游戏AI之模糊逻辑
Posted killeraery
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了游戏AI之模糊逻辑相关的知识,希望对你有一定的参考价值。
if(condition)
then dosomething...这次主要围绕的是游戏AI该如何模仿人类地判断条件(condition)。
人类的逻辑
人类的逻辑思考是复杂的,模糊的。
一些人类逻辑思考的例子:“把面包切成中等厚度”,“这波我很强”,“你好骚啊”,“小A有点高”....
而对于计算机,它只认识离散的数值:
假设在一个问题中,智商划分了3个集合:笨拙 = {70~89},平均 = {90~109},聪明 = {110~129}
如果比较一个智商89的人和智商90的人,则但因为计算机很难识别这些模糊的概念(“中等厚度”,“很强”,“好骚”,“笨拙”..),
所以只能根据普通集合得到结论是:89那人是笨拙的,而90那人不是。
这显然有点不符合人类的逻辑。
为了让计算机也能有类似人类的模糊逻辑,引入了模糊集合这个概念。
模糊变量
在介绍模糊集合之前,先介绍它的基本构成——模糊变量。
隶属函数
模糊变量是由若干个属性代表的隶属函数定义的,y值为隶属度,隶属度范围为[0,1]。
当某个属性的隶属度越高,则说明该变量越接近这个属性。
例如IQ是一种模糊变量:IQ = {笨拙,平均,聪明},由三个隶属函数(分别代表蓝线,橙线,灰线)定义边界。
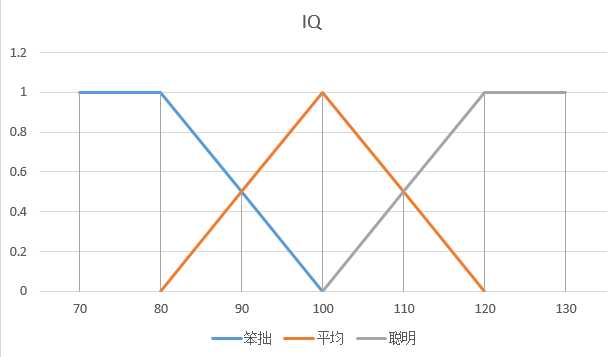
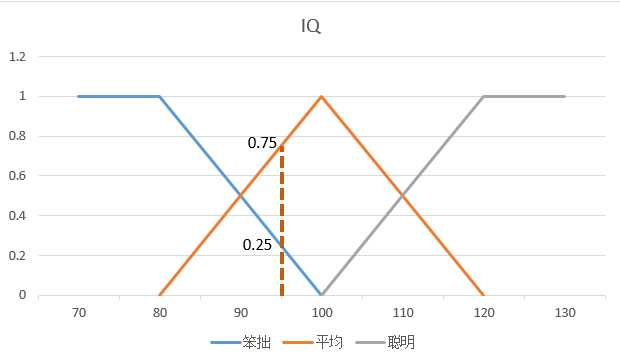
当某个人的IQ为95时,它对"笨拙”的隶属度为0.25,对"平均"的隶属度为0.75,对“聪明”的隶属度为0
隶属函数除了上面这种形状,也可以有其他函数形状:
此外,需要注意的是,模糊逻辑规定,对模糊变量的任意X值,所有隶属函数值之和应等于1。
限制词
使用限制词可以修饰一个隶属函数的形状,变成一个新的隶属函数。
主要有两种修饰:
- “非常”:FVery(x) = F(x)2
