JPA配置,简单使用以及常见问题
Posted joe-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JPA配置,简单使用以及常见问题相关的知识,希望对你有一定的参考价值。
1.引入pom依赖
<!--springboot-JPA-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--mysql连接-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>2.配置数据源
spring:
datasource:
url: jdbc:mysql://localhost:3306/joe?serverTimezone=UTC
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
show-sql: true2.1 driver-class-name(驱动类)
根据mysql版本不同不一样,有的是com.mysql.cj.jdbc.Driver,有的是com.mysql.jdbc.Driver,不会报错,但是会有提示信息。
提示:Loading class com.mysql.jdbc.Driver‘. This is deprecated. The new driver class is com.mysql.cj.jdbc.Driver‘.
2.2 time zone 异常
异常:java.sql.SQLException: The server time zone value ‘?D1ú±ê×?ê±??‘ is unrecognized or represents more than one time zone.
解决:在datasource-url后拼接参数 serverTimezone=UTC
3.生成数据库表实体类domain
@Data
@Entity
@Table(name = "user")
public class User implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Long userId;
@Column(name = "user_name")
private String userName;
private Long age;
private String gender;
private String address;
}3.1 实体类建议用工具生成,因为jpa要求实体类中的字段都必须在数据库中找到对应列,即类属性只能比表字段少不能多,否则会报异常:
org.springframework.dao.InvalidDataAccessResourceUsageException
如何生成 IDEA自动生成JPA实体
3.2 数据库所有的表必须要有主键,jpa要求所有的表都必须有主键列,实体类必须有@Id标注,可以是联合主键,但是不能没有,没有的话会报异常:
org.hibernate.AnnotationException: No identifier specified for entity: com.joe.jpa.domain.User
联合主键如何使用 JPA联合主键
4.编写dao层
@Repository
public interface UserRepository extends JpaRepository<User, Integer> {
}1.jpa已经给我们提供了单表的增删改查操作,只需要在dao接口上实现 JpaRepository<T, ID>接口,就可以通过接口里的方法完成crud操作。
其中JpaRepository里的泛型,T是表的实体类,ID是表的主键对应的实体类属性数据类型,我这里是<User, Integer>。
5.测试类
即使自定义的UserRepository没有编写任何代码,注入后一样可以能使用 save(),findXXX(),delete(),count()等方法,并且测试有效,其实是JPA内部 CrudRepository 提供, SimpleJpaRepository 实现的,而 JpaRepository 是CrudRepository的子类,我们又实现了 JpaRepository所以就可以直接用。
详细类图在 JpaRepository 中 右键>Diagrams>show Diagrams...>java class Diagrams 可以查看。 图文步骤:IDEA查看类继承关系
5.1 保存
//保存和批量保存
@Test
public void testSave() {
//保存
User user = new User();
user.setUserName("张三");
user.setAge(23);
user.setGender("男");
userRepository.save(user);
log.info("保存成功,主键:{}", user.getUserId());
//批量保存
User user2 = new User();
user2.setUserName("李四");
user2.setAge(27);
user2.setGender("男");
User user3 = new User();
user3.setUserName("王五");
user3.setAge(25);
user3.setGender("女");
User user4 = new User();
user4.setUserName("赵六");
user4.setAge(26);
user4.setGender("女");
List<User> list = new ArrayList();
list.add(user2);
list.add(user3);
list.add(user4);
userRepository.saveAll(list);
log.info("批量保存成功");
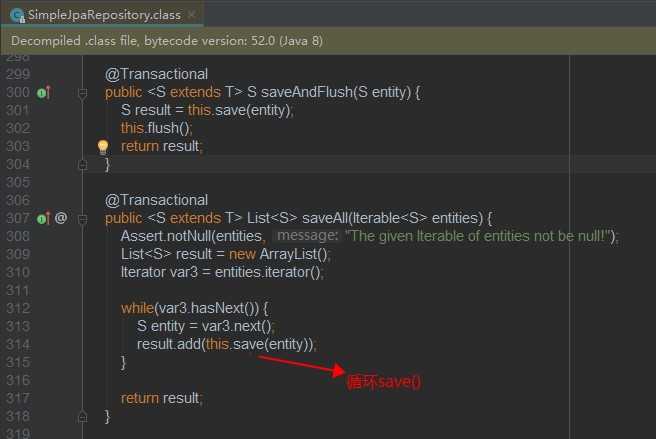
