Kafka 详解------Producer生产者
Posted ysocean
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka 详解------Producer生产者相关的知识,希望对你有一定的参考价值。
在第一篇博客我们了解到一个kafka系统,通常是生产者Producer 将消息发送到 Broker,然后消费者 Consumer 去 Broker 获取,那么本篇博客我们来介绍什么是生产者Producer。
1、生产者概览
我们知道一个系统在运行过程中会有很多消息产生,比如前面说的对于一个购物网站,通常会记录用户的活动,网站的运行度量指标以及一些日志消息等等,那么产生这些消息的组件我们都可以称为生产者。
而对于生产者产生的消息重要程度又有不同,是否都很重要不允许丢失,是否允许丢失一部分?以及是否有严格的延迟和吞吐量要求?
对于这些场景在 Kafka 中会有不同的配置,以及不同的 API 使用。
2、生产者发送消息步骤
下图是生产者向 Kafka 发送消息的主要步骤:
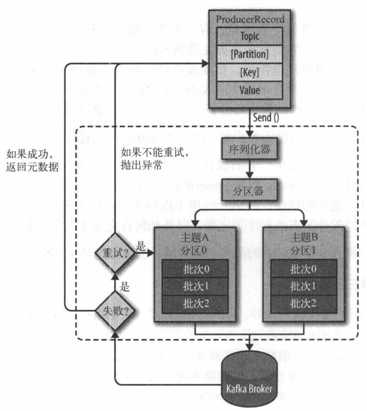
①、首先要构造一个 ProducerRecord 对象,该对象可以声明主题Topic、分区Partition、键 Key以及值 Value,主题和值是必须要声明的,分区和键可以不用指定。
②、调用send() 方法进行消息发送。
③、因为消息要到网络上进行传输,所以必须进行序列化,序列化器的作用就是把消息的 key 和 value对象序列化成字节数组。
④、接下来数据传到分区器,如果之间的 ProducerRecord 对象指定了分区,那么分区器将不再做任何事,直接把指定的分区返回;如果没有,那么分区器会根据 Key 来选择一个分区,选择好分区之后,生产者就知道该往哪个主题和分区发送记录了。
⑤、接着这条记录会被添加到一个记录批次里面,这个批次里所有的消息会被发送到相同的主题和分区。会有一个独立的线程来把这些记录批次发送到相应的 Broker 上。
③、Broker成功接收到消息,表示发送成功,返回消息的元数据(包括主题和分区信息以及记录在分区里的偏移量)。发送失败,可以选择重试或者直接抛出异常。
3、Java Producer API
首先在POM 文件中导入 kafka client。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
实例代码:
1 package com.ys.utils; 2 3 import org.apache.kafka.clients.producer.*; 4 import java.util.Properties; 5 6 /** 7 * Create by YSOcean 8 */ 9 public class KafkaProducerUtils { 10 11 public static void main(String[] args) { 12 Properties kafkaProperties = new Properties(); 13 //配置broker地址信息 14 kafkaProperties.put("bootstrap.servers", "192.168.146.200:9092,192.168.146.201:9092,192.168.146.202:9092"); 15 //配置 key 的序列化器 16 kafkaProperties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); 17 //配置 value 的序列化器 18 kafkaProperties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); 19 20 //通过上面的配置文件生成 Producer 对象 21 Producer producer = new KafkaProducer(kafkaProperties); 22 //生成 ProducerRecord 对象,并制定 Topic,key 以及 value 23 ProducerRecord<String,String> record = 24 new ProducerRecord<String, String>("testTopic","key1","hello Producer"); 25 //发送消息 26 producer.send(record); 27 } 28 }
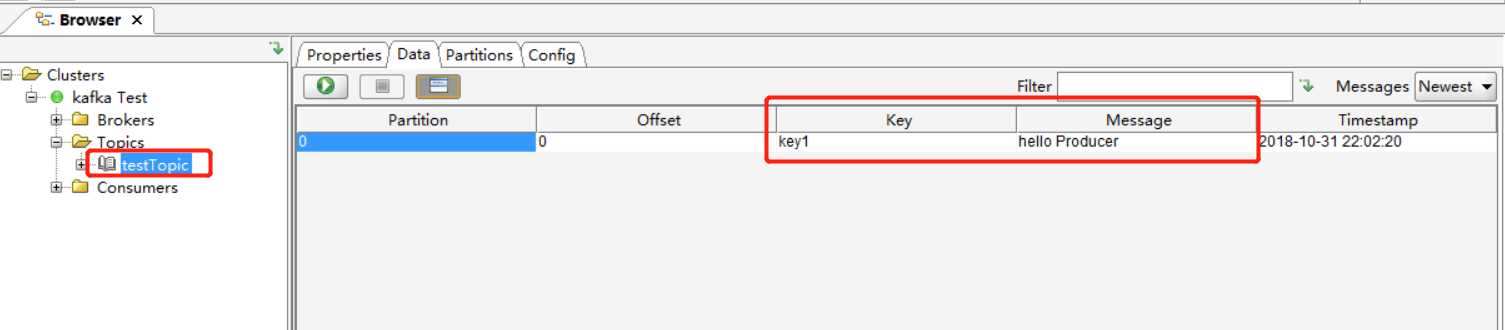
通过运行上述代码,我们向名为 testTopic 的主题中发送了一条键为 key1,值为 hello Producer 的消息。
4、属性配置
在上面的实例中,我们配置了如下三个属性:
①、bootstrap.servers:该属性指定 brokers 的地址清单,格式为 host:port。清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找到其它 broker 的信息。——建议至少提供两个 broker 的信息,因为一旦其中一个宕机,生产者仍然能够连接到集群上。
②、key.serializer:将 key 转换为字节数组的配置,必须设定为一个实现了 org.apache.kafka.common.serialization.Serializer 接口的类,生产者会用这个类把键对象序列化为字节数组。——kafka 默认提供了 StringSerializer和 IntegerSerializer、ByteArraySerializer。当然也可以自定义序列化器。
