Scrapy 框架入门
Posted yunche
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy 框架入门相关的知识,希望对你有一定的参考价值。
一、介绍
? Scrapy 是一个基于Twisted 的异步处理框架,是纯 Python 实现的爬虫框架,其架构清晰,模块之间耦合较低,扩展性和灵活强,是目前 Python 中使用最广泛的爬虫框架。
架构示意图;
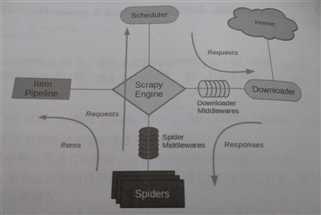
它分为以下几个部分:
- Engine:引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
- Item:项目,它定义了爬取数据结果的数据结构,爬取的数据会被赋值成该 Item 对象。
- Scheduler:调度器,接受引擎发送过来的请求并将其加入到队列中,在引擎再次请求的时候提供给引擎。
Downloader:下载器,下载网页内容并将其返回给Spiders。
- Spiders:蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要任务是负责解析响应并生成提取结果和新的请求。
- Item Pipeline:项目管道,负责处理由 Spiders 从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
- Downloader Middlewares:下载中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
Spider Middlewares:蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
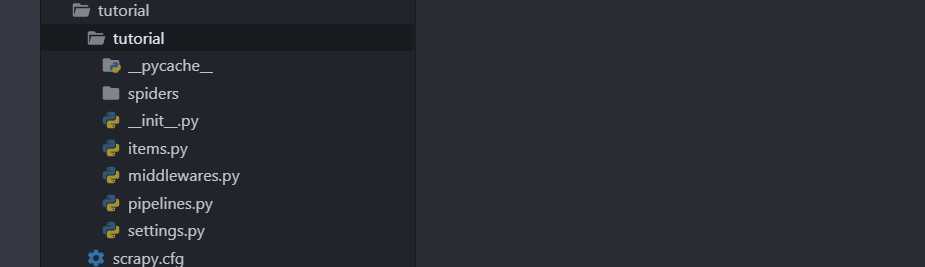
项目结构
Scrapy 框架通过命令行来创建项目,IDE 编写代码,项目文件结构如下所示:
scrapy.cfg # Scrapy 项目配置文件 project/ __init__.py items.py # 它定义了 Item 数据结构 pipelines.py # 它定义了 Item Pipeline 的实像 settings.py # 它定义了项目的全局配置 middlewares.py # 它定义了 Spider、Downloader 的中间件的实现 spiders/ # 其内包含了一个个 spider 的实现 __init__.py spider1.py spider2.py ...
二、Scrapy 入门 Demo
目标:
- 创建一个 Scrapy 项目。
- 创建一个 Spider 来抓取站点和处理数据。
- 通过命令行将抓取的内容导出。
- 将抓取的内容保存到 MongoDB 数据库。
创建一个 Scrapy 项目:
scrapy startproject tutorial文件夹结构如下:
创建 Spider
自定义的 Spider 类必须继承
scrapy.Spider类。使用命令行自定义一个 Quotes Spider。cd tutorial # 进入刚才创建的 tutorial,即进入项目的根路径 scrapy genspider quotes quotes.toscrape.com # 执行 genspider 命令,第一个参数是 Spider 的名称,第二个参数是网站域名。然后 spiders 下就多了个 quotes.py 文件:
# -*- coding: utf-8 -*- import scrapy class QuotesSpider(scrapy.Spider): # 每个 spider 独特的名字以便区分 name = 'quotes' # 要爬取的链接的域名,若链接不在这个域名下,会被过滤 allowed_domains = ['quotes.toscrape.com'] # 它包含了 Spider 在启动时爬取的 url 列表请求 start_urls = ['http://quotes.toscrape.com/'] # 