- “有点”:FFairly(x) = √F(x);
当我们需要在IQ这个模糊变量需要“非常聪明”的隶属函数时,
可以直接引用“非常”修饰词来修饰“聪明”的隶属函数。
在之前的例子中,
“非常笨拙”的隶属度 = “笨拙”的隶属度的平方 = 0.25^2 = 0.0625。
模糊集合
模糊集合则是1~n个模糊变量构成的集合,而这些集合一般都是用来进行一些运算获得新的集合。
例如:“聪明”取反运算即是“不聪明”的集合;“高”和“聪明”的与运算即是又“高”又“聪明”的集合。
模糊集合运算符
OR或 : F1(x) OR F2(y)= max{F1(x),F2(y)}
AND与 : F1(x) AND F2(y) = min{F1(x),F2(y)}
NOT反 : F(x)‘ = 1-F(x)
在计算集合的具体隶属度的时候,便使用上面运算规则来计算隶属度。
例如:当“高”的隶属度为0.7,“聪明”的隶属度为0.5,则“高”AND“聪明”的隶属度应为min{0.7,0.5} = 0.5
模糊规则
在引入模糊集合后,现在可以根据模糊集合来制定模糊规则。
这里不做定义阐述,就用举例直接理解模糊规则:
举例,有一个模糊集合:
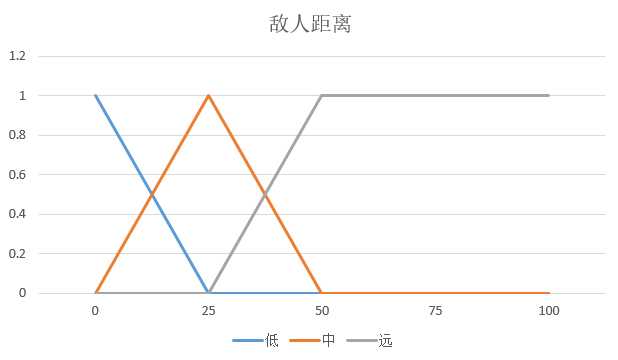
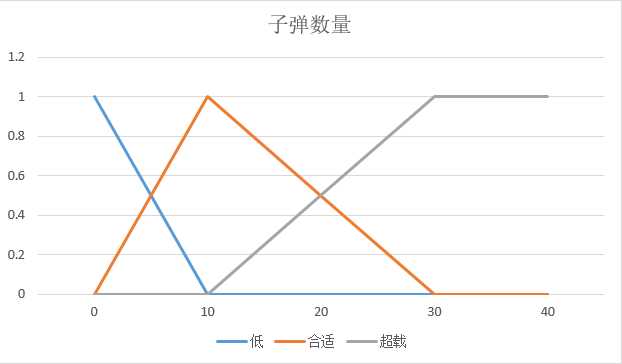
- 模糊变量1:敌人距离 = {近,中,远}
- 模糊变量2:子弹数量 = {低,合适,超载}
其中制定了4条模糊规则:
- 规则1:if(子弹数量低 AND 敌人距离远)then 不期望攻击
- 规则2:if(子弹数量低 AND 敌人距离中)then 不期望攻击
- 规则3:if(子弹数量低 AND 敌人距离近)then 期望攻击
- 规则4:if(子弹数量合适 AND 敌人距离近)then 非常期望攻击
通过规则,我们能够计算出每条规则中条件的隶属度,然后归纳为期望结果的隶属度:
- 规则1中:不期望攻击的隶属度 = “子弹数量低” AND “敌人距离远” 的隶属度
- 规则2中:不期望攻击的隶属度 = “子弹数量低” AND “敌人距离中” 的隶属度
