(三十三)
Posted asia-yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(三十三)相关的知识,希望对你有一定的参考价值。
一、线程
是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。线程有就绪、阻塞和运行三种基本状态。
二、线程的两种创建方式
1.第一种方式
from threading import Thread T = Thread(function,args=(arg1,arg2,...)) T.start()
2.第二种方式
from threading import Thread
Class MThread(Thread):
Def run(self):
Pass
mt = MThread()
mt.start()
三、线程的空间
- 查看pid
import os
def f():
print(os.getpid())
t = Thread(target=f,)
t.start()
2.线程空间不是隔离的
import os
def f():
print(‘子线程pid:‘, os.getpid())#(1)
t = Thread(target=f,)
t.start()
print(‘主线程pid:‘, os.getpid())#(2)
说明:(1)、(2)两处的值是一样的。可见,线程都是在一个进程内,而一个进程都有自己独立的空间。
3.线程与进程的效率对比
(1)只是创建线程和进程
def f1():
pass
def f2():
pass
if __name__ == ‘__main__‘:
t_s = time.time()
t_lst = []
for i in range(20):
t = Thread(target=f1,)
t.start()
t_lst.append(t)
for tt in t_lst:
tt.join()
t_e = time.time()
p_s = time.time()
p_lst = []
for i in range(20):
p = Process(target=f2,)
p.start()
p_lst.append(p)
for pp in p_lst:
pp.join()
p_e = time.time()
print(‘线程创建时间:‘, t_e - t_s)
print(‘进程创建时间:‘, p_e - p_s)
结果:
线程创建时间: 0.004002809524536133
进程创建时间: 1.838303565979004
通过结果可以看出来,同样创建20个,线程只需要了0.004秒,也就是4毫秒,而创建进程却是1838.3毫秒。得出一个结论:进程创建过程比线程创建过程要麻烦。因为进程创建的过程是,需要在内存里开辟一个空间,把解释器代码加载进来,还需要把自己写的程序也加载进去。而线程是进程里的一个实体,只需要进程中的一点资源。所有线程共享进程中的所有资源。
(2)再来一个线程中有I/O阻塞的比较
(2)def f1():
print(‘f1>>>>>aaaaa‘)
time.sleep(1)
print("f1>>>>>bbbbb")
def f2():
print(‘f2>>>>>aaaaa‘)
time.sleep(1)
print("f2>>>>>bbbbb")
if __name__ == ‘__main__‘:
t_s = time.time()
t_lst = []
for i in range(20):
t = Thread(target=f1,)
t.start()
t_lst.append(t)
for tt in t_lst:
tt.join()
t_e = time.time()
p_s = time.time()
p_lst = []
for i in range(20):
p = Process(target=f2,)
p.start()
p_lst.append(p)
for pp in p_lst:
pp.join()
p_e = time.time()
print(‘线程创建时间:‘, t_e - t_s)
print(‘进程创建时间:‘, p_e - p_s)
结果:
。。。。。
线程创建时间: 1.0074326992034912
进程创建时间: 3.006932497024536
线程只是在一个进程中操作,这样就利用多道技术,实现了并发(Python中的线程不能实现多核方式,后面介绍)。进程却要创建20个,开销,时间都要比线程的多。
(3)这个是计算型的操作
def f1():
# print(‘f1>>>>>aaaaa‘)
# time.sleep(1)
# print("f1>>>>>bbbbb")
n = 10
for i in range(10000000):
n += i
def f2():
# print(‘f2>>>>>aaaaa‘)
# time.sleep(1)
# print("f2>>>>>bbbbb")
n = 10
for i in range(10000000):
n += i
if __name__ == ‘__main__‘:
t_s = time.time()
t_lst = []
for i in range(5):
t = Thread(target=f1,)
t.start()
t_lst.append(t)
for tt in t_lst:
tt.join()
t_e = time.time()
p_s = time.time()
p_lst = []
for i in range(5):
p = Process(target=f2,)
p.start()
p_lst.append(p)
for pp in p_lst:
pp.join()
p_e = time.time()
print(‘线程操作时间:‘, t_e - t_s)
print(‘进程操作时间:‘, p_e - p_s)
结果:
线程操作时间: 3.7418324947357178