③、value.serializer:和 key.serializer 一样,用于 value 的序列化。
以上三个属性是必须要配置的,下面还有一些别的属性可以不用配置,默认。
④、acks:此配置指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的,这个参数保障了消息发送的可靠性。默认值为 1。
一、acks=0。生产者不会等待服务器的反馈,该消息会被立刻添加到 socket buffer 中并认为已经发送完成。也就是说,如果发送过程中发生了问题,导致服务器没有接收到消息,那么生产者也无法知道。在这种情况下,服务器是否收到请求是没法保证的,并且参数retries也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。好处就是由于生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
二、acks=1。只要集群首领收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法到达首领节点(比如首领节点崩溃,新首领还没有被选举出来),生产者会收到一个错误的响应,为了避免丢失消息,生产者会重发消息(根据配置的retires参数确定重发次数)。不过如果一个没有收到消息的节点成为首领,消息还是会丢失,这个时候的吞吐量取决于使用的是同步发送还是异步发送。
三、acks=all。只有当集群中参与复制的所有节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。这种模式是最安全的,但是延迟最高。
⑤、buffer.memory:该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。默认值为33554432 字节。如果应用程序发送消息的速度超过发送到服务器的速度,那么会导致生产者内存不足。这个时候,send() 方法会被阻塞,如果阻塞的时间超过了max.block.ms (在kafka0.9版本之前为block.on.buffer.full 参数)配置的时长,则会抛出一个异常。
⑥、compression.type:该参数用于配置生产者生成数据时可以压缩的类型,默认值为 none(不压缩)。还可以指定snappy、gzip或lz4等类型,snappy 压缩算法占用较少的 CPU,gzip 压缩算法占用较多的 CPU,但是压缩比最高,如果网络带宽比较有限,可以使用该算法,使用压缩可以降低网络传输开销和存储开销,这往往是 kafka 发送消息的瓶颈所在。
⑦、retires:该参数用于配置当生产者发送消息到服务器失败,服务器返回错误响应时,生产者可以重发消息的次数,如果达到了这个次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms,可以通过 retry.backoff.on 参数来改变这个时间间隔。
还有一些属性配置,可以参考官网:http://kafka.apachecn.org/documentation.html#producerconfigs
5、序列化器
前面我们介绍过,消息要到网络上进行传输,必须进行序列化,而序列化器的作用就是如此。
①、默认序列化器
Kafka 提供了默认的字符串序列化器(org.apache.kafka.common.serialization.StringSerializer),还有整型(IntegerSerializer)和字节数组(BytesSerializer)序列化器,这些序列化器都实现了接口(org.apache.kafka.common.serialization.Serializer)基本上能够满足大部分场景的需求。
下面是Kafka 实现的字符串序列化器 StringSerializer:


// // Source code recreated from a .class file by IntelliJ IDEA // (powered by Fernflower decompiler) // package org.apache.kafka.common.serialization; import java.io.UnsupportedEncodingException; import java.util.Map; import org.apache.kafka.common.errors.SerializationException; public class StringSerializer implements Serializer<String> { private String encoding = "UTF8"; public StringSerializer() { } public void configure(Map<String, ?> configs, boolean isKey) { String propertyName = isKey ? "key.serializer.encoding" : "value.serializer.encoding"; Object encodingValue = configs.get(propertyName); if (encodingValue == null) { encodingValue = configs.get("serializer.encoding"); } if (encodingValue instanceof String) { this.encoding = (String)encodingValue; } } public byte[] serialize(String topic, String data) { try { return data == null ? null : data.getBytes(this.encoding); } catch (UnsupportedEncodingException var4) { throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + this.encoding); } } public void close() { } }
