将句子表示为向量(上):无监督句子表示学习(sentence embedding)
Posted llhthinker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将句子表示为向量(上):无监督句子表示学习(sentence embedding)相关的知识,希望对你有一定的参考价值。
1. 引言
word emedding技术如word2vec,glove等已经广泛应用于NLP,极大地推动了NLP的发展。既然词可以embedding,句子也应该可以(其实,万物皆可embedding,Embedding is All You Need ^_^)。近年来(2014-2018),许多研究者在研究如何进行句子表示学习,从而获得质量较高的句子向量(sentence embedding)。事实上,sentence embedding在信息检索,句子匹配,句子分类等任务上均有广泛应用,并且上述任务往往作为下游任务来评测sentence embedding的好坏。本文将介绍如何用无监督学习方法来获取sentence embedding,是对近期阅读的sentence embedding论文笔记的总结(https://github.com/llhthinker/NLP-Papers#distributed-sentence-representations)。欢迎转载,请保留原文链接https://www.cnblogs.com/llhthinker/p/10335164.html
2. 基于词向量的词袋模型
获取sentence embedding最直接最简单的思路就是对一个句子中所有词的word embedding进行组合。这种方法最明显的缺点是没有考虑词序信息,但是足够简单高效,在一些任务上是很好的baseline。
2.1 平均词向量与TFIDF加权平均词向量
平均词向量就是将句子中所有词的word embedding相加取平均,得到的向量就当做最终的sentence embedding。这种方法的缺点是认为句子中的所有词对于表达句子含义同样重要。TFIDF加权平均词向量就是对每个词按照tfidf进行打分,然后进行加权平均,得到最终的句子表示。
2.2 SIF加权平均词向量
发表于2016年的论文A simple but tough-to-beat baseline for sentence embeddings提出了一种非常简单但是具有一定竞争力的句子向量表示算法。算法包括两步,第一步是对句子中所有的词向量进行加权平均,得到平均向量(v_s);第二步是移出(减去)(v_s)在所有句子向量组成的矩阵的第一个主成分(principal component / singular vector)上的投影,因此该算法被简记为WR(W:weighting, R: removing)。
第一步主要是对TFIDF加权平均词向量表示句子的方法进行改进。论文提出了一种平滑倒词频 (smooth inverse frequency, SIF)方法用于计算每个词的加权系数,具体地,词(w)的权重为(a / (a+p(w))),其中(a)为平滑参数,(p(w))为(估计的)词频。直观理解SIF,就是说频率越低的词在当前句子出现了,说明它在句子中的重要性更大,也就是加权系数更大。事实上,如果把一个句子认为是一篇文档并且假设该句中不出现重复的词(TF=1),那么TFIDF将演变成IF,即未平滑的倒词频。但是相较于TFIDF这种经验式公式,论文通过理论证明为SIF提供理论依据。对于第二步,个人的直观理解是移出所有句子的共有信息,因此保留下来的句子向量更能够表示本身并与其它句子向量产生差距。算法描述如下(其中(v_s, u)的shape均为[d, 1],(uu^T)为[d,d]的矩阵,d为词向量维度):

论文实验表明该方法具有不错的竞争力,在大部分数据集上都比平均词向量或者使用TFIDF加权平均的效果好,在使用PSL作为词向量时甚至能达到最优结果。当然,由于PSL本身是基于有监督任务(短语对)来训练词向量,因此PSL+WR能在文本蕴含或相似度计算任务上达到甚至打败LSTM的效果也在情理之中。代码开源在https://github.com/PrincetonML/SIF
3. 无监督句子表示学习
下面介绍的方法是在无标签语料上训练句子表示学习模型,基本思想都是在无标签训练数据上设计监督学习任务进行学习,因此这里所说的无监督句子表示学习着重于训练数据是无标签的。
3.1 Paragraph Vector: PV-DM与PV-DBOW
发表于2014年的论文Distributed representations of sentences and documents提出了两个模型用于学习句子和文档分布式表示(段落向量,Paragraph vector)。Paragraph Vector: A distributed memory model(PV-DM) 是论文提出的第一个学习段落向量的模型,如下图:
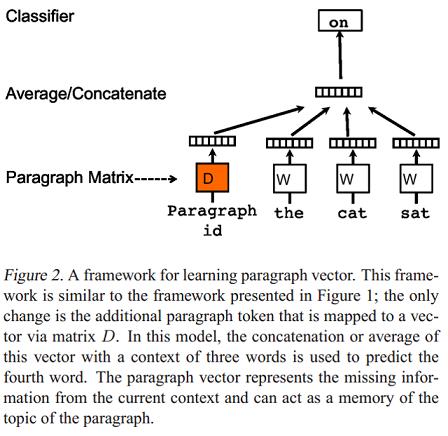
模型的具体步骤如下:
- 每个段落都映射到一个唯一的向量,由矩阵(D?)中的一列表示,每个词也被映射到一个唯一的向量,表示为(W?) ;
- 对当前段落向量和当前上下文所有词向量一起进行取平均值或连接操作,生成的向量用于输入到softmax层,以预测上下文中的下一个词: [y=b+Uh(w_{t-k}, dots, w_{t+k}; W; D)?]