- 规则3中:期望攻击的隶属度 = “子弹数量低” AND “敌人距离近” 的隶属度
- 规则4中:非常期望攻击的隶属度 = “子弹数量合适” AND “敌人距离近” 的隶属度
模糊推理
假设当前敌人距离是12.5,子弹数量是7.5。
- 敌人距离近的隶属度 = 0.5
- 敌人距离中的隶属度 = 0.5
- 敌人距离远的隶属度 = 0
- 子弹数量低的隶属度 = 0.25
- 子弹数量合适的隶属度 = 0.75
- 子弹数量超载的隶属度 = 0
由此计算每条规则的期望结果的隶属度:
- 规则1:不期望攻击的隶属度 = 0
- 规则2:不期望攻击的隶属度 = 0.25
- 规则3:期望攻击的隶属度 = 0.25
- 规则4:非常期望攻击的隶属度 = 0.5
对于同种结果的隶属度,我们一般使用或运算进行合并隶属度。
得到隶属度结果:
不期望的隶属度 = 0.25,期望的隶属度=0.25 ,非常期望的隶属度 = 0.5
然后我们还得另外准备一个模糊变量:期望变量
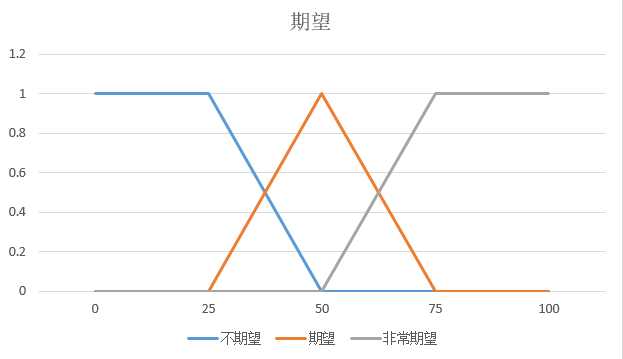
修剪:将形状中限制在隶属度结果的线下
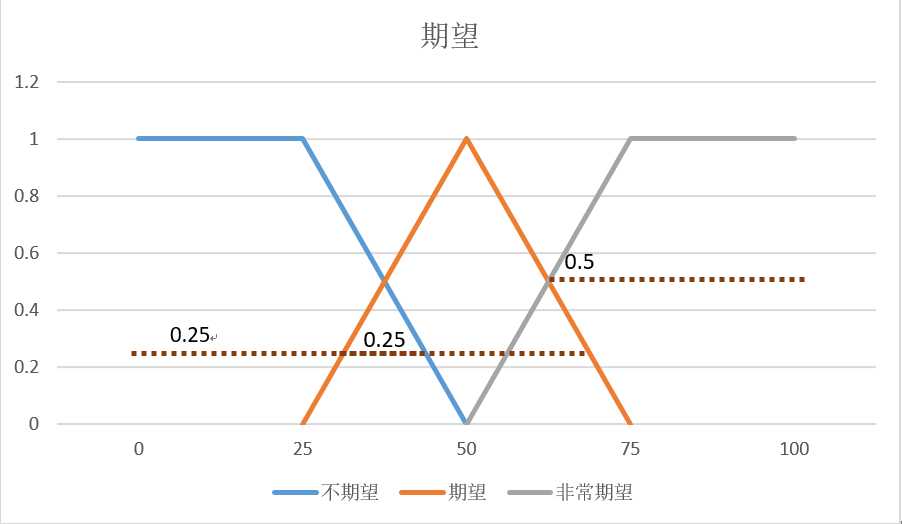
通过修剪的方法将期望集合和这些隶属度结果合成为一个新的模糊形状:
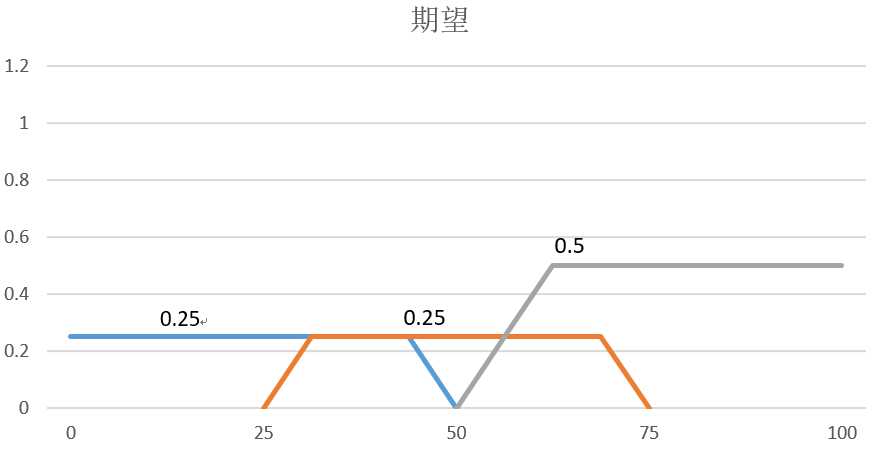
这就是我们的推理结论。
去模糊化
最后一步就是去模糊化,把模糊推理之后得到的形状结果变成一个具体准确的值(到底是做这个动作还是不做)。
最大值平均
最大值平均是一种去模糊化的方法:
输出值 = 每个形状的最大隶属度以及其代表期望值的乘积的的平均值。
三角形形状的代表期望值很容易找,就是它的顶点的x值。
含高台形状的形状(例如梯形,左/右肩形),这个值是在高台开始的x值和高台末尾的x值的平均。
在上面的例子,
不期望形状的最大隶属度0.25对应代表值21.875,
期望形状的最大隶属度为0.25对应代表值为50,
非常期望形状的最大隶属度为0.5对应代表值为81.25.
