java--集合框架总结1--set总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java--集合框架总结1--set总结相关的知识,希望对你有一定的参考价值。
一、集合框架的概述。
基础的数据结构有数组,链表,栈,队列,二叉树等,java中的数据结构,利用了这些基本的数据结构分别实现了很丰富的集合框架类型,下面简单地总结下关于java集合框架的基础内容,在进行总结前,先大概看看java中主要的集合组织方式。
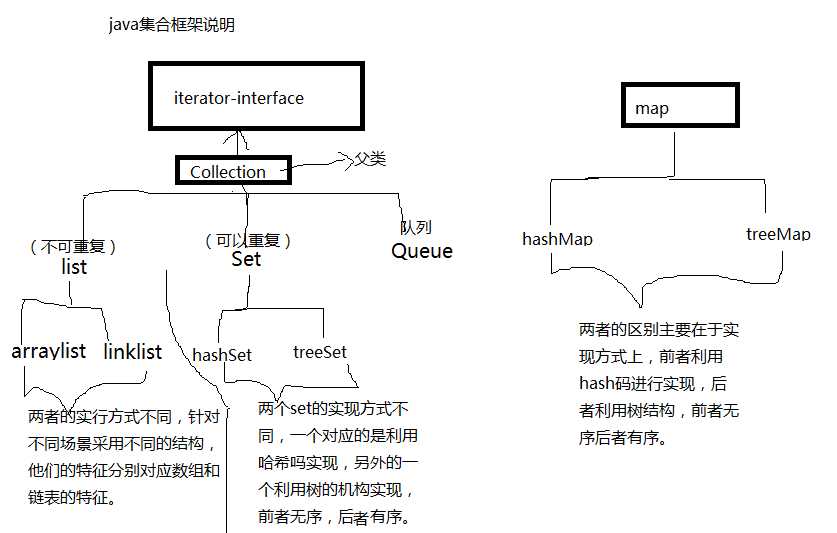
上面这张丑图也基本上说明了集合框架之间的关系,下面首先对set进行简单的总结,期间会稍微涉及到hashCode的一些其他知识。list和map的总结会在之后的博客中
二、 set:不可重复的数据存储结构。
1、hashSet:散列表,无序的数据存储结构.简单介绍下hashCode的概念:在Object中(如果该类没有覆盖hashCode()方法的话)表示某个对象内存的一个映射数字,通过该数字可以找到对应的对象内存块,类似于数据库中的索引的概念,当然有些类会重写hashCode方法,例如字符串,基本类型的封装类等。由于在集合类添加元素(包括但是不限于)等判断两个对象是否一样时我们是利用equals方法比较的,入股equals的比较结果为true,则hashCode也必须相同,这里就要求equals重写了则应该也要重写hashCode,以保证他们的对应关系。
知道了hashCode的概念后,我们就可以大概了解hashSet的原理了:hashSet通过hashCode建立一个索引表,用于储存其内的所有对象的内存位置,add元素进来的时候,通过该表便可以快速地判断元素是否在set内,在取元素的时候,也可以通过该表快速定位对象了,这样可以保证其快速高效地添加和查询元素。
