HDU 1880 魔咒词典
Posted qq136155330
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDU 1880 魔咒词典相关的知识,希望对你有一定的参考价值。
魔咒词典
TimeLimit: 8000/5000 MS (Java/Others) MemoryLimit: 32768/32768 K (Java/Others)
64-bit integer IO format:%I64d
Problem Description
哈利波特在魔法学校的必修课之一就是学习魔咒。据说魔法世界有100000种不同的魔咒,哈利很难全部记住,但是为了对抗强敌,他必须在危急时刻能够调用任何一个需要的魔咒,所以他需要你的帮助。
给你一部魔咒词典。当哈利听到一个魔咒时,你的程序必须告诉他那个魔咒的功能;当哈利需要某个功能但不知道该用什么魔咒时,你的程序要替他找到相应的魔咒。如果他要的魔咒不在词典中,就输出“what?”
给你一部魔咒词典。当哈利听到一个魔咒时,你的程序必须告诉他那个魔咒的功能;当哈利需要某个功能但不知道该用什么魔咒时,你的程序要替他找到相应的魔咒。如果他要的魔咒不在词典中,就输出“what?”
Input
首先列出词典中不超过100000条不同的魔咒词条,每条格式为:
[魔咒] 对应功能
其中“魔咒”和“对应功能”分别为长度不超过20和80的字符串,字符串中保证不包含字符“[”和“]”,且“]”和后面的字符串之间有且仅有一个空格。词典最后一行以“@[email protected]”结束,这一行不属于词典中的词条。
词典之后的一行包含正整数N(<=1000),随后是N个测试用例。每个测试用例占一行,或者给出“[魔咒]”,或者给出“对应功能”。
[魔咒] 对应功能
其中“魔咒”和“对应功能”分别为长度不超过20和80的字符串,字符串中保证不包含字符“[”和“]”,且“]”和后面的字符串之间有且仅有一个空格。词典最后一行以“@[email protected]”结束,这一行不属于词典中的词条。
词典之后的一行包含正整数N(<=1000),随后是N个测试用例。每个测试用例占一行,或者给出“[魔咒]”,或者给出“对应功能”。
Output
每个测试用例的输出占一行,输出魔咒对应的功能,或者功能对应的魔咒。如果魔咒不在词典中,就输出“what?”
SampleInput
SampleOutput
[思路]:一开始我是打算直接两颗字典树瞎几把跑一下,结果直接mle,然后我想把指针版字典树改成数组版,
sandy老哥搞了一下还是mle,那我就莫得了,于是改了hash来写,首先来说一下字符串hash,把字符串当做一个
p进制的数字,p最好为素数,这样的话冲突较少,一般为131,这样的话,就可以把字符串映射到对应位置的数组去,
书上说mod为2的64次方的时候基本是没有冲突,但是对于这题100000的数据范围,还是会存在冲突的。瞎搞的时候
发现后台数据是有冲突数据的,那么我采用的是一直向后查询,查到一个空的位置,把字符串放进去,放上代码,hash的复杂度为O(n)
查询复杂度最优为O(1)
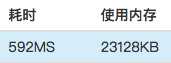
使用时间:
附上代码:
#include <iostream> #include <cstdio> #include <cstring> using namespace std; typedef long long ll; char hash_z_g[100005][85]; char hash_z[100005][25]; bool vids_z_g[100005]; char hash_g_z[100005][25]; char hash_g[100005][85]; bool vids_g_z[100005]; int ct = 0; int judge(char ans) { if(ans == ‘‘‘) return 27; if(ans == ‘ ‘) return 28; else return (ans - ‘a‘); } ll myhash(char str[]) { ll sum = 0; int len1 = strlen(str); for(int i = 0; i < len1; i ++) { sum = sum * 131 % 100003 + judge(str[i]); sum %= 100003; } return sum; } void insert_z_g(char str[], char strs[]) { ll num = myhash(str); if(!vids_z_g[num]) { vids_z_g[num] = true; strcpy(hash_z_g[num], strs); } else { while(vids_z_g[num]) {ct ++; num ++; num = num % 100003; } vids_z_g[num] = true; strcpy(hash_z_g[num], strs); } strcpy(hash_z[num], str); } void insert_g_z(char str[], char strs[]) { ll num = myhash(str); if(!vids_g_z[num]) { vids_g_z[num] = true; strcpy(hash_g_z[num], strs); } else { while(vids_g_z[num]) {ct ++; num ++; num = num % 100003; } vids_g_z[num] = true; strcpy(hash_g_z[num], strs); } strcpy(hash_g[num], str); } bool acfinds_z_g(char str[]) { ll num = myhash(str); if(vids_z_g[num]) { if(strcmp(str, hash_z[num]) == 0) { printf("%s ", hash_z_g[num]); return true; } else { if(ct == 0) return false; int bj = 0; while(vids_z_g[num]) { num ++; bj ++; if(bj >= 100003) return false; num = num % 100003; if(strcmp(str, hash_z[num]) == 0) { printf("%s ", hash_z_g[num]); return true; } } return false; } } else { return false; } } bool acfinds_g_z(char str[]) { ll num = myhash(str); if(vids_g_z[num]) { if(strcmp(str, hash_g[num]) == 0) { printf("%s ", hash_g_z[num]); return true; } else { if(ct == 0) return false; int bj = 0; while(vids_g_z[num]) { num ++; bj ++; if(bj >= 100003) return false; num = num % 100003; if(strcmp(str, hash_g[num]) == 0) { printf("%s ", hash_g_z[num]); return true; } } return false; } } else { return false; } } char str[205]; char sss[] = "@[email protected]"; int main() { while(gets(str) != NULL) { if(strcmp(sss, str) == 0) { break; } else { char fl1[105], fl2[105]; int len = strlen(str); int f_1, f_2; f_1 = f_2 = 0; memset(fl1, 0, sizeof(fl1)); memset(fl2, 0, sizeof(fl2)); int flag = 1; for(int i = 0; i < len; i ++) { if(flag == 1) { if(str[i] == ‘[‘) { continue; } else if(str[i] == ‘]‘) { fl1[f_1] = ‘�‘; flag ++; i ++; } else { fl1[f_1] = str[i]; f_1 ++; } } else if(flag == 2) { fl2[f_2] = str[i]; f_2 ++; } } fl2[f_2] = ‘�‘; insert_z_g(fl1, fl2); insert_g_z(fl2, fl1); }} char temp[105]; int n; scanf("%d", &n); getchar(); for(int i = 0; i < n; i ++) { int flag = 0; cin.getline(temp, 105); int lens = strlen(temp); char re[105]; memset(re, 0, sizeof(re)); int f_re = 0; for(int i = 0; i < lens; i ++) { if(temp[i] == ‘[‘) { flag = 1; continue; } else if(temp[i] == ‘]‘) { continue; } else { re[f_re] = temp[i]; f_re ++; } } bool re_s; if(flag) re_s = acfinds_z_g(re); else re_s = acfinds_g_z(re); if(re_s == false) { printf("what? "); } } return 0; }
以上是关于HDU 1880 魔咒词典的主要内容,如果未能解决你的问题,请参考以下文章