吴恩达机器学习105:和函数
Posted bigdata-stone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴恩达机器学习105:和函数相关的知识,希望对你有一定的参考价值。
一、
1.在这节课中我们将补充一些缺失的细节,并且介绍一些在实际中应用这些思想,例如怎么处理支持向量机中的偏差分析。上节课我们谈到选择标记点的过程,比如l(1),l(2)和l(3)使我们能够定义相似度函数,我们也称之为核函数,在这个例子中,我们的相似度函数为高斯核函数,这使得我们能够构造一个预测函数,但是我们从哪里能够得到这些标记点呢?从哪里得到l(1),l(2)和l(3)呢?
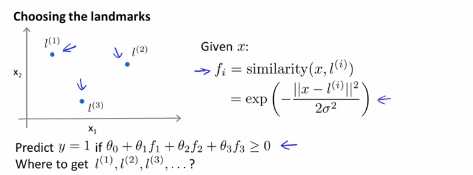
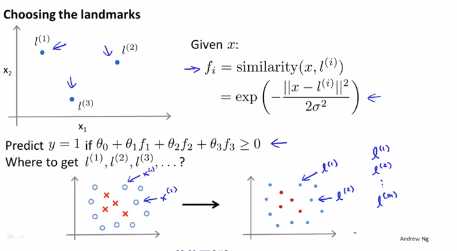
在一些复杂问题中我们也许需要跟多的标记点,而不是我们这里选择的三个点,因此在实际的学习问题中,怎么选取标记点,我们的数据集中有一些正样本和负样本,我们的想法是将选取样本点,我们拥有的每一个样本点,只需要直接使用它们,直接将训练样本作为标记点,如果我们有一个这样的训练样本x1,那么我们将在这个样本相同的位置上选作我们的第一个标记点,我们还有另一个训练样本x2,那么第二个标记就在与第二个样本点一至的位置, 右图的蓝色标记可以用l(m)进行标记:
这个过程挺不错的,这说明特征函数基本上式描述每一个样本的距离样本中其他样本的距离,我们列出基本的过程的大纲为:给定m个训练样本,我们将选取m个训练样本完全一样的位置上基本一致的位置作为我的标记点,当给定样本x,样本x可以作为训练集也可以属于交叉验证集或者属于测试集,给定样本x,我们来计算这些特征比如f1,f2等等。这里的l(1)等于x1,然后给了我们一个特征向量,我们先把f写成特征向量,把f1,f2,f3...组成特征向量,按照惯例额外的特征f0一直让它等于1,那么这个东西和我们之前的一样,对于x0就是截距。
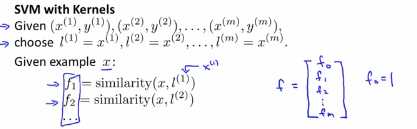
比如我们有一个训练样本(x(1),y(i)),我们对这个样本要计算的特征是这样的:给定x(i)我们将其映射到f1(i),即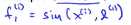 ,类似的f2(i)等于x(i)和f(2)之间的相似度,其他的相似度函数类似如下:
,类似的f2(i)等于x(i)和f(2)之间的相似度,其他的相似度函数类似如下:
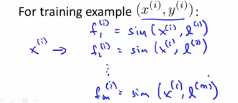
在这个映射列表中第i个元素,实际上有一个特征元素写作为fi(i),这是x(i)和l(i)之间的相似度,这里的l(i)就等于x(i),fi(i)
以上是关于吴恩达机器学习105:和函数的主要内容,如果未能解决你的问题,请参考以下文章