其中接口 serialization:
1 // 2 // Source code recreated from a .class file by IntelliJ IDEA 3 // (powered by Fernflower decompiler) 4 // 5 6 package org.apache.kafka.common.serialization; 7 8 import java.io.Closeable; 9 import java.util.Map; 10 11 public interface Serializer<T> extends Closeable { 12 void configure(Map<String, ?> var1, boolean var2); 13 14 byte[] serialize(String var1, T var2); 15 16 void close(); 17 }
②、自定义序列化器
如果Kafka提供的几个默认序列化器不能满足要求,即发送到 Kafka 的消息不是简单的字符串或整型,那么我们可以自定义序列化器。
比如对于如下的实体类 Person:
1 package com.ys.utils; 2 3 /** 4 * Create by YSOcean 5 */ 6 public class Person { 7 private String name; 8 private int age; 9 10 public String getName() { 11 return name; 12 } 13 14 public void setName(String name) { 15 this.name = name; 16 } 17 18 public int getAge() { 19 return age; 20 } 21 22 public void setAge(int age) { 23 this.age = age; 24 } 25 }
我们自定义一个 PersonSerializer:
1 package com.ys.utils; 2 3 import org.apache.kafka.common.serialization.Serializer; 4 5 import java.io.UnsupportedEncodingException; 6 import java.nio.ByteBuffer; 7 import java.util.Map; 8 9 /** 10 * Create by YSOcean 11 */ 12 public class PersonSerializer implements Serializer<Person> { 13 14 @Override 15 public void configure(Map map, boolean b) { 16 //不做任何配置 17 } 18 19 @Override 20 /** 21 * Person 对象被序列化成: 22 * 表示 age 的4 字节整数 23 * 表示 name 长度的 4 字节整数(如果为空,则长度为0) 24 * 表示 name 的 N 个字节 25 */ 26 public byte[] serialize(String topic, Person data) { 27 if(data == null){ 28 return null; 29 } 30 byte[] name; 31 int stringSize; 32 try { 33 if(data.getName() != null){ 34 name = data.getName().getBytes("UTF-8"); 35 stringSize = name.length; 36 }else{ 37 name = new byte[0]; 38 stringSize = 0; 39 } 40 ByteBuffer buffer = ByteBuffer.allocate(4+4+stringSize); 41 buffer.putInt(data.getAge()); 42 buffer.putInt(stringSize); 43 buffer.put(name); 44 return buffer.array(); 45 } catch (UnsupportedEncodingException e) { 46 e.printStackTrace(); 47 } 48 return new byte[0]; 49 } 50 51 @Override 52 public void close() { 53 //不需要关闭任何东西 54 } 55 }