这个段落向量可以被认为是另一个词。可以将它理解为一种记忆单元,记住当前上下文所缺失的内容或段落的主题 。矩阵(D?) 和(W?) 的区别是:
- 通过当前段落的index,对(D) 进行Lookup得到的段落向量,对于当前段落的所有上下文是共享的,但是其他段落的上下文并不会影响它的值,也就是说它不会跨段落(not across paragraphs) ;
- 当时词向量矩阵(W)对于所有段落、所有上下文都是共享的。
Paragraph Vector without word ordering: Distributed bag of words (PV-DBOW) 是论文提出的第二个学习段落向量的模型,如下图:
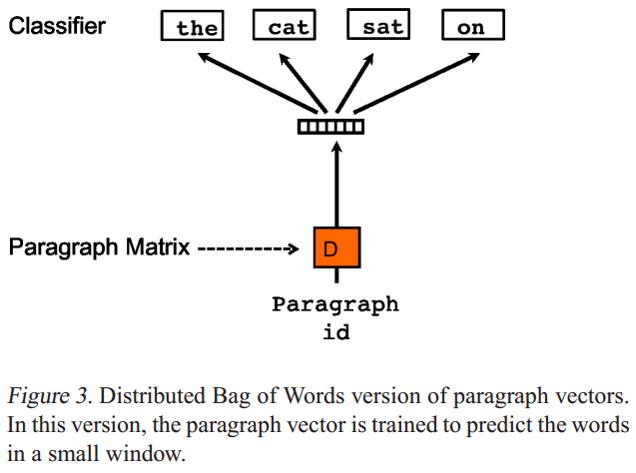
- PV-DBOW模型的输入忽略了的上下文单词,但是关注模型从输出的段落中预测从段落中随机抽取的单词;
- PV-DBOW模型和训练词向量的Skip-gram模型非常相似。
PV-DM与PV-DBOW的优点它们不仅能获取句子向量,也能获取文档级别向量。论文的工作很有影响力,具体实现已经集成在gensim包中。
3.2 利用篇章级文本的句子连贯性
2014年发表的论文A Model of Coherence Based on Distributed Sentence Representation提出了一种基于分布式句子表示的模型,用来判断文本连贯性(Coherence)。模型的输入是多个句子(a window of sentences),输出是这些句子是连续的概率。模型的主要步骤如下:
- 对每个句子进行编码:论文实现了循环神经网络编码和递归神经网络编码两种方式,将每个句子表示成一个(k imes 1)的语义向量(h_{s_i}, i = 1,...,L),其中(L)为句子个数(窗口大小);
- 将一个窗口内的所有句子的语义向量进行级联,得到大小为((L imes k) imes 1)的语义向量(h_C = [h_{s_1},h_{s_2},...,h_{s_L}])后,进行非线性变换,即(q_C=tanh(W_{sen} imes h_C + b_{sen})),得到大小为(H imes 1)的隐藏层语义表示向量(q_C),其中(W_{sen})为大小为(H imes (L imes k))的矩阵,(b_{sen})为大小为(H imes 1)的偏移向量;
- 最后将(q_C)输入到全连接层进行二分类,即(p(y_C=1) = sigmoid(U^Tq_C + b)),其中(y_C=1)表示该窗口中的句子是连贯的,等于0则表示不连贯。
给定一篇包含(N_d)个句子的文档(d={s_1,s_2, ...,s_{N_d}}),假设(L=3),可以生成如下的样本:
[ < s _ { ext{start} } , s _ { 1 } , s _ { 2 } > , < s _ { 1 } , s _ { 2 } , s _ { 3 } > , ldots \\ < s _ { N _ { d } - 2 } , s _ { N _ { d } - 1 } , s _ { N _ { d } } > , < s _ { N _ { d } - 1 } , s _ { N _ { d } } , s _ { e n d } > ]
文档(d)的连贯性得分(S_d)可以定义为所以样本连贯性概率的乘积(得分越大表示越连贯),即
[
S _ { d } = prod _ { C in d } p left( y _ { C } = 1
ight)
]
虽然论文的任务是判断文本连贯性,给了后续的研究者研究句子分布式表示的启示:类似于word2vec中使用相邻词预测的方式来获得word embedding,可以通过句子连贯性这个任务自动构建数据集,无需标注即可得到sentence embedding。
3.3 基于Encoder-decoder的Skip-Thought Vectors
2015年发表的论文Skip-Thought Vectors提出了Skip-Thought模型用于得到句子向量表示Skip-Thought Vectors。基本思想是word2vec中的skip-gram模型从词级别到句子级别的推广:对当前句子进行编码后对其周围的句子进行预测。具体地,skip-thought模型如下图,给定一个连续的句子三元组,对中间的句子进行编码,通过编码的句子向量预测前一个句子和后一个句子。Skip-Thought向量的实验结果表明,可以从相邻句子的内容推断出丰富的句子语义。代码开源在https://github.com/tensorflow/models/tree/master/research/skip_thoughts

