最新的爬虫工具requests-html
Posted zhouxinfei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新的爬虫工具requests-html相关的知识,希望对你有一定的参考价值。
使用Python开发的同学一定听说过Requsts库,它是一个用于发送HTTP请求的测试。如比我们用Python做基于HTTP协议的接口测试,那么一定会首选Requsts,因为它即简单又强大。现在作者Kenneth Reitz 又开发了requests-html 用于做爬虫。
GiHub项目地址:
https://github.com/kennethreitz/requests-html
requests-html 是基于现有的框架 PyQuery、Requests、lxml、beautifulsoup4等库进行了二次封装,作者将Requests设计的简单强大的优点带到了该项目中。
安装:
pip install requests-html
先来看看requests的基本使用。
from requests_html import HTMLSession
session = HTMLSession()
r = session.get(‘https://python.org/‘)
# 获取页面上的所有链接。
all_links = r.html.links
print(all_links)
# 获取页面上的所有链接,以绝对路径的方式。
all_absolute_links = r.html.absolute_links
print(all_absolute_links)
- 小试牛刀
作为一个IT技术人员,是不是要时时关心一下科技圈的新闻,上博客园新闻频道,抓取最新的推荐新闻。
from requests_html import HTMLSession
session = HTMLSession()
r = session.get("https://news.cnblogs.com/n/recommend")
# 通过CSS找到新闻标签
news = r.html.find(‘h2.news_entry > a‘, first=True)
for new in news:
print(new.text) # 获得新闻标题
print(new.absolute_links) # 获得新闻链接
执行结果:
外卖小哥击败北大硕士,获《中国诗词大会》冠军!董卿点赞
{‘https://news.cnblogs.com/n/593573/‘}
一图看懂中国科学家如何用“魔法药水”制备干细胞
{‘https://news.cnblogs.com/n/593572/‘}
再见Windows:你曾是我的全部
{‘https://news.cnblogs.com/n/593559/‘}
复盘摩拜卖身美团:美女创始人背后有3个男人
{‘https://news.cnblogs.com/n/593536/‘}
不要把认错当成一种PR!
{‘https://news.cnblogs.com/n/593494/‘}
胡玮炜的胳膊拧不过马化腾的大腿
{‘https://news.cnblogs.com/n/593450/‘}
被废四年奇迹逆转!XP用户竟越来越多
{‘https://news.cnblogs.com/n/593445/‘}
天宫一号:我这一辈子
{‘https://news.cnblogs.com/n/593414/‘}
微软重组的背后:未来属于“微软”,而不只是Windows
{‘https://news.cnblogs.com/n/593375/‘}
低俗、鬼畜受限令出台后,内容原创者的日子会好过点吗?
{‘https://news.cnblogs.com/n/593370/‘}
《头号玩家》:一封献给极客的情书
{‘https://news.cnblogs.com/n/593307/‘}
翻了下Google日语输入法愚人节作品集,这个团队真的超有病…
{‘https://news.cnblogs.com/n/593285/‘}
C++委员会决定在C++20中弃用原始指针
{‘https://news.cnblogs.com/n/593271/‘}
一文读懂阿里收购饿了么:饿了么和美团外卖决战之日到了
{‘https://news.cnblogs.com/n/593261/‘}
刚刚天宫一号坠落 而中国空间站即将腾飞!
{‘https://news.cnblogs.com/n/593248/‘}
小抖怡情适可而止 不要为了博眼球而去做一些危险的事情
{‘https://news.cnblogs.com/n/593238/‘}
拼多多淘宝低价阿胶背后:放马皮牛皮 掺禁用明胶
{‘https://news.cnblogs.com/n/593232/‘}
吴晓波对话刘强东:太保守 让我只能看着机会流走
{‘https://news.cnblogs.com/n/593176/‘}
扩展:我们可以进一步将这里数据做持久化处理,设计出自己的“头条”。
- 小有成就
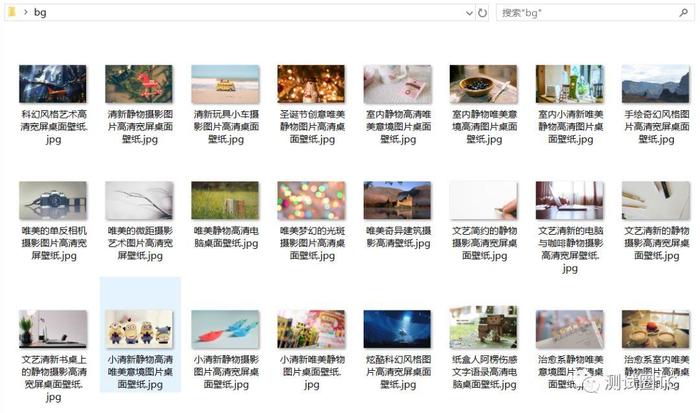
接下来我们到网站上下载壁纸,以美桌网(www.win4000.com)为例。
from requests_html import HTMLSession
import requests
# 保存图片到bg/目录
def save_image(url, title):
img_response = requests.get(url)
with open(‘./bg/‘+title+‘.jpg‘, ‘wb‘) as file:
file.write(img_response.content)
# 背景图片地址,这里选择1920*1080的背景图片
url = "http://www.win4000.com/wallpaper_2358_0_10_1.html"
session = HTMLSession()
r = session.get(url)
# 查找页面中背景图,找到链接,访问查看大图,并获取大图地址
items_img = r.html.find(‘ul.clearfix > li > a‘)
for img in items_img:
img_url = img.attrs[‘href‘]
if "/wallpaper_detail" in img_url:
r = session.get(img_url)
item_img = r.html.find(‘img.pic-large‘, first=True)
url = item_img.attrs[‘src‘]
title = item_img.attrs[‘title‘]
print(url+title)
save_image(url, title)
这个网站上的图片还是很容易获取的,在上面的代码块中我加了注释。这里不再说明。
选择一个CSS选择器的元素:
>>> about = r.html.find(‘#about‘, first=True)
获取元素的文本内容:
>>> print(about.text)
获取元素的属性
>>> about.attrs
{‘id‘: ‘about‘, ‘class‘: (‘tier-1‘, ‘element-1‘), ‘aria-haspopup‘: ‘true‘}
渲染出一个元素的HTML:
>>> about.html
选择元素内的元素:
>>> about.find(‘a‘)
页面上的文本搜索:
>>> r.html.search(‘Python is a {} language‘)[0]
更复杂的CSS选择器的例子(从Chrome开发工具复制):
>>> r = session.get(‘https://github.com/‘)
>>> sel = ‘body > div.application-main > div.jumbotron.jumbotron-codelines > div > div > div.col-md-7.text-center.text-md-left > p‘
>>> print(r.html.find(sel, first=True).text)
它也支持:
>>> r.html.xpath(‘/html/body/div[1]/a‘)
javascript的支持
让我们抓住一些文本呈现的JavaScript:
>>> r = session.get(‘http://python-requests.org‘)
>>> r.html.render()
>>> r.html.search(‘Python 2 will retire in only {months} months!‘)[‘months‘]
‘<time>25</time>‘
注意,当你第一次运行render()方法,它将downloadchromium进入你的家目录(例如~ .pyppeteer / /)。
>>> from requests_html import HTML
>>> doc = """<a href=‘https://httpbin.org‘>"""
>>> html = HTML(html=doc)
>>> html.links
{‘https://httpbin.org‘}
以上是关于最新的爬虫工具requests-html的主要内容,如果未能解决你的问题,请参考以下文章