VDCN
Posted echoboy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VDCN相关的知识,希望对你有一定的参考价值。
提出SRCNN问题
- context未充分利用
- Convergence 慢
- Scale Factor 训练指定fator的模型再重新训练其他fator的模型低效
context
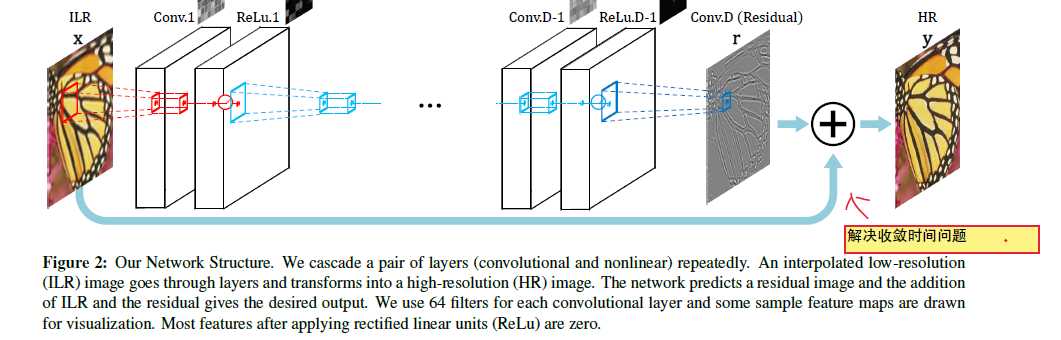
对于更大的scale-fator 需要更大的receptive-field(接受域,也就是过滤器),如果接受域学习了这张图像模式,也就能把这张图像重建成超分辨率图像,所以网络第一层是过滤器是 3 x 3 *64
往后每层的filter 大小为 (2D+1,2D+1),D为网络层数,第一层与最后一层的大小相同。
论文指出中央像素受周围像素所约束,所以类似SRCNN等crop的方法,将会导致边界信息不能很好的被周围像素推断,而作者则对input进行的padding再送入网络,这样也使得网络输出与输入相同。
(这里与SRCNN另外一个预处理方式不同的就是crop时不crop重叠部分)
Convergence
一张高分辨图片包含了低频信息(低分辨率图片)与高频信息(残差图像与图像细节)
论文指出SRCNN收敛慢的原因可能是SRCNN重建HR(重建高频信息)图像时重建了低频信息与高频信息,重建低频信息的过程类似自编码器,而本文则直接重建高频信息(残差图像与图像细节)
设 x 为 低分辨率图像, y 为高分辨率图像 则 f(x) 为预测的 y 值,使用均方差损失函数
![]()
因为输入与预测输出有很大相似,所以定义 r = y - x ,则损失函数 为:
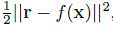
为了提高收敛速率,作者将学习速率初始化为 0.1 往后每20个epchos 降低 10倍,还使用了梯度剪枝
Single-Scale
大部分模型由指定的fator训练,对于特定的fator就重新训练,这很低效,作者把一个minibatch由不同缩放因子的64个sub-image组成放入网络训练,
训练结果证明了由特定fator训练的模型再更大的fator上测试性能不佳,而由多个fator上处理再训练的模型,性能超过Bicubic

模型预处理方式与SRCNN大部分相同:bicubic先下采样,后上采样作为输入图像
以上是关于VDCN的主要内容,如果未能解决你的问题,请参考以下文章