模型的基本架构与encoder-decoder模型类似,论文中使用的encoder和decoder都为GRU,使用单向GRU称为uni-skip,双向GRU称为bi-skip,将uni-skip和bi-skip生成的sentence embedding进行concat称为combine-skip。论文通过大量实验对比了上述三种变体的效果,总体上来说是uni-skip < bi-skip < combine-skip。
词表扩展是该篇论文的重要trick。skip-thought模型的词表规模往往是远小于现实中的词表(如用海量数据训练的word2vec)。为了让模型能够对任意句子进行编码,受论文Exploiting similarities among languages for machine translation的启发,本文训练一个线性映射模型,将word2vec的词向量映射为skip-thought模型encoder词表空间的词向量。假设训练后的skip-thought模型的词向量矩阵为X,大小为[num_words,dim1],即词表大小为num_words,词向量维度为dim1,这num_words个词在word2vec中对应的词向量矩阵为Y,大小为[num_words, dim2],即word2vec的词向量维度为dim2。我们的目的是word2vec中的词向量通过线性变换后得到词向量与skip-thought模型encoder空间的词向量无限接近,因此最小化线性回归(loss= || X - Y * W ||^2)。得到这个线性模型后,假设待编码的句子中的某个词不属于skip-thought词表,则首先在word2vec词表中进行look up得到word2vec对应的词向量,再通过线性模型映射为skip-thought模型encoder空间的词向量。
3.4 基于AutoEncoder的序列去噪自编码器(SDAE)
2016年发表的论文Learning Distributed Representations of Sentences from Unlabelled Data提出的第一种模型称为序列去噪自编码器(SDAE: Sequential Denoising AutoEncoder)。AutoEncoder包括编码器和解码器两部分,输入信息通过编码器产生编码信息,再通过解码器得到输入信息,模型的目标是使输出信息和输入信息原来越接近。DAE (Denoising AutoEncoder)表示模型的输入信息首先经过了噪声处理后再进行编码和解码,并且希望解码的输出信息是不含噪声的输入信息,即去噪。DAE常用于图像处理,本文提出SDAE模型表示用来处理变长的句子(序列)。具体地,给定句子(S),采用噪声函数:(N(S|p_0,p_x)),其中(p_0, p_x)为0到1之间的概率值。首先,对于(S)中的每个词(w),噪声函数(N)按照概率(p_0)随机删除(w),然后对于(S)中每个不重叠的bigram (w_iw_{i+1}),噪声函数(N)按照概率(p_x)对(w_i)和(w_{i+1})进行交换。论文采用基于LSTM的encoder-decoder模型,SDAE的目标是预测出原始句子(S)。SDAE模型在验证集上对超参数(p_0,p_x in {0.1, 0.2, 0.3})进行搜索,得到当(p_0=p_x=0.1)为最优结果。论文还尝试令(p_0=p_x=0?)进行对比实验,SDAE模型即变成了SAE模型。 SDAE模型相较于Skip-Thought的优点是只需要输入单个句子,即不要求句子所在的文本是有序的,而Skip-Thought的输入必须是三个有序的句子。
3.5 基于词袋模型的FastSent
2016年发表的论文Learning Distributed Representations of Sentences from Unlabelled Data提出的第二种模型称为FastSent,Skip-Thought模型采取语言模型形式的编码解码方式,导致其训练速度会很慢。FastSent采取了BoW(词袋)形式的编码方式,使得模型训练速度大幅提高,因此称为FastSent。具体地,给定一个连续的句子三元组(S_{i-1}, S_i, S_{i+1}),对中间的句子(S_{i})进行编码,编码方式是(S_i)中所有词的词向量之和,即(mathbf { s } _ { mathbf { i } } = sum _ { w in S _ { i } } u _ { w }),然后根据(mathbf { s } _ { mathbf { i } })对(w in S_{i-1} cup S_{i+1}?)进行预测,这与word2vec模型中的skip-gram基本一致,而无需像Skip-Thought一样按照句子中词的顺序生成(预测)。因此FastSent的损失函数如下:
[
sum _ { w in S _ { i - 1 } cup S _ { i + 1 } } phi left( mathbf { s } _ { mathbf { i } } , v _ { w }
ight)
]
其中(phi left( v _ { 1 } , v _ { 2 }
ight))为softmax函数,(v_w)为目标句子中的词(w)的embedding。论文还提出了一种变体模型FastSent+AE,该变体不光是预测前后两个句子中的词,还预测本身句子的词,损失函数即为:
[
sum _ { w in S _ { i - 1 } cup S _ { i } cup S _ { i + 1 } } phi left( mathbf { s _ { i } } , v _ { w }
ight)
]
模型训练后,测试阶段,FastSent能够通过计算句子中所有词向量的和迅速得到句子embedding,即:(mathbf { s } = sum _ { w in S } u _ { w }?)。
论文通过两种类型的下游任务来评测句子分布式表示的质量,分别为监督类型(包括释义识别,文本分类)和非监督类型(语义相关性:SICK数据集与STS数据集,直接计算句子向量的余弦相似度并与人类打分进行比较)。实验结果为SDAE模型在监督类型评测上比CBOW(将CBOW类型词向量直接相加得到句子向量)和Skipgram等简单模型要好,但是在非监督类型评测上结果却相反。类似地,Skip-Thought模型在监督类型评测上比FastSent模型效果好,但在非监督类型评测上,FastSent要好于Skip-Thought。实验结果表明,最佳方法主要取决于预期的应用。 更深,更复杂的模型(同时也需要更多的计算资源和训练时间)更适用于监督类型评测,但浅的对数线性模型更适合无监督类型评测。
3.6 利用n-grams embedding
2017年发表的论文Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features 提出利用n-grams来学习句子表示模型Sent2Vec,是word2vec模型中CBOW形式的扩展:不仅仅使用窗口中的词(uni-gram)来预测目标词,而是使用窗口中所有的n-grams来预测目标词(uni-gram)。为了得到句子向量,将句子看成一个完整的窗口,模型的输入为句子中的n-grams,目标是预测句子中的missing word(目标词),而句子向量是所有n-grams向量表示的平均。本文的模型与论文Enriching word vectors with subword information(FastText)很类似,主要区别有两点,其一是本文的模型输入是词级别的n-grams序列而FastText是字符级别的n-grams序列,其二是本文最终的表示是对输入的n-grams embedding进行平均而FastText是相加。代码开源在https://github.com/epfml/sent2vec
3.7 Quick-Thought vectors
2018年发表的论文An efficient framework for learning sentence representations提出了一种简单且有效的框架用于学习句子表示。和常规的编码解码类模型(如skip-thoughts和SDAE)不同的是,本文采用一种分类器的方式学习句子表示。具体地,模型的输入为一个句子(s)以及一个候选句子集合(S_{cand}),其中(S_{cand})包含一个句子(s_{ctxt})是(s)的上下文句子(也就是(s)的前一个句子或后一个句子)以及其他不是(s)上下文的句子。模型通过对(s)以及(S_{cand})中的每个句子进行编码,然后输入到一个分类器中,让分类器选出(S_{cand})中的哪个句子是(s_{ctxt})。实验设置候选句子集合大小为3,即(S_{cand}?)包含1个上下文句子和两个无关句子。模型结构如下:

模型有如下两个细节需要注意:
- 模型使用的分类器(得分函数)(c)非常简单,是两个向量内积,即(c(u, v)=u^Tv),计算(s)的embedding与所有(S_{cand})中的句子向量内积得分后,输入到softmax层进行分类。使用简单分类器是为了引导模型着重训练句子编码器,因为我们的目的是为了得到好的句子向量表示而不是好的分类器。
