线程池ThreadPoolExecutor实现原理
Posted sunshine-ground-poems
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池ThreadPoolExecutor实现原理相关的知识,希望对你有一定的参考价值。
线程属于稀缺资源,对于线程的创建规则,引用《阿里巴巴 Java 手册》中的一条进行说明。

本篇从源码方面介绍ThreadPoolExecutor对象,并简要解析线程池工作原理。
首先ThreadPoolExecutor中定义了几个线程池状态常量。
// runState is stored in the high-order bits private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
- RUNNING是运行状态,线程池可以接收新任务
- SHUTDOWN是在调用shutdown()方法以后处在的状态。表示不再接收新任务,但队列中的任务可以执行完毕
- STOP是在调用shutdownNow()方法以后的状态。不再接收新任务,中断正在执行的任务,抛弃队列中的任务
- TIDYING表示所有任务都执行完毕
- TERMINATED为中止状态,调用terminated()方法后,尝试更新为此状态
看一下构造方法的参数
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { }
- corePoolSize是线程池的核心线程数
- maximumPoolSize是线程池允许的最大线程数
- keepAliveTime为线程空闲时的存活时间
- unit是keepAliveTime的单位
- workQueue是用来保存等待被执行的线程的队列
- threadFactory,线程工厂,通常使用默认工厂,定义了线程名称生成规则。
- handler是当最大线程数和队列都满了以后,线程池的处理策略
这里可以简单看下JDK中已有的4种饱和策略handler:
- AbortPolicy:默认策略,直接抛出异常,throw new RejectedExecutionException
- CallerRunsPolicy:如果线程池没有中止,直接用调用者的线程资源执行任务
- DiscardOldestPolicy:如果线程池没有中止,移除队列第一个任务,再执行当前任务
- DiscardPolicy:什么也不做,直接抛弃这个任务
也可以自定义饱和策略,只需实现RejectedExecutionHandler接口。
再看一下JDK中的workQueue队列:
- ArrayBlockingQueue:基于数组实现
- LinkedBlockingQueue:基于链表实现,默认容量Integer.MAX_VALUE
- SynchronousQuene:不存储元素,每个插入操作必须等待另一个线程调用移除操作
- priorityBlockingQuene:具有优先级的队列
JDK提供了Executors工厂类。这里面有几种实例化线程池的方法:
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
指定了线程数,且corePoolSize == maximumPoolSize。
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
可缓存线程池。最大线程数达到Integer.MAX_VALUE。所以在使用该线程池时,一定要控制并发数,不然会创建很多线程,占用大量资源。
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
只有一个线程的线程池,可以保证提交任务的顺序执行。
上面的实例方法都很方便,但是在开发中创建线程池时,最好不好使用Executors类中的初始化方法。见《阿里巴巴 Java 手册》:

最后看一下ThreadPoolExecutor执行任务的方法
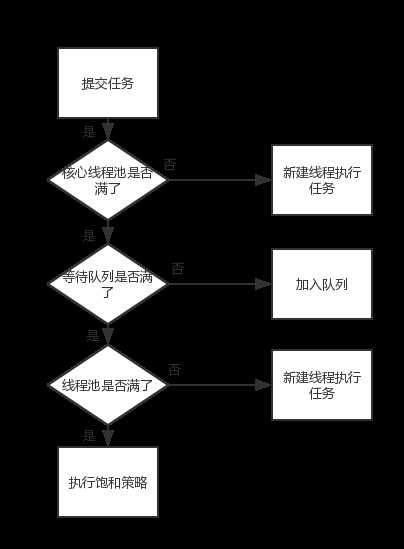
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command); }
- 判断command是否为空
- 获取线程状态
- 计算线程池中的线程数量,如果数量小于corePoolSize,就创建一个新线程执行任务
- 如果线程池正在运行状态,且写入队列成功。
- 再次获取线程池状态。判断,如果线程状态变成了非运行状态,就从队列中移除任务,调用reject()方法执行饱和策略handler
- 如果线程池为空,就创建一个新线程执行任务
- 如果第4步判断没有通过,尝试建立线程执行任务,若没有成功,就执行饱和策略handler
以一张简单的流程图描述上面的步骤:
以上是关于线程池ThreadPoolExecutor实现原理的主要内容,如果未能解决你的问题,请参考以下文章
通过ThreadPoolExecutor源码分析线程池实现原理
java同步之线程池ThreadPoolExecutor实现原理
JAVA基础学习之-ThreadPoolExecutor的实现原理