所以它输出期望值:(0.25*21.875+0.25*50+0.5*81.25)/(0.25+0.25+0.5) = 58.59375
中心法
中心法是一种最准确的去模糊化方法,但也是最复杂的计算方法:输出值 = 形状的中心值,
所谓中心也就是把它放在一把尺子上能保持平衡的位置。
一般的,它使用采样方法来获取近似中心值:
在X轴上平均分布N个点进行采样,计算再每个采样点对总体隶属度的贡献之和,再除以采样的隶属度之和。
N越大,其结果越准确。
如图,对9个点进行采样:
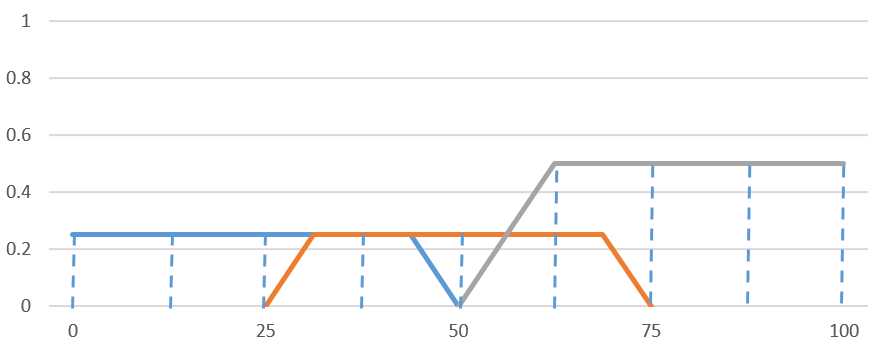
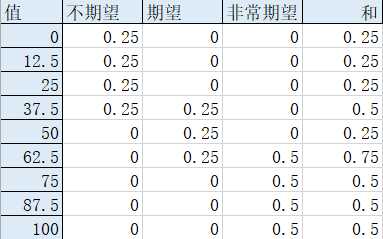
计算出输出期望值:
(0*0.25+12.5*0.25+25*0.25+37.5*0.25+37.5*0.5+50*0.25+62.5* 0.75+75*0.5+87.5*0.5+100*0.5)/(0.25+0.25+0.25+0.5+0.25+0.75+0.75+0.5+0.5)
= 57.03125
库博方法
可以看到,在制定模糊规则的时候一个主要问题是随着模糊变量的增加,其规则数量则以指数级的速度增加。
假设每个模糊变量有3种属性。一个有3个模糊变量的模糊集合,完整的规则应该是有9个规则。而对于5个模糊变量的模糊集合,就已经需要125个规则了。更别说更多模糊变量..
库博方法的工作原理也很简单,只需把变量的复合(一般是指和运算)拆分成单个变量的规则:
- if("聪明"和“长”)then 非常期望
- if("聪明"和“中”)then 非常期望
- if("聪明"和“短”)than 期望
- if("平均"和“长”)than 非常期望
- if("平均"和“中”)than 期望
- if("平均"和“短”)than 期望
- if("笨拙"和“长”)than 期望
- if("笨拙"和“中”)than 期望
- if("笨拙"和“短”)than 不期望
可以拆分为:
- if("聪明")then 非常期望
- if("平均")than 期望
- if("笨拙")than 不期望
- if(“长”)than 非常期望
- if(“中”)than 期望
- if(“短”)than 不期望
对于N个变量,用一般方法需要O(N2)个规则,库伯方法则只需要O(N)个规则。
虽然上这种拆分表面上看对原规则语义几乎是颠覆,
但是实际实验结果,用库博方法计算出来的期望值与一般方法计算出来的期望值相差不多。
当使用大的规则库时,牺牲部分准确性而使用库博方法绝对是值得的。
结语
实际上对AI的行为使用一定范围的随机数而不是模糊逻辑也是可行的,
但是可能会偶尔导致一些愚蠢的行为,除非反复验证并确定好随机数范围从而保证不会出现意外的愚蠢。
意外的愚蠢例如:一个中立的NPC因为随机到了某个仇恨值,有时可能会对主动攻击玩家,有时该攻击时却不主动攻击,这显然是不对的。
但是利用模糊逻辑,它能根据各种潜在因素(玩家的犯罪记录,声誉,距离,衣着魅力等等)而不是随机因素来确定仇恨值,从而达到更加逼真的攻击行为。
以上是关于游戏AI之模糊逻辑的主要内容,如果未能解决你的问题,请参考以下文章