- 虽然某些监督任务模型如文本蕴含模型是参数共享的,(s)的编码器参数和候选句子编码器参数是不同的(不共享),因为句子表示学习往往是在大规模语料上进行训练,不必担心参数学习不充分的问题。测试时,给定待编码句子(s),通过该模型得到的句子表示是两种编码器的连结 ([ f ( s ) ;g ( s ) ])。
论文将上述模型命名为quick thoughts(QT),意味着该模型能够迅速有效地学习句子表示向量。模型使用GRU作为Encoder,为了和Skip-Tought模型进行比较,模型包含三种变体,使用单向GRU称为uni-QT,双向GRU称为bi-QT,将uni-QT和bi-QT生成的sentence embedding进行concat称为combine-QT。此外,论文将同时使用预训练词向量和随机初始化词向量的模型称为MultiChannel-QT(MC-QT),这种设置是参照multi-channel CNN模型。
论文通过多个句子分类任务证明QT模型了的优越性:
- 相较于其他无监督句子表示学习方法,QT在训练时间较少的情况下(相较于Skip-Thought、SDAE),能够达到非常不错的效果,在大多数数据集上的效果都是最好的。
- 与监督句子表示学习方法(如InferSent等)对比,QT(MC-QT)同样能够在大多数数据集上取得最优效果。
- 与专门用于句子分类任务模型(如CNN)对比,QT使用ensemble,考虑模型类型(单向/双向),词向量(随机/预训练)以及数据集(BookCorpus/UMBC )三个方面进行训练不同的模型进行集成,也取得了有竞争力的效果。
论文还通过image-sentence ranking和nearest neighbors两个实验来为QT有效性提供依据。代码开源在https://github.com/lajanugen/S2V
4. 总结
- 词向量的平均或加权平均是一个简单有效的baseline,基于SIF词向量加权平均的在一些任务上甚至比复杂模型的效果好。
- Paragraph Vector模型足够简单,并且能够编码文档级文本,但是对于sentence embedding,其效果相较于其他方法不具竞争力。
- Skip-Thought,FastSent和Quick-Thought都是基于句子连贯性设计任务:
- 基于encoder-decoder的Skip-Thought模型最复杂,在监督类型评测上比FastSent模型效果好,但在非监督类型评测上,FastSent要好于Skip-Thought。
- Quick-Thought作为一个最新的模型,其复杂度介于FastSent和Skip-Thought之间,但在大多数任务上的效果比其他两个模型都好。
- 相较于Skip-Thought,FastSent和Quick-Thought,SDAE模型与利用n-grams的Sent2Vec模型的优点是只需要输入单个句子。此外,Sent2Vec模型效果比SDAE模型好一些。
给读到这里的朋友点个赞,下一篇将介绍如何利用有监督学习来训练sentence embedding,我的github仓库https://github.com/llhthinker/NLP-Papers包含了近年来深度学习在NLP各领域应用的优秀论文、代码资源以及论文笔记,欢迎大家star~
References
- Le and Mikolov - 2014 - Distributed representations of sentences and documents
- Li and Hovy - 2014 - A Model of Coherence Based on Distributed Sentence Representation
- Kiros et al. - 2015 - Skip-Thought Vectors
- Hill et al. - 2016 - Learning Distributed Representations of Sentences from Unlabelled Data
- Arora et al. - 2016 - A simple but tough-to-beat baseline for sentence embeddings
- Pagliardini et al. - 2017 - Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features
- Logeswaran et al. - 2018 - An efficient framework for learning sentence representations
以上是关于将句子表示为向量(上):无监督句子表示学习(sentence embedding)的主要内容,如果未能解决你的问题,请参考以下文章