当上述的请求在完成下载后,返回的响应作为参数,该方法负责解析返回的响应、提取数据或进一步生成要处理的请求 def parse(self, response): pass创建 Item
Item 是用来保存爬取数据的容器(数据结构),使用方法类似与字典,不过多了额外的保护机制避免拼写错误。创建自定义的 Item 也需要继承
scrapy.Item类并且定义类型为scrapy.Filed的字段。修改items.py如下:import scrapy class QuoteItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() text = scrapy.Field() author = scrapy.Field() tags = scrapy.Field() pass解析 Response
首先打开自定义的 Spider 中的首个请求:http://quotes.toscrape.com/,查看网页结构,发现每一页都有多个 class 为 quote 的区块,每个区块内都含有 text、author、tags。
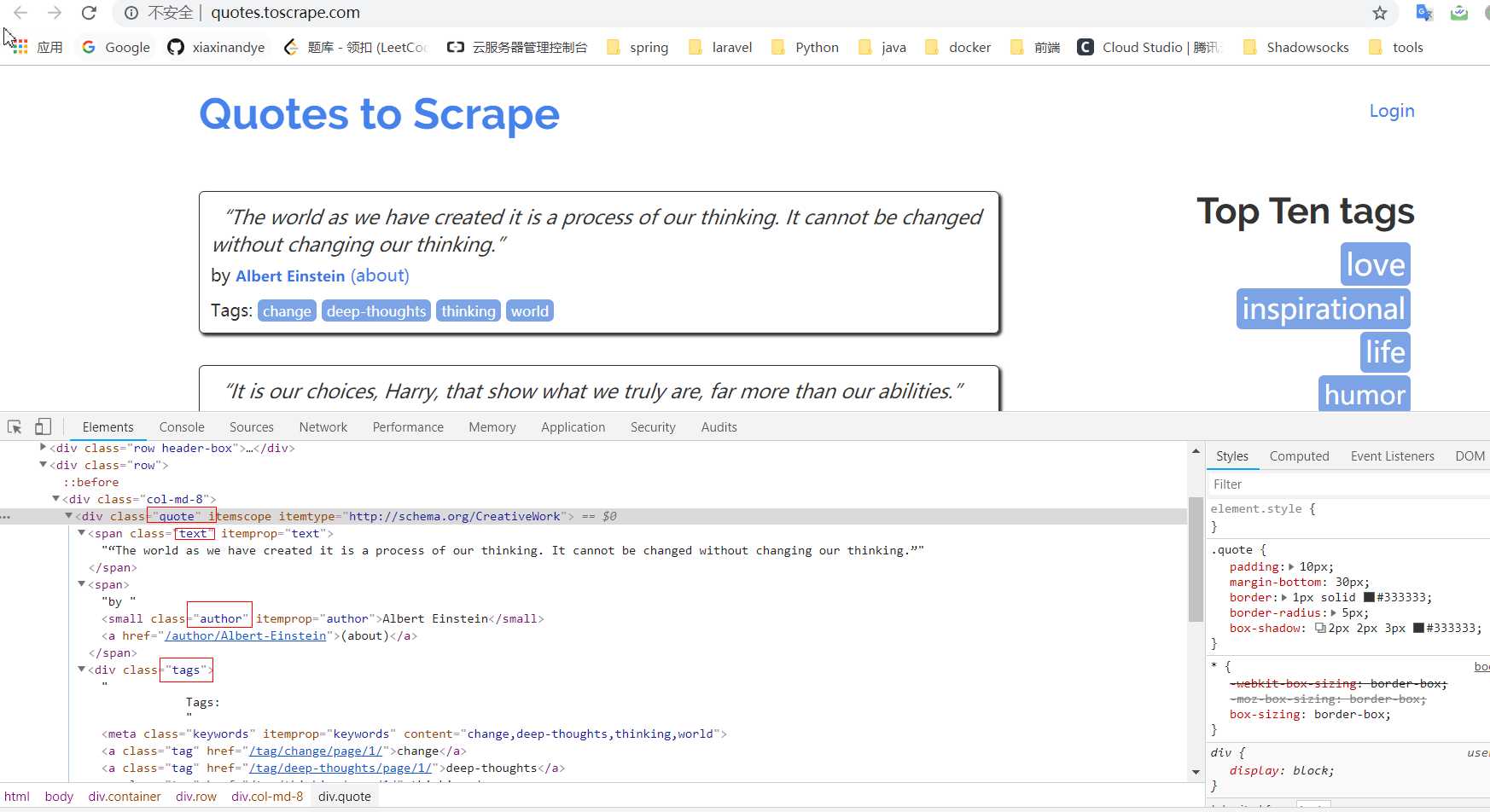
所以,修改自定义 Spider 中的 parse 方法如下:
# -*- coding: utf-8 -*- import scrapy class QuotesSpider(scrapy.Spider): name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): # 使用 css 选择器,选出类为 quote 的元素 quotes = response.css('.quote') for quote in quotes: # 获取 quote 下第一个.text 元素的的 text text = quote.css('.text::text').extract_first() author = quote.css('.author::text').extract_first() # 获取多个标签的文本 tags = quote.css('.tags .tag::text').extract()使用 Item
QuotesSpider 的改写如下:
# -*- coding: utf-8 -*- import scrapy from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider): name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): # 使用 css 选择器,选出类为 quote 的元素 quotes = response.css('.quote') for quote in quotes: # 实例化 QuoteItem item = QuoteItem() # 获取 quote 下第一个.text 元素的的 text item['text'] = quote.css('.text::text').extract_first() item['author'] = quote.css('.author::text').extract_first() # 获取多个标签的文本 item['tags'] = quote.css('.tags .tag::text').extract() yield item后续 Requets
这里后续的请求指的是请求下一页的数据,该怎么请求呢?就要观察网页了:
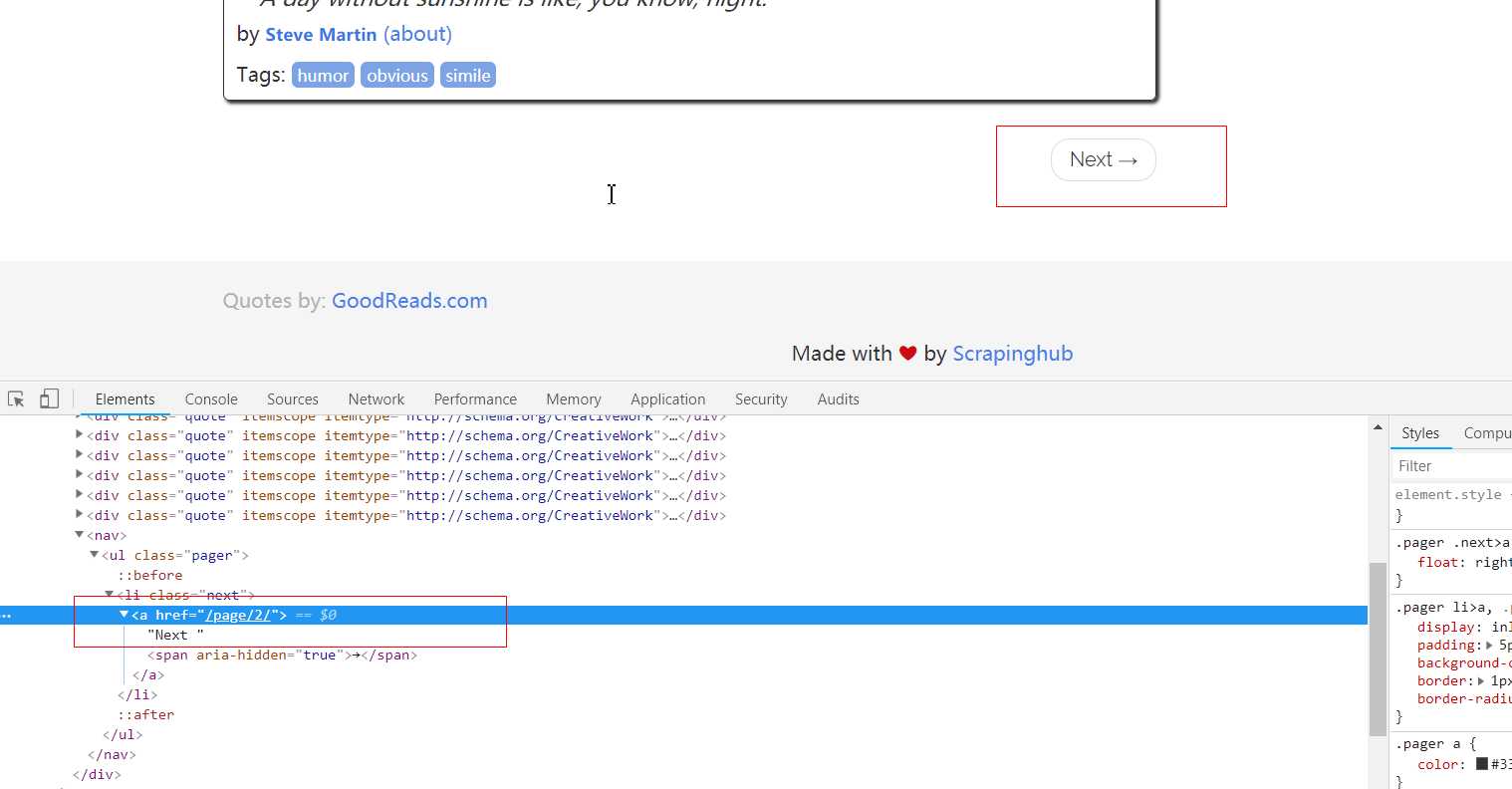
QuotesSpider.py:
# -*- coding: utf-8 -*- import scrapy from tutorial.items import QuoteItem class QuotesSpider(scrapy.Spider): name = 'quotes' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): # 使用 