}JPA中提供了save() 单个数据保存和saveAll()批量保存的方法,但是批量保存也是循环执行的单条保存,
这个可以在运行时控制台打印的SQL或者直接从源码SimpleJpaRepository.saveAll()看出来,
所以大批量的插入最好不要用自带的saveAll()去执行。
批量插入的SQL语句

批量插入saveAll()源码
5.2 查询
JpaRepository提供的可以直接使用的查询虽然只有find()和findAll()两种,但是进行了多次重载,可以满足很多种场景的查询。
5.2.1 查询全部和主键查询
List<T> findAll();
Optional<T> findById(ID var1);
List<T> findAllById(Iterable<ID> var1);
示例:
@Test
public void testFindAll() {
List<User> userList = userRepository.findAll();
log.info("查询所有:{}", userList);
}
@Test
public void testFindById() {
//主键查询-查询一个
Optional<User> userOptional = userRepository.findById(2);
if (userOptional.isPresent()) {
log.info("根据主键查询:{}", userOptional.get());
}
//主键查询-查询多个
List<Integer> userIdList = Arrays.asList(new Integer[]{2, 3});
List<User> userListByIds = userRepository.findAllById(userIdList);
log.info("根据多个主键查询:{}", userListByIds);
}排序查询
List<T> findAll(Sort var1);
排序查询需要借助Sort类实现
Sort类实例化 Sort ageSort = Sort.by(Sort.Direction.DESC, "age");
第一个参数可以省略,默认为Sort.Direction.ASC,第二个参数为要排序的字段对应的实体类属性,例如
@Test
public void testFindSort() {
//Sort ageSort = Sort.by("age");
Sort ageSort = Sort.by(Sort.Direction.DESC, "age");//倒叙
List<User> userListSortByAge = userRepository.findAll(ageSort);
log.info("查询所有按照age倒叙:{}", userListSortByAge);
}条件查询
<S extends T> List<S> findAll(Example<S> var1);
条件查询需要借助Example类实现
Example实例化 Example<User> userExample = Example.of(user);
参数为装有带条件的数据库实体。例如:
@Test
public void testFindByExample() {
//等同条件查询
User user = new User();
user.setGender("男");
Example<User> userExample = Example.of(user);
List<User> userExampleList = userRepository.findAll(userExample);
log.info("性别为男的用户为:{}", userExampleList);
//等同条件查询唯一记录,如果查到两条会报错
User user2 = new User();
user2.setUserName("张三");
Example<User> oneUserExample = Example.of(user2);
Optional<User> oneUser = userRepository.findOne(oneUserExample);
log.info("名字叫张三的记录:{}", oneUser);
}分页查询
分页查询需要借助PageRequest类实现
PageRequest实例化: PageRequest pageParam = PageRequest.of(1, 2);
第一个参数为页码,第二个参数为页行数,注意jpa的页码是从0开始算的,传入0查询的是第一页数据。例如
@Test
public void testFindByPage() {
//分页查询 jpa页码是从0开始的,传入1的话,返回的是第二页的数据
PageRequest pageParam = PageRequest.of(1, 2);
Page<User> userListByPage = userRepository.findAll(pageParam);
long totalElements = userListByPage.getTotalElements();
int totalPages = userListByPage.getTotalPages();
List<User> content = userListByPage.getContent();
log.info("分页查询结果,总记录数:{},总页数:{},选定页数据:{}", totalElements, totalPages, content);
}以上所以的查询是JPA提供的可以直接使用的查询接口,所有的查询都是等值查询,即column=xxx ,
如要想实现 like, <,> ,isnull ,in等操作,需要手动写SQL或者借助 特殊查询类JpaSpecificationExecutor.findAll()和 查询条件类Specification实现。
jpa排序分组条件查询 jpa自定义查询和复杂条件查询
以上是关于JPA配置,简单使用以及常见问题的主要内容,如果未能解决你的问题,请参考以下文章