进程操作时间: 2.925071954727173
好神奇啊,这次进程使用的时间短了,线程的却多了。这也是因为,线程不能使用多核技术。
四、锁
- Lock
先看第一段代码:
num = 100
def f():
global num
tmp = num
tmp -= 1
time.sleep(0.01)
num = tmp
if __name__ == ‘__main__‘:
t_lst = []
for i in range(10):
t1 = Thread(target=f)
t1.start()
t_lst.append(t1)
[t.join() for t in t_lst]
print(num)
执行结果:
99
上面这段代码的作用是,想循环10次,为num每次减1,但是结果却是99。原因就是,线程执行的太快了,导致10个线程都执行到了time.sleep(0.01)这里,然后都去等着操作系统再次调用。调用到了后,再次执行赋值的操作,这样num就是99了。
为了数据安全,加把锁吧,看代码:
num = 100
def f(loc):
global num
loc.acquire()
tmp = num
tmp -= 1
time.sleep(0.01)
num = tmp
loc.release()
if __name__ == ‘__main__‘:
loc = Lock()
t_lst = []
for i in range(10):
t1 = Thread(target=f,args=(loc,))
t1.start()
t_lst.append(t1)
[t.join() for t in t_lst]
print(num)
结果:
90
这次完成了心愿,结果是90了。当第一个线程拿到锁后,执行所有的操作,即便有sleep需要等待,其他9个线程也得等着,必须等着第一完成了。第一个完成后,接下来就是第二个线程,也跟第一个一样,不管其他的怎么着急,就是慢慢执行自己的。依次类推,最后结果就是90了。
2.死锁
在工作中有可能会有锁的嵌套,稍有不慎,那么就会死锁了。还是看代码:
# def f1(locA, locB): # locA.acquire() # print(‘f1aaaaaaaaaaaa‘) # time.sleep(0.1) # locB.acquire() # print(‘f1bbbbbbbbb‘) # locB.release() # locA.release() # def f2(locA, locB): # locB.acquire() # print(‘f2--aaaaaaaa‘) # time.sleep(0.1) # locA.acquire() # print(‘f2--bbbbbbbb‘) # locA.release() # locB.release() # if __name__ == ‘__main__‘: # locA = Lock() # locB = Lock() # # t1 = Thread(target=f1, args=(locA, locB)) # t2 = Thread(target=f2, args=(locA, locB)) # # t1.start() # t2.start()
运行后,会看到程序一直处于运行中。不会往下走了,因为线程t1等着要locB的锁,而线程t2等着要线程locA的锁,从而导致两边就这样互相等待着,程序一直不运行。
3.递归锁
为了解决死锁,Python出现了递归锁。看代码:
# def f1(locA, locB): # locA.acquire() # print(‘f1aaaaaaaaaaaa‘) # time.sleep(0.1) # locB.acquire() # print(‘f1bbbbbbbbb‘) # locB.release() # locA.release() # def f2(locA, locB): # # locB.acquire() # with locB: # print(‘f2--aaaaaaaa‘) # time.sleep(0.1) # # locA.acquire() # with locA: # print(‘f2--bbbbbbbb‘) # # locA.release() # # locB.release() # if __name__ == ‘__main__‘: # locA = locB = RLock() # t1 = Thread(target=f1, args=(locA, locB)) # t2 = Thread(target=f2, args=(locA, locB)) # # t1.start() # t2.start()
递归锁,当acquire时,内部会有计数器,加1;前面acquire几次,就会记为几,当释放时,会依次再把锁释放掉。
4.GIL
这个是加载cpython解释器上的一把锁,因为它而导致Python的线程不能使用多核技术,只能串行。看图:
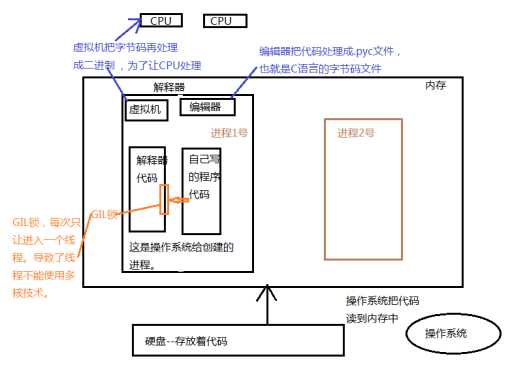
接下来看图说话:当我们运行了一个py文件后,其实就是启动了一个进程,操作系统就会把代码读取到内容中,并为这个进程分配相应的内存空间。在这个进程中,还会读入解释器的代码。编辑器会把这些代码处理成C语言的字节码,然后虚拟机把这些字节码再处理成二进制,这样CPU就可以处理了。
GIL锁就是加在解释器上的,每次只能有一个线程拿到这个GIL锁,其他的线程只能等待前面的把锁释放了再拿。遇到I/O阻塞的,操作系统,会把GIL锁拿回来,交给下一个线程。如果再遇到I/O阻塞还会继续拿过来交给下一个线程。这样就实现了类似单核的并发。
还有一些计算型的程序,使用线程时,第一个线程拿到了GIL锁后,会一直执行完毕。然后,操作系统把锁再交给下一个线程,这个线程还是从头执行到尾。也就是遇到计算型,中间没有I/O阻塞的程序,就是串行,一个一个线程去执行。
这里,就可以看出前面进程和线程比较时,关于时间多少的问题了。
以上是关于(三十三)的主要内容,如果未能解决你的问题,请参考以下文章