监测,IP为对方主机IP auto_failback on #on表示当拥有该资源的属主恢复之后,资源迁移到属主上 node srv5.localdomain #设置集群中的节点,节点名须与uname –n相匹配 node srv6.localdomain #节点2 ping 192.168.8.2 192.168.9.7 #ping集群以外的节点,这里是网关和另一台机器,用于检测网络的连接性 respawn root /usr/lib/heartbeat/ipfail apiauth ipfail gid=root uid=root #设置所指定的启动进程的权限
认证文件authkeys:
用于配置心跳的加密方式,该文件主要是用于集群中两个节点的认证,采用的算法和密钥在集群 中节点上必须相同,目前提供了3种算法:md5,sha1和crc。其中crc不能够提供认证,它只能 够用于校验数据包是否损坏,而sha1,md5需要一个密钥来进行认证。
三, haproxy
四,LVS
五,联系
01,keepalived+haproxy+web
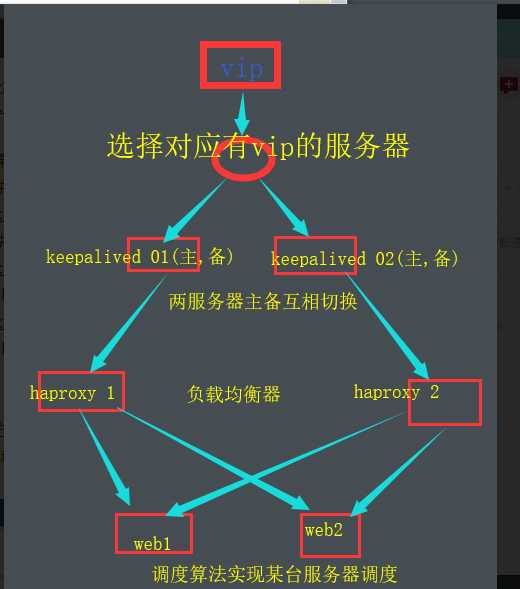
02,keepalived+lvs+web
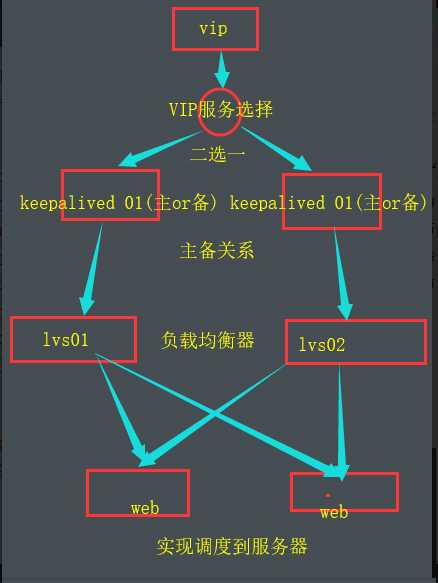
03, heartbeat+haproxy+web
后续其实相差无几
主要是haproxy与lvs
lvs的是通过vrrp协议进行数据包转发的,提供的是4层的负载均衡。特点是效率高,机器网卡比较吃的紧张。
haproxy可以提供4层或7层的数据转发服务,能做到7层的好处是可以根据服务所处的状态等进行负载。
1、 抗负载能力强,因为lvs工作方式的逻辑是非常之简单,而且工作在网络4层仅做请求分发之用,没有流量,所以在效率上基本不需要太过考虑。在我手里的 lvs,仅仅出过一次问题:在并发最高的一小段时间内均衡器出现丢包现象,据分析为网络问题,即网卡或linux2.4内核的承载能力已到上限,内存和 cpu方面基本无消耗。
2、配置性低,这通常是一大劣势,但同时也是一大优势,因为没有太多可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率
3、工作稳定,因为其本身抗负载能力很强,所以稳定性高也是顺理成章,另外各种lvs都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,lvs会自动判别,所以系统整体是非常稳定的。
4、无流量,上面已经有所提及了。lvs仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的IO性能不会受到大流量的影响。
5、基本上能支持所有应用,因为lvs工作在4层,所以它可以对几乎所有应用做负载均衡,包括http、数据库、聊天室等等。
1,HAProxy支持TCP协议的负载均衡转发,可以对mysql读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,大家可以用LVS+Keepalived对MySQL主从做负载均衡。
2,支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态
3,HAProxy负载均衡策略非常多,HAProxy的负载均衡算法现在具体有如下8种:
② static-rr,表示根据权重,建议关注;
③ leastconn,表示最少连接者先处理,建议关注;
④ source,表示根据请求源IP,这个跟nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注;
⑤ ri,表示根据请求的URI;
⑥ rl_param,表示根据请求的URl参数’balance url_param’ requires an URL parameter name;
⑦ hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
⑧ rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
三大负载均衡器特点:
LVS的特点是:
1、抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生;
2、配置性比较低,这是一个缺点也是一个优点,因为没有可太多配置的东西,所以并不需要太多接触,大大减少了人为出错的几率;
3、工作稳定,自身有完整的双机热备方案;
4、无流量,保证了均衡器IO的性能不会收到大流量的影响;
5、应用范围比较广,可以对所有应用做负载均衡;
6、LVS需要向IDC多申请一个IP来做Visual IP,因此需要一定的网络知识,所以对操作人的要求比较高。
Nginx的特点是:
1、工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构;
2、Nginx对网络的依赖比较小;
3、Nginx安装和配置比较简单,测试起来比较方便;
4、也可以承担高的负载压力且稳定,一般能支撑超过1万次的并发;
5、Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点,不过其中缺点就是不支持url来检测;
6、Nginx对请求的异步处理可以帮助节点服务器减轻负载;
7、Nginx能支持http和Email,这样就在适用范围上面小很多;
8、不支持Session的保持、对Big request header的支持不是很好,另外默认的只有Round-robin和IP-hash两种负载均衡算法。
HAProxy的特点是:
1、HAProxy是工作在网络7层之上。
2、能够补充Nginx的一些缺点比如Session的保持,Cookie的引导等工作
3、支持url检测后端的服务器出问题的检测会有很好的帮助。
4、更多的负载均衡策略比如:动态加权轮循(Dynamic Round Robin),加权源地址哈希(Weighted Source Hash),加权URL哈希和加权参数哈希(Weighted Parameter Hash)已经实现
5、单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度。
6、HAProxy可以对Mysql进行负载均衡,对后端的DB节点进行检测和负载均衡
以上是关于keepalived,heartbeat,lvs,haproxy的主要内容,如果未能解决你的问题,请参考以下文章