2018年年终总结
Posted boanxin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2018年年终总结相关的知识,希望对你有一定的参考价值。
2018年年终总结
一,概述
2018年已经结束,2019已经到来,正所谓“一笔狗销,猪事顺利”,作为一个技术人员,这一年真是不平凡的一年,也是受益匪浅的一年。无论技术还是其他都有一些见识和认识 这使我很欣慰。然而今天只说工作,只说编码,只说技术,只说大数据。本是开发出身的我,有幸进入的某个央企的大数据实时计算项目。从开发到测试,从测试到运维,总运维到架构。有些像hadoop生态结构,多的眼花缭乱。死记硬背不是上策,消化不良就受内伤了。慢慢消化循序渐进脚踏实地才是王道,这也是我写这个年终总结的初衷。
二,技术综述
2018年技术大事记,按照时间排序:
1,KAFKA的客户端producer 和 consumer 优化。
2,HADOOP之HBASE的备份以及优化。
3,KERBEROS的部署和使用。
4,SQOOP,HIVE,presto,impala 测试和验证。
下面详细介绍一些上述的功能和设计,在此过程,我尽量回忆使用正确的语言加以描述整个优化的过程,当然伴随一些业务需求的描述。
三,KAFKA的客户端producer和consumer
kafka我们已经使用2年了,目前只是使用到0.9.0版本。作为采集层这是一个很好的工具,正如所说:分布式、可划分的、冗余备份的持久性日志服务,他的特点:发布订阅模型、动态伸缩的高性能消息处理、持久化数据。这里我们着重讲解生产客户端和消费客户端以及 优化。
生产发送过程图如下所示:
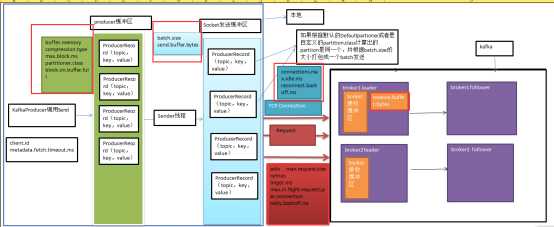
在生产produce端,有些业务特点是:发送数据慢、一条数据量大、避免重复。在这个过程中需要注意单条消息大小的限制和batch队列的限制,不然一个队列装不下一条消息,配置参数参考:
broker端:message.max.bytes 接收的一条消息大小限制。
producer端:batch.size RecordBatch的最大容量。默认值是16384(16KB)。如果一个消息体比较大,就要设置大一些。
消费端consumer过程图如下所示:
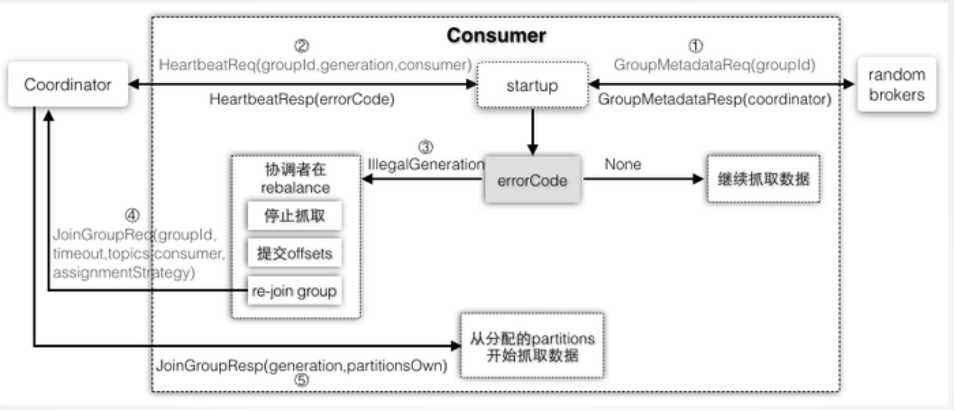
在业务数据消费过程中,遇到如下需求:消息进度跟不上,或者在消费一条数据阻塞卡主。这就需要跳跃式消费。目前所知这是消费者高阶API跳跃式消费的唯一方式,代码如下:
Properties props = new Properties(); props.put("bootstrap.servers", "10.20.49.175:9092,10.20.49.176:9092,10.20.49.177:9092,10.20.49.178:9092,10.20.49.179:9092"); props.put("group.id", "N3S1"); props.put("enable.auto.commit", false);//true是自动提交 false是手动提交 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //反序列化程序类,用于实现Deserializer接口的值。 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); TopicPartition partition0 = new TopicPartition("N3S",9); consumer.assign(Arrays.asList(partition0)); consumer.seek(partition0, 16669); consumer.commitSync(); TopicPartition partition1 = new TopicPartition("N3S",15); consumer.assign(Arrays.asList(partition1)); consumer.seek(partition1, 16677); consumer.commitSync();
四,HADOOP之HBASE的备份和优化
hbase我们已经使用了2年了 。所以数据的重要性不言而喻,这就需要一个非常好的备份策略。我们最终选择了快照备份方法。这个方法备份方便,但是hdfs的数据不能受到不可恢复的破坏。备份脚本为:
第一部分生成执行hbase脚本:
#!/bin/bash
#Name:hbase_snapshot
#This is snapshot of hbase
snapTime=`date +%Y%m%d`
tableNameArr=`echo list|hbase shell|tail -n 1`
tableStr=`echo "$tableNameArr" | sed ‘s/"//g‘ | sed ‘s/[//g‘ | sed ‘s/]//g‘`
echo "$tableStr"
echo "">/zook/hbaseShell/hbase.out
OLD_IFS="$IFS"
IFS=","
arr=($tableStr)
IFS="$OLD_IFS"
for s in ${arr[@]}
do
echo "snapshot ‘$s‘,‘`date +%Y%m%d%H`_snapshot_$s‘" >>/zook/hbaseShell/hbase.out
#echo "snapshot ‘$s‘,‘`date +%Y%m%d%H`_snapshot_$s‘" |hbase shell
#echo "time is ::"`date "+%Y-%m-%d %H:%M:%S"`