具体的set内部原理大概是这样的:java中会将set的内部存储机构分为多个链表(即链表数组)(我们下面称这些链表为桶),在添加元素时,通过元素的hashCode和桶的个数取余,得到的余数表示了该对象需要装到哪个桶中,只要保证桶数目够多,便可快速定位到该对象所在的位置,当发生hashCode重复时,调用冲突解决算法:该算法将hashCode相同但是eauqls为false的方法放在一个单独的链表中。具体请看下面的丑图:
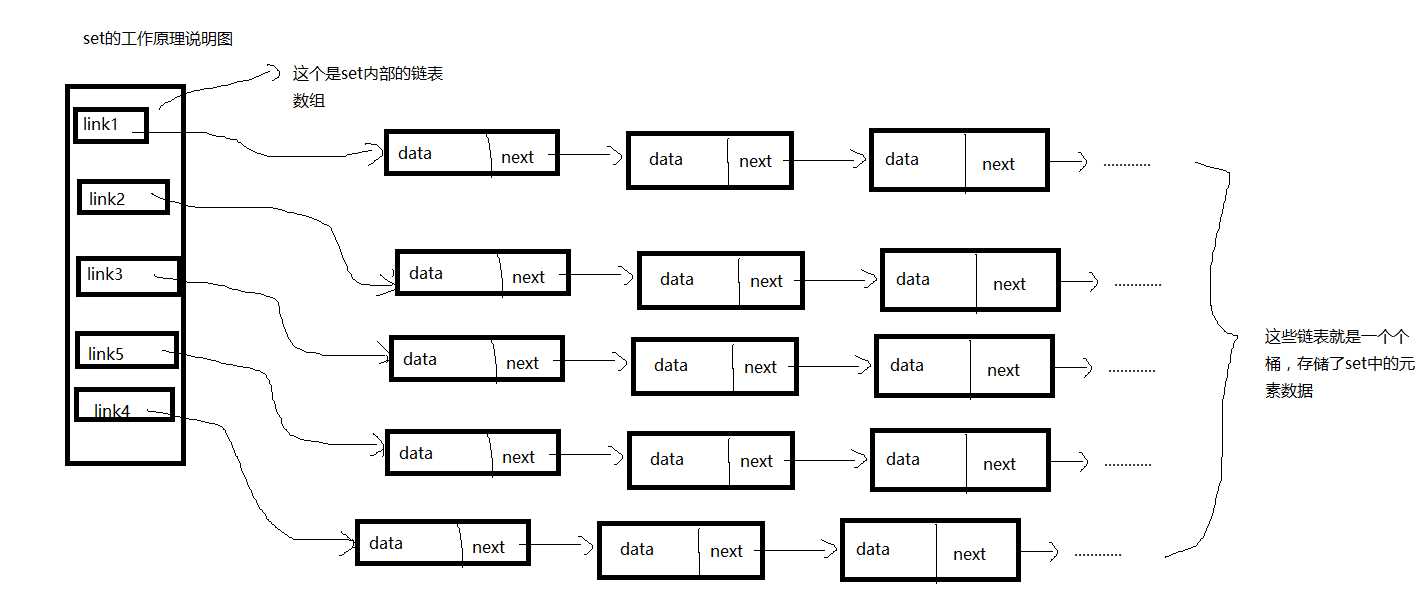
好了,上图大概阐明了set的主要数据结构,归根到底就是一句话:set是利用hashCode进行对象定位,利用链表数组进行存储的数据结构!
2、treeSet:树状的散列表(不知道这个描述是否准确)。treeSet,顾名思义,利用树的结构实现的一种set数据结构。在treeSet中,它不像hashSet中的元素那样元素毫无顺序,treeSet是一种有序的数据结构。具体的数据结构示意图就不画出来了,因为挺好理解的。总的来说,treeSet和hashSet大体上只是数据存储机构的不同,下面会对两者进行对比的。
3、treeSet VS hashTree:
首先,hashTree既然包含数组机构,那肯定在所有桶数到达临界点时,要进行大规模的扩桶操作,这样毫无疑问会大大影响性能。当然,也正因为它的无序性和包含链表的部分特性(数组链表嘛),它的插入元素是非常快的(毕竟插入时不用重新排序嘛),另外,它的查询操作速度上也还可以,毕竟它包含了一种数组的结构在里面(数组性质就是通过游标可以快速定位嘛);
然后呢,再说treeSet吧,作为树状的结构,扩展时时不存在什么问题的,但是在插入元素的时候,显然要重新排列数据,所以插入输入肯定比不上hashSet的。当然,在查询元素中,treeSet的速度可不是盖的,毕竟人家是tree的结构(就算是简单的二叉有序树复杂度也只是logn)。
总的来说:hashSet扩展性不好,但是查和插入(删除也一样)速度都不错;treeSet扩展性不错,查速度也不错,就是插入会速度慢点。
以上是关于java--集合框架总结1--set总结的主要内容,如果未能解决你的问题,请参考以下文章