XML学习总结
Posted feixian-blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XML学习总结相关的知识,希望对你有一定的参考价值。
什么是XML:
- XML 指可扩展标记语言(EXtensible Markup Language)。
- XML 是一种很像html的标记语言。
- XML 的设计宗旨是传输数据,而不是显示数据。(XML 被设计用来结构化、存储以及传输信息)
- XML 标签没有被预定义。您需要自行定义标签。
HTML 中使用的标签都是预定义的。HTML 文档只能使用在 HTML 标准中定义过的标签(如 <p>、<h1> 等等)。
XML 允许创作者定义自己的标签和自己的文档结构。
通过使用几行 javascript 代码,您就可以读取一个外部 XML 文件,并更新您的网页的数据内容。
XML 数据以纯文本格式进行存储,因此提供了一种独立于软件和硬件的数据存储方法;这让创建不同应用程序可以共享的数据变得更加容易。
XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don‘t forget me this weekend!</body> </note>
第一行是 XML 声明。它定义 XML 的版本(1.0)和所使用的编码(UTF-8 : 万国码, 可显示各种语言)。
下一行描述文档的根元素(像在说:"本文档是一个便签");接下来 4 行描述根的 4 个子元素(to, from, heading 以及 body);最后一行定义根元素的结尾。
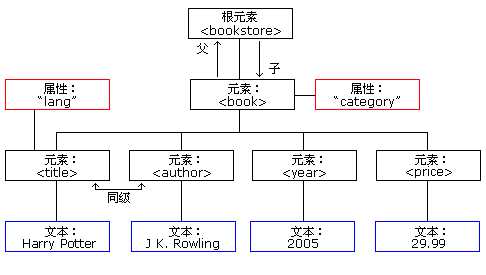
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> </bookstore> //标签中的属性:category指种类,lang指语言
XML将数据组织成为一棵树,DOM 通过解析 XML 文档,为 XML 文档在逻辑上建立一个树模型,树的节点是一个个的对象。这样通过操作这棵树和这些对象就可以完成对 XML 文档的操作,为处理文档的所有方面提供了一个完美的概念性框架。
如下XML文档:
<line id="1"> the <bold>First</bold>line</line>
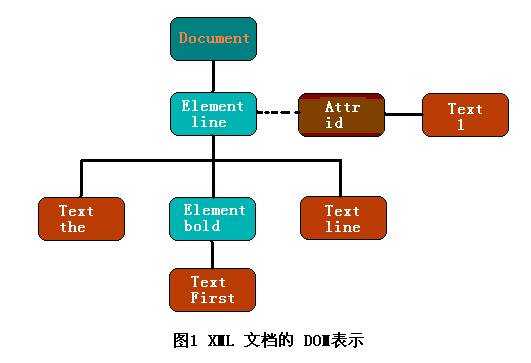
由于DOM“一切都是节点(everything-is-a-node)”,XML树的每个 Document、Element、Text 、Attr和Comment都是 DOM Node。
由上面例子可知, DOM 实质上是一些节点的集合。由于文档中可能包含有不同类型的信息,所以定义了几种不同类型的节点,如:Document、Element、Text、Attr 、CDATASection、ProcessingInstruction、Notation 、EntityReference、Entity、DocumentType、DocumentFragment等。
语法规则:
1、XML 必须包含根元素,它是所有其他元素的父元素。
2、XML 声明文件的可选部分,如果存在需要放在文档的第一行(声明放第一行)。
3、在 XML 中,省略关闭标签是非法的,所有元素都必须有关闭标签。
4、XML 标签对大小写敏感,标签 <Letter> 与标签 <letter> 是不同的。
5、XML 属性值必须加引号。在 XML 中,您应该尽量避免使用属性。如果信息感觉起来很像数据,那么请使用元素吧。
理念:元数据(有关数据的数据)应当存储为属性,而数据本身应当存储为元素。
6、在 XML 中,一些字符拥有特殊的意义。
如果您把字符 "<" 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。
这样会产生 XML 错误:<message>if salary < 1000 then</message>
为了避免这个错误,请用实体引用来代替 "<" 字符:<message>if salary < 1000 then</message>
在 XML 中,有 5 个预定义的实体引用:
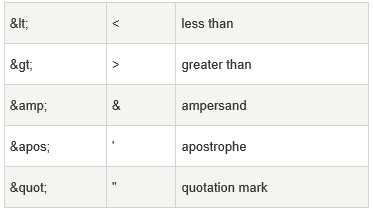
注释:在 XML 中,只有字符 "<" 和 "&" 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。
7、在 XML 中编写注释的语法与 HTML 的语法很相似:<!-- This is a comment -->
8、HTML 会把多个连续的空格字符裁减(合并)为一个,在 XML 中,文档中的空格不会被删减。
9、XML 以 LF 存储换行,Windows 中是回车符(CR)和换行符(LF),在 Unix 和 Mac OSX 中使用 LF,在旧的 Mac 系统中使用 CR 来存储。
10、XML 元素必须遵循以下命名规则:
- 名称可以包含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml(或者 XML、Xml 等等)开始
- 名称不能包含空格
可使用任何名称,没有保留的字词。