css 选择器,选出类为 quote 的元素 quotes = response.css('.quote') for quote in quotes: # 实例化 QuoteItem item = QuoteItem() # 获取 quote 下第一个.text 元素的的 text item['text'] = quote.css('.text::text').extract_first() item['author'] = quote.css('.author::text').extract_first() # 获取多个标签的文本 item['tags'] = quote.css('.tags .tag::text').extract() yield item # 获取下一页的相对 url next = response.css('.pager .next a::attr("href")').extract_first() # 获取下一页的绝对 url url = response.urljoin(next) # 构造新的请求,这个请求完成后,响应会重新经过 parse 方法处理,如此往复 yield scrapy.Request(url=url, callback=self.parse)运行 Spider
scrapy crawl quotes下面是控制台的输出结果,输出了当前的版本号以及 Middlewares 和 Pipelines,各个页面的抓取结果等。
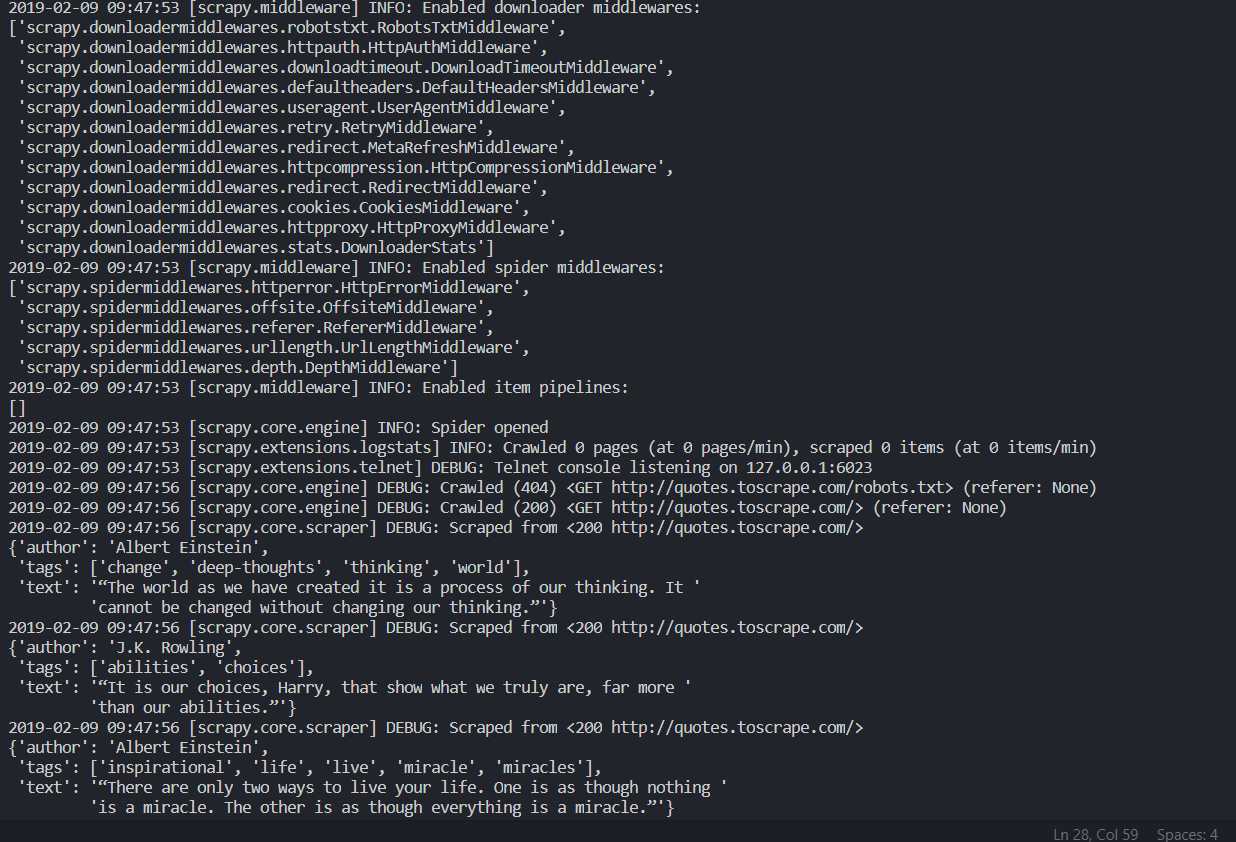
保存到文件中
- scrapy crawl quotes -o quotes.json:将上面抓取数据的结果保存成 json 文件。
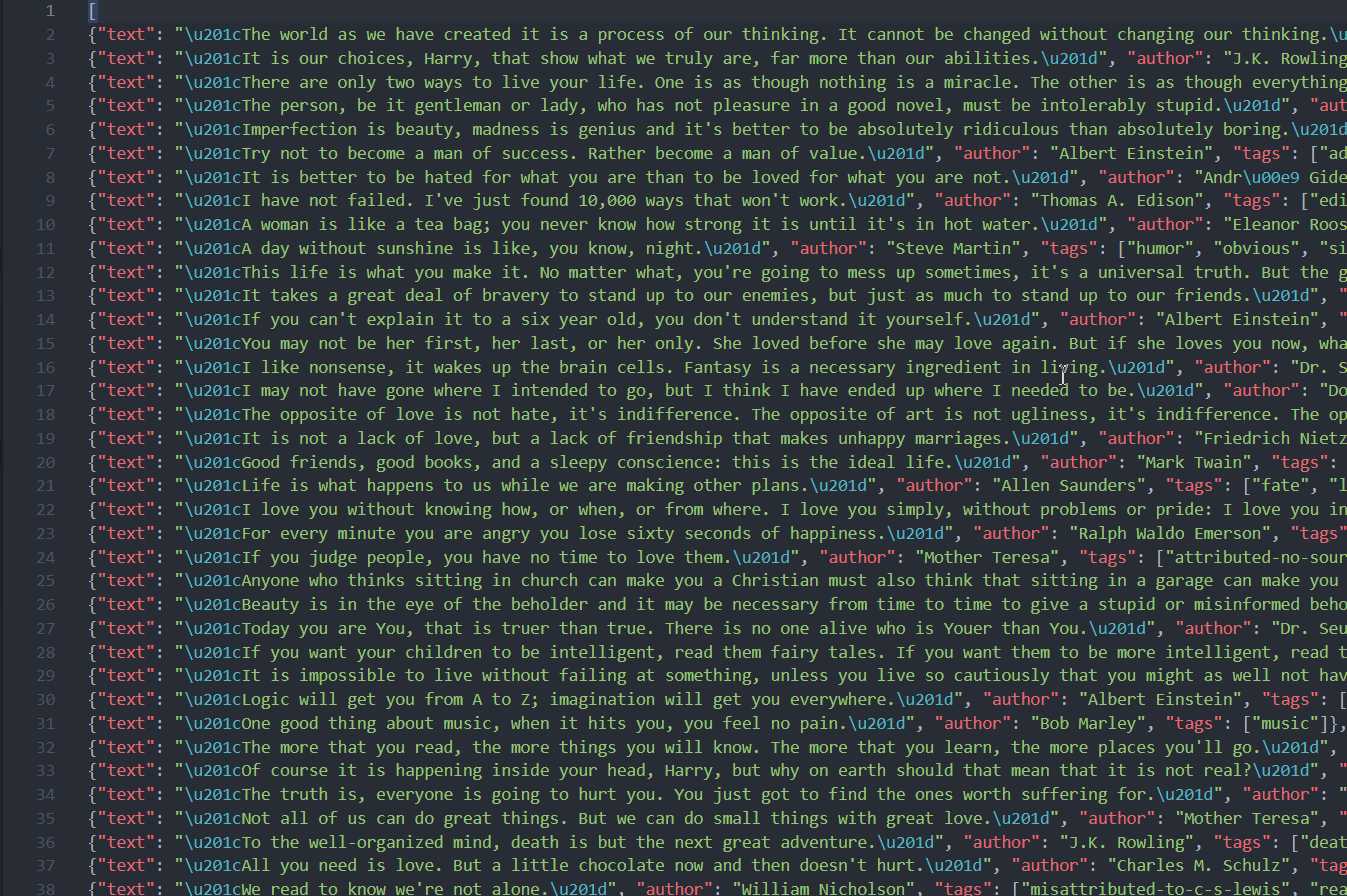
- scrapy crawl quotes -o quotes.jsonlines:每一个 Item 输出一行 JSON。
- scrapy crawl quotes -o quotes.cs:输出为 CSV 格式。