上面例子序列化将Person类的 age 属性序列化为 4 个字节,后期如果该类发生更改,变为长整型 8 个字节,那么可能会存在新旧消息兼容性问题。
因此通常不建议自定义序列化器,可以使用下面介绍的已有的序列化框架。
③、序列化框架
上面我们知道自定义序列化器可能会存在新旧消息兼容性问题,需要我们手动去维护,那么为了省去此麻烦,我们可以使用一些已有的序列化框架。比如 JSON、Avro、Thrift 或者 Protobuf。
6、发送消息 send()
①、普通发送——发送就忘记
//1、通过上面的配置文件生成 Producer 对象 Producer producer = new KafkaProducer(kafkaProperties); //2、生成 ProducerRecord 对象,并制定 Topic,key 以及 value //创建名为testTopic的队列,键为testkey,值为testValue的ProducerRecord对象 ProducerRecord<String,String> record = new ProducerRecord<>("testTopic","testkey","testValue"); //3、发送消息 producer.send(record);
通过配置文件构造一个生产者对象 producer,然后指定主题名称,键值对,构造一个 ProducerRecord 对象,最后使用生产者Producer 的 send() 方法发送 ProducerRecord 对象,send() 方法会返回一个包含 RecordMetadata 的 Future 对象,不过通常我们会忽略返回值。
和上面的名字一样——发送就忘记,生产者只管发送,并不管发送的结果是成功或失败。通常如果我们不关心发送结果,那么就可以使用此种方式。
②、同步发送
//1、通过上面的配置文件生成 Producer 对象 Producer producer = new KafkaProducer(kafkaProperties); //2、生成 ProducerRecord 对象,并制定 Topic,key 以及 value //创建名为testTopic的队列,键为testkey,值为testValue的ProducerRecord对象 ProducerRecord<String,String> record = new ProducerRecord<>("testTopic","testkey","testValue"); //3、同步发送消息 try { //通过send()发送完消息后返回一个Future对象,然后调用Future对象的get()方法等待kafka响应 //如果kafka正常响应,返回一个RecordMetadata对象,该对象存储消息的偏移量 //如果kafka发生错误,无法正常响应,就会抛出异常,我们便可以进行异常处理 producer.send(record).get(); } catch (Exception e) { //4、异常处理 e.printStackTrace(); }
和上面普通发送消息一样,只不过这里我们调用了 Future 对象的 get() 方法来等待 kafka 服务器的响应,程序运行到这里会产生阻塞,直到获取kafka集群的响应。而这个响应有两种情况:
1、正常响应:返回一个 RecordMetadata 对象,通过该对象我们能够获取消息的偏移量、分区等信息。
2、异常响应:基本上来说会发生两种异常,
一类是可重试异常,该错误可以通过重发消息来解决。比如连接错误,可以通过再次连接后继续发送上一条未发送的消息;再比如集群没有首领(no leader),因为我们知道集群首领宕机之后,会有一个时间来进行首领的选举,如果这时候发送消息,肯定是无法发送的。
二类是无法重试异常,比如消息太大异常,对于这类异常,KafkaProducer 不会进行任何重试,直接抛出异常。
同步发送消息适合需要保证每条消息的发送结果,优点是能够精确的知道什么消息发送成功,什么消息发送失败,而对于失败的消息我们也可以采取措施进行重新发送。缺点则是增加了每条消息发送的时间,当发送消息频率很高时,此种方式便不适合了。
③、异步发送
有同步发送,基本上就会有异步发送了。同步发送每发送一条消息都得等待kafka服务器的响应,之后才能发送下一条消息,那么我们不是在错误产生时马上处理,而是记录异常日志,然后马上发送下一条消息,而这个异常再通过回调函数去处理,这就是异步发送。
1、首先我们要实现一个继承 org.apache.kafka.clients.producer.Callback 接口,然后实现其唯一的 onCompletion 方法。
package com.ys.utils; import org.apache.kafka.clients.producer.Callback; import org.apache.kafka.clients.producer.RecordMetadata; /** * Create by YSOcean */ public class KafkaCallback implements Callback{ @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e != null){ //异常处理 e.printStackTrace(); } } }
2、发送消息时,传入这个回调类。
//异步发送消息 producer.send(record,new KafkaCallback());
以上是关于Kafka 详解------Producer生产者的主要内容,如果未能解决你的问题,请参考以下文章