Manacher 马拉车算法
Posted xiaoguapi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Manacher 马拉车算法相关的知识,希望对你有一定的参考价值。
首先感谢 https://www.cnblogs.com/grandyang/p/4475985.html 这篇文章,给了我很大帮助,解释的很详细。
最近在学习lyd的算法竞赛书,学到求最长回文串的时候就看到了O(n)复杂度的Manacher算法,书上给的是hash+二分做法,复杂度为O(nlgn),所以我就去学习了一下Manacher算法.
上面大佬的文章比较详细了,我在这里再说一下我当时比较迷惑地方,以及我注意的一些细节 我这个人就是和细节过不去,一点细节上解释不明白我就感觉自己还是不会
如何计算数组 p
一般的方法,是以中心点为中心,挨个将半径逐步扩张,直至字符串不再是回文字符串。但是这样做,整体的算法复杂度为 O(n^2)。马拉车算法的关键之处,就在于巧妙的应用了回文字符串的性质,来计算数组 p。
马拉车算法在计算数组 p 的整个流程中,一直在更新两个变量:
(1)id:回文子串的中心位置
(2)mx:回文子串的最后位置
使用这两个变量,便可以用一次扫描来计算出整个数组 p,关键公式为:
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
我们用图示来理解这个公式,如下图:
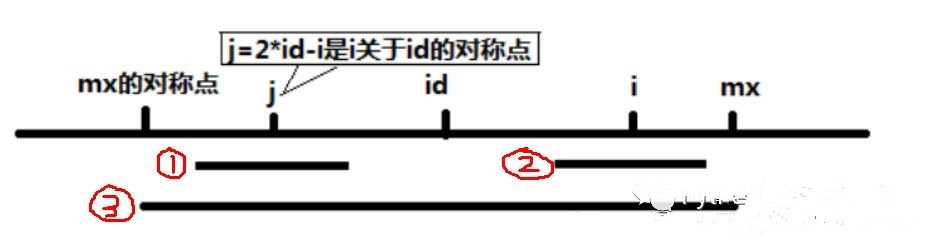
当前,我们已经得到了 p[0...i-1],想要计算出 p[i] 来。红1为以 j 为中心的回文子串,红2为以 i 为中心的回文子串,红3为以 id 为中心的回文子串(首尾两端分别为mx的对称点和mx)。
那么,如果 mx 在 i 的右边,则我们可以通过已经计算出的 p[j] 来计算 p[i],其中 j 与 i 的中心点为 id。这里分两种情况:
(1) 先直接令 p[i] 的回文子串就等于 p[j] 的回文子串,即红2长度等于红1,然后判断红2的末尾是否超过了 mx,如果没有超过,则说明 p[i] 就等于 p[j]。
为什么呢?
因为以 id 为中心的回文子串为红3,包含了红1和红2,而且红1和红2以 id 为中心,那么一定有红2=红1。并且已经知道,红1是以 j 为中心的最长子串,那么红2也肯定是以 i 为中心的最长子串。
(2)如果红2的末尾超过了 mx,那么就只能让 p[i] = mx - i了,即我可以保证至少半径到 mx 这个位置,是可以回文的,但是一旦往右超出了 mx,就不能保证了,剩下的只能用笨方法慢慢扩张来得到最长回文子串。
那如果红2的左边超出了mx的对称点,怎么办?不会出现这种情况的,因为红1的右边不会超过mx。如果超过了mx,那么在上一次迭代中,id应该更新为j,mx应该更新为 j+p[j]。在迭代中,会始终保证 mx 是所有已经得到的回文子串末端最靠右的位置。
另外,如果 mx 不在 i 的右边呢?那就利用不了红3的对称性了,只能使用笨方法慢慢扩张了。
mx更新为i+p[i] 所以此时mx指的是目前最长回文串的下一个字符,因此 p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1 中不用把mx-i改为mx-i+1 ,当时这个地方还有点不解呢
string manacher(string s)
{
string tmp = "$#";
for (int i = 0; i < s.size(); i++)
{
tmp += s[i]; //插入
tmp += "#";
}
int len = tmp.size();
vector<int> p(len, 0);
int mx = 0, id = 0, resLen = 0, resCenter = 0;
for (int i = 1; i < len; i++) // <len就是当 i=len-1 时 p[i]+i 就是字符串最后一个字符‘�‘
{
p[i] = mx > i ? min(mx - i, p[2 * id - i]) : 1;
while (tmp[i + p[i]] == tmp[i - p[i]]) p[i]++;
if (i+p[i] > mx)
{
mx = p[i]; //更新回文串最右端 也就是目前最长回文串
id = i;
}
if (p[i] > resLen)
{
resLen = p[i];
resCenter = i;
}
}
return s.substr((resCenter-resLen)/2,resLen-1);
}
以上是关于Manacher 马拉车算法的主要内容,如果未能解决你的问题,请参考以下文章