#echo "name is ::"`date +%Y%m%d%H`_snapshot_$s
#echo "snapshot ‘$s‘,‘`date -d ‘-1 day‘ +%Y%m%d`_snapshot_$s‘" |hbase shell
#echo `date -d ‘-1 day‘ +%Y%m%d`
done
echo "exit" >>/zook/hbaseShell/hbase.out
第二部分执行备份脚本进行备份:
#!/bin/bash hbase shell /zook/hbaseShell/hbase.out>>/zook/hbaseShell/snapshot.out echo "">/zook/hbaseShell/hbase.out
备份之后的恢复过程:
第一步:把备份的快照传输备份到log-hbase集群
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot $snapName -copy-to hdfs://10.20.49.171:8022/hbase
第二步:初始化hbase集群
停止hbase
删除zookeeper 目录 重启
rmr /hbase
删除 hadoop 目录,并清空回收站数据
举例:hadoop fs -rmr /hbase/data/hbase/meta
启动hbase
第三步:把log-hbase的快照在传输到hbase集群中
第四步:创建表
第五步:恢复数据
Disable ‘tablename’
Restore_snapshot ‘snapshotname’
Enable ‘tablename’
五,KERBEROS的部署和使用
在大数据中安全中,kerberos算是比较突出的一个安全插件了。因为大部分大数据组件都是分布式网络请求为主,所以像kerberos这种网络认证就显得很重要了。kerberos的设计目标就是通过密钥系统统称为客户机/服务器应用程序提供强大的认证服务。该认证过程的实现不依赖于主机操作系统的认证,无需基于主机地址的信任,不要求网络上所有主机的物理安全,并且假定网络上传送的数据包可以被任意的读取、修改和插入数据。在以上情况下,kerberos作为一种可信任的第三方认证服务,是通过传统的密码技术执行认证服务的。认证过程可以参考:
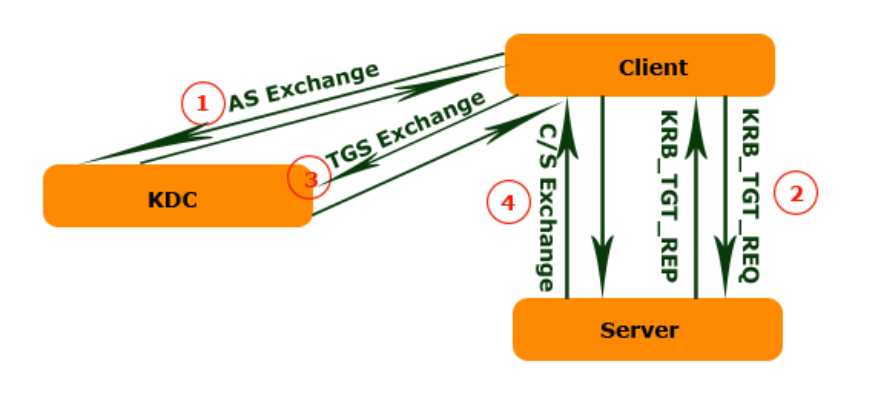
kinit命令使用规范
kinit [ -l lifetime ] [ -r renewable_life ] [ -f ] [ -p ] [ -A ] [ -s start_time ] [ -S target_service ] [ -k [ -t keytab_file ] ] [ -R ] [ -v ] [ -u ] [ -c cachename ] [ principal ]
klist命令使用规范
klist [[ -c] [ -f] [ -e] [ -s] [ -a] [ -n]] [ -k [ -t] [ -K]] [ name]
六,SQOOP,HIVE,presto,impala 测试和验证
这部分主要是测试和验证sqoop,hive,presto和impala的使用。简单部署图:
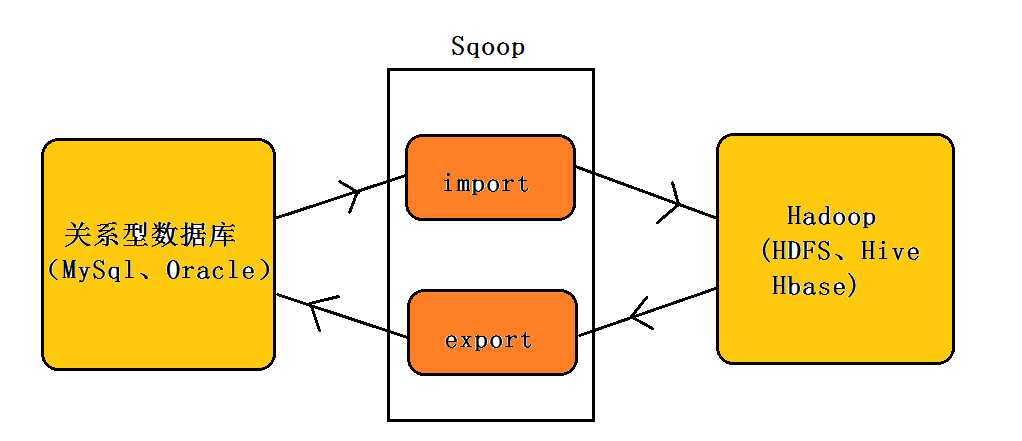
sqoop命令使用:
sqoop import -D mapreduce.job.name=mio_log_txt_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=mio_log --target-dir /user/hive/mio_log3/000005/ --split-by mio_log_id --hive-import -m 20 --hive-database rtcp --hive-table mio_log_txt_test sqoop import -D mapreduce.job.name=std_contract_txt_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=std_contract --target-dir /user/hive/std_contract/000003/ --split-by cntr_id --hive-import -m 5 --hive-database rtcp --hive-table std_contract_txt_test sqoop import -D mapreduce.job.name=customer_txt_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=customer --target-dir /user/hive/customer/000003/ --split-by id_num --hive-import -m 5 --hive-database rtcp --hive-table customer_txt_test sqoop import -D mapreduce.job.name=psn_customer_txt_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=psn_customer --target-dir /user/hive/psn_customer/000003/ --split-by id_num --hive-import -m 5 --hive-database rtcp --hive-table psn_customer_txt_test sqoop