- scrapy crawl quotes -o quotes.xml:输出为 XML 格式。
- scrapy crawl quotes -o quotes.pickle:输出为 pickle 格式。
- scrapy crawl quotes -o quotes.marshal:输出为 marshal 格式。
- scrapy crawl quotes -o ftg://user:[email protected]/path/to/quotes.csv:ftp 远程输出。
使用 Item Pineline 保存到数据库中
如果想进行更复杂的操作,如将结果保存到 MongoDB 数据中或筛选出某些有用的 Item,则我们可以自定义 ItemPineline 来实现。修改 pinelines.py 文件:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.exceptions import DropItem import pymongo class TextPipeline(object): def __init__(self): self.limit = 50 # 需要实现 process_item 方法,启用 Item Pineline 会自动调用这个方法 def process_item(self, item, spider): ''' 如果字段无值,抛出 DropItem 异常,否则判断字段的长度是否大于规定的长度, 若大于则截取到规定的长度并拼接上省略号,否则直接返回 item ''' if item['text']: if len(item['text']) > self.limit: item['text'] = item['text'][0:self.limit].rstrip() + '...' return item else: return DropItem('Missing Text') class MongoPipeline(object): def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db= mongo_db ''' 此方法用@classmethod 修饰表示时一个类方法,是一种依赖注入的方式,通过 crawler 我们可以获取到全局配置(settings.py)的每个信息 ''' @classmethod def from_crawler(cls, crawler): return cls( mongo_uri = crawler.settings.get('MONGO_URI'), mongo_db = crawler.settings.get('MONGO_DB') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] # 执行了数据库的插入操作 def process_item(self, item, spider): name = item.__class__.__name__ self.db[name].insert(dict(item)) return item def close_spider(self, spider): self.client.close()settings.py 添加如下内容:
# 赋值 ITEM_PIPELINES 字典,键名是 pipeline 类的名称,键值是优先级, #是一个数字,越小,越先被调用 ITEM_PIPELINES = { 'tutorial.pipelines.TextPipeline': 300, 'tutorial.pipelines.MongoPipeline': 400 } MONGO_URI = 'localhost' MONGO_DB = 'tutorial'重新执行爬取
scrapy crawl quotes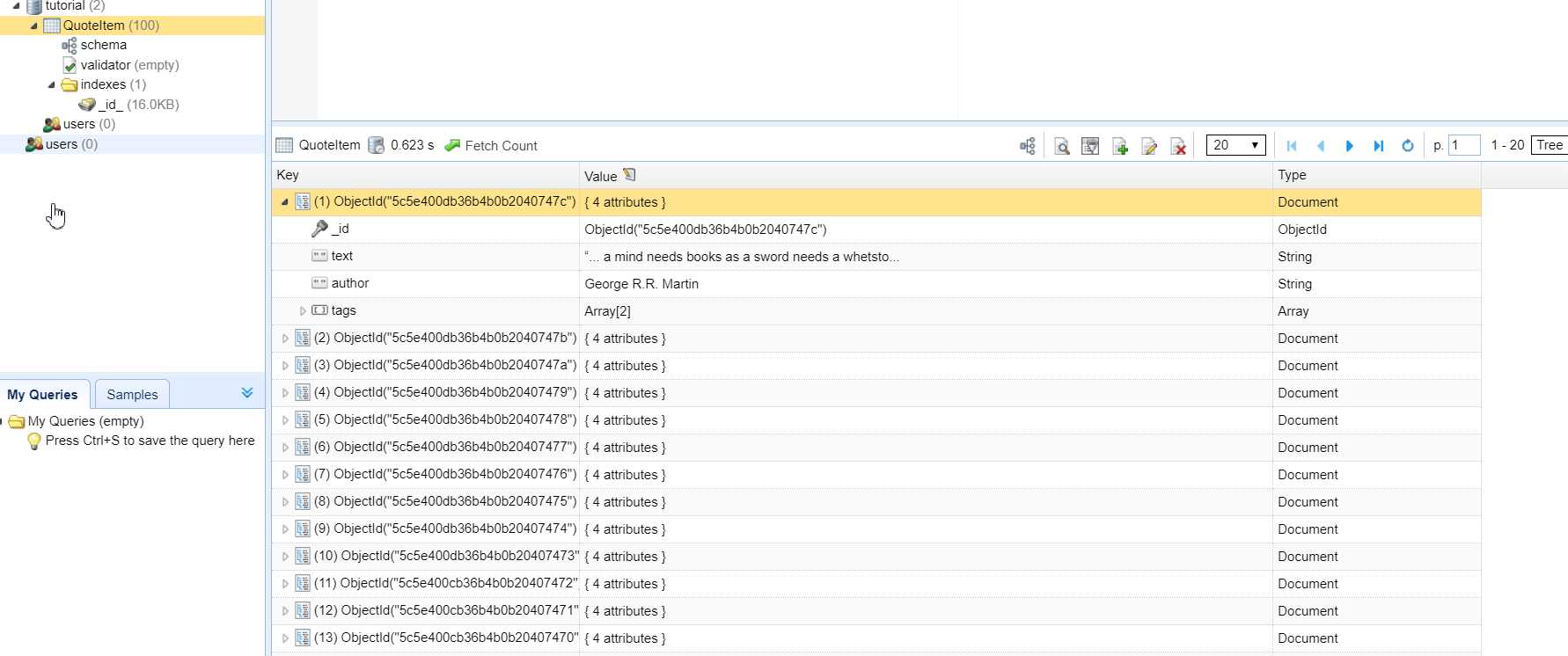
三、参考书籍
崔庆才.《Python3 网络爬虫开发实战》
以上是关于Scrapy 框架入门的主要内容,如果未能解决你的问题,请参考以下文章