11、最佳命名习惯:
使名称具有描述性。使用下划线的名称也很不错:<first_name>、<last_name>。
名称应简短和简单,比如:<book_title>,而不是:<the_title_of_the_book>。
避免 "-" 字符。如果您按照这样的方式进行命名:"first-name",一些软件会认为您想要从 first 里边减去 name。
避免 "." 字符。如果您按照这样的方式进行命名:"first.name",一些软件会认为 "name" 是对象 "first" 的属性。
避免 ":" 字符。冒号会被转换为命名空间来使用(稍后介绍)。
XML 文档经常有一个对应的数据库,其中的字段会对应 XML 文档中的元素。有一个实用的经验,即使用数据库的命名规则来命名 XML 文档中的元素。
在 XML 中,éòá 等非英语字母是完全合法的,不过需要留意,您的软件供应商不支持这些字符时可能出现的问题。
12、XML 元素是可扩展的:
XML 元素是可扩展,以携带更多的信息;请看下面的 XML 实例:
让我们设想一下,我们创建了一个应用程序,可将 <to>、<from> 以及 <body> 元素从 XML 文档中提取出来,并产生以下的输出:
| MESSAGE
To: Tove Don‘t forget me this weekend! |
想象一下,XML 文档的作者添加的一些额外信息:
那么这个应用程序会中断或崩溃吗?
不会。这个应用程序仍然可以找到 XML 文档中的 <to>、<from> 以及 <body> 元素,并产生同样的输出。
XML 的优势之一,就是可以在不中断应用程序的情况下进行扩展。
13、XML DTD
DTD 的目的是定义 XML 文档的结构。它使用一系列合法的元素来定义文档结构:
[
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
14、XML Schema
W3C 支持一种基于 XML 的 DTD 代替者,它名为 XML Schema:
< xs:complexType>
<xs:sequence>
<xs:element name="to" type="xs:string"/>
<xs:element name="from" type="xs:string"/>
<xs:element name="heading" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
< /xs:complexType>
< /xs:element>
15、在 XML 中的命名冲突可以通过使用名称前缀从而容易地避免:<h:table>
当在 XML 中使用前缀时,一个所谓的用于前缀的命名空间必须被定义。
命名空间是在元素的开始标签的 xmlns 属性中定义的。
命名空间声明的语法如下。xmlns:前缀="URI"。
<h:table xmlns:h="http://www.w3.org/TR/html4/">
命名空间被定义在元素的开始标签中时,所有带有相同前缀的子元素都会与同一个命名空间相关联。
命名空间,可以在他们被使用的元素中或者在 XML 根元素中声明:
<root xmlns:h="http://www.w3.org/TR/html4/"
xmlns:f="http://www.w3cschool.cc/furniture">
命名空间 URI 不会被解析器用于查找信息。
其目的是赋予命名空间一个惟一的名称。不过,很多公司常常会作为指针来使用命名空间指向实际存在的网页,这个网页包含关于命名空间的信息。
统一资源标识符(URI),统一资源定位器(URL)。
为元素定义默认的命名空间可以让我们省去在所有的子元素中使用前缀的工作。它的语法如下:xmlns="namespaceURI"
16、XML 文档中的所有文本均会被解析器解析,只有 CDATA 区段中的文本会被解析器忽略。
XML 解析器通常会解析 XML 文档中所有的文本。
当某个 XML 元素被解析时,其标签之间的文本也会被解析:<message>This text is also parsed</message>
解析器之所以这么做是因为 XML 元素可包含其他元素,就像这个实例中,其中的 <name> 元素包含着另外的两个元素(first 和 last):
而解析器会把它分解为像这样的子元素:
<first>Bill</first>
<last>Gates</last>
< /name>
解析字符数据(PCDATA)是 XML 解析器解析的文本数据使用的一个术语。
某些文本,比如 JavaScript 代码,包含大量 "<" 或 "&" 字符。为了避免错误,可以将脚本代码定义为 CDATA。
CDATA 部分中的所有内容都会被解析器忽略,CDATA 部分由 "<![CDATA[" 开始,由 "]]>" 结束:
<script>
< ![CDATA[
function matchwo(a,b)
{
if (a < b && a < 0) then
{
return 1;
}
else
{
return 0;
}
}
]]>
< /script>
不允许嵌套的 CDATA 部分
以上是关于XML学习总结的主要内容,如果未能解决你的问题,请参考以下文章