MapReduce基础
Posted zhouhb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce基础相关的知识,希望对你有一定的参考价值。
1. WordCount程序
1.1 WordCount源程序
import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public WordCount() { } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs(); if(otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCount.TokenizerMapper.class); job.setCombinerClass(WordCount.IntSumReducer.class); job.setReducerClass(WordCount.IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true)?0:1); } public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); public TokenizerMapper() { } public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while(itr.hasMoreTokens()) { this.word.set(itr.nextToken()); context.write(this.word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public IntSumReducer() { } public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; IntWritable val; for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) { val = (IntWritable)i$.next(); } this.result.set(sum); context.write(key, this.result); } } }
1.2 运行程序,Run As->Java Applicatiion
1.3 编译打包程序,产生Jar文件
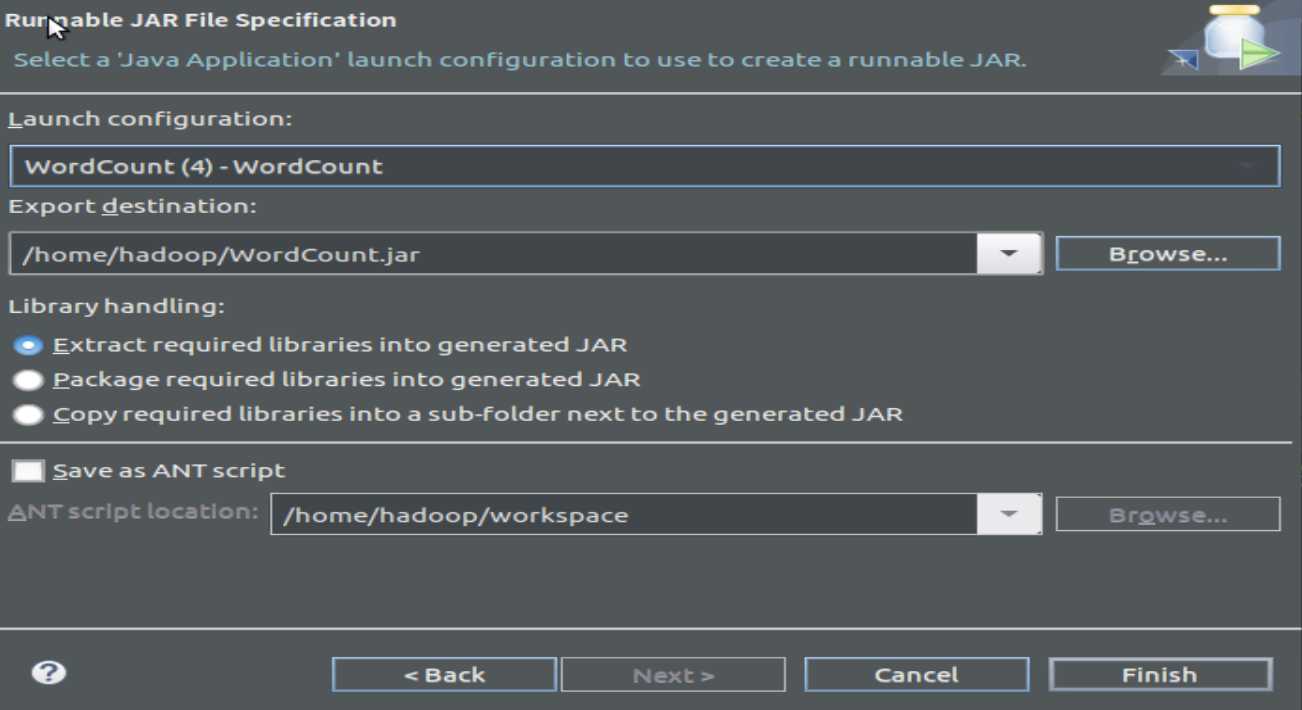
2 运行程序
2.1 建立要统计词频的文本文件
wordfile1.txt
Spark Hadoop
Big Data
wordfile2.txt
Spark Hadoop
Big Cloud
2.2 启动hdfs,新建input文件夹,上传词频文件
cd /usr/local/hadoop/
./sbin/start-dfs.sh
./bin/hadoop fs -mkdir input
./bin/hadoop fs -put /home/hadoop/wordfile1.txt input
./bin/hadoop fs -put /home/hadoop/wordfile2.txt input
2.3 查看已上传的词频文件:
[email protected]:/usr/local/hadoop$ ./bin/hadoop fs -ls .
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2019-02-11 15:40 input
-rw-r--r-- 1 hadoop supergroup 5 2019-02-10 20:22 test.txt
[email protected]:/usr/local/hadoop$ ./bin/hadoop fs -ls ./input
Found 2 items
-rw-r--r-- 1 hadoop supergroup 27 2019-02-11 15:40 input/wordfile1.txt
-rw-r--r-- 1 hadoop supergroup 29 2019-02-11 15:40 input/wordfile2.txt
2.4 运行WordCount
./bin/hadoop jar /home/hadoop/WordCount.jar input output
屏幕上会输入大段信息
然后可以查看运行结果:
[email protected]:/usr/local/hadoop$ ./bin/hadoop fs -cat output/*
Hadoop 2
Spark 2
---
以上是关于MapReduce基础的主要内容,如果未能解决你的问题,请参考以下文章