import -D mapreduce.job.name=mio_log_parquet_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=mio_log --target-dir /user/hive/mio_log/000001/ --split-by mio_log_id --hive-import --hive-database rtcp --hive-table mio_log_parquet_test -m 40 --delete-target-dir --as-parquetfile sqoop import -D mapreduce.job.name=std_contract_parquet_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=std_contract --target-dir /user/hive/std_contract/000001/ --split-by cntr_id --hive-import --hive-database rtcp --hive-table std_contract_parquet_test -m 10 --delete-target-dir --as-parquetfile sqoop import -D mapreduce.job.name=customer_parquet_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=customer --target-dir /user/hive/customer/000001/ --split-by id_num --hive-import --hive-database rtcp --hive-table customer_parquet_test -m 5 --delete-target-dir --as-parquetfile sqoop import -D mapreduce.job.name=psn_customer_parquet_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=psn_customer --target-dir /user/hive/customer/000001/ --split-by id_num --hive-import --hive-database rtcp --hive-table psn_customer_parquet_test -m 5 --delete-target-dir --as-parquetfile sqoop import -D mapreduce.job.name=mio_log_orc_test --connect ‘jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core‘ --username sa --password Sql2014 --table=mio_log --split-by mio_log_id --hcatalog-database rtcp --hcatalog-table mio_log_orc_test --create-hcatalog-table --hcatalog-storage-stanza "stored as orcfile" -m 20 sqoop import -D mapreduce.job.name=std_contract_orc_test --connect ‘jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core‘ --username sa --password Sql2014 --table=std_contract --split-by cntr_id --hcatalog-database rtcp --hcatalog-table std_contract_orc_test --create-hcatalog-table --hcatalog-storage-stanza "stored as orcfile" -m 20 sqoop import -D mapreduce.job.name=customer_orc_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=customer --split-by id_num --hcatalog-database rtcp --create-hcatalog-table --hcatalog-table customer_orc_test -m 5 --hive-database rtcp --hcatalog-storage-stanza "stored as orcfile" sqoop import -D mapreduce.job.name=psn_customer_orc_test --connect "jdbc:sqlserver://127.0.0.1:1433;database=incrv8_core" --username sa --password Sql2014 --table=psn_customer --split-by id_num --create-hcatalog-table --hcatalog-database rtcp --hcatalog-table psn_customer_orc_test -m 5 --hive-database rtcp --hcatalog-storage-stanza "stored as orcfile"