前嗅ForeSpider教程:采集新浪新闻
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前嗅ForeSpider教程:采集新浪新闻相关的知识,希望对你有一定的参考价值。
最近后台有很多童鞋问怎么采集新闻,今天小编以采集新浪新闻为例,来为大家进行演示,同样适用于其他新闻网站的采集,具体操作如下:
?
第一步:新建任务
①点击左上角“加号”新建任务,如图1:
?
②在弹窗里填写采集地址,任务名称,如图2: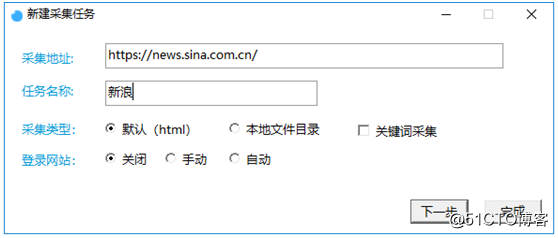
③点击下一步,选择进行数据抽取还是链接抽取,本次采集当前列表页新闻的正文数据,正文数据是通过点击列表链接进入的,所以本次需要抽取列表链接,所以点击抽取链接,如图3: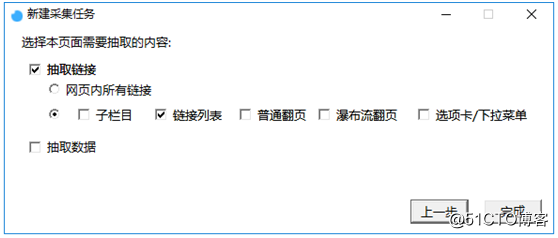
第二步:通过定位过滤、地址过滤,得到所需链接
①按住Ctrl+鼠标左键,进行区域选择,按住Shift+鼠标左键,扩大选择区域,点击“确认选区”按钮,如图4: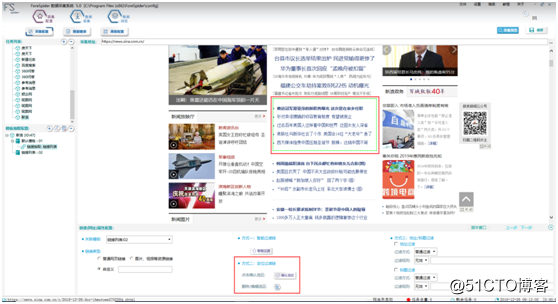
②点击采集预览,在采集预览中有于目标链接相似的其他链接,可通过地址过滤得到列表链接。找到所需要的列表链接,观察得出所需要的目标链接都包含“sina.com.cn/+字符串”。使用过滤串“c”,右击复制链接,如图5所示。过滤串规则说明:c??表示一串(个)小写字母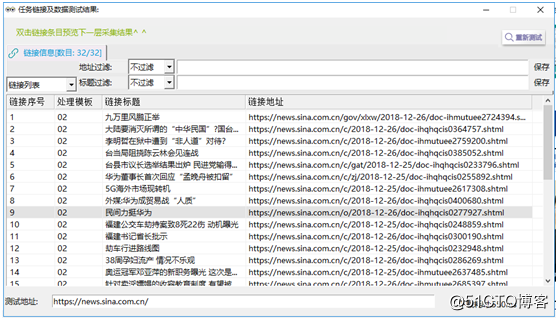
③勾选地址过滤,过滤规则选择包含,填入“sina.com.cn/c”,得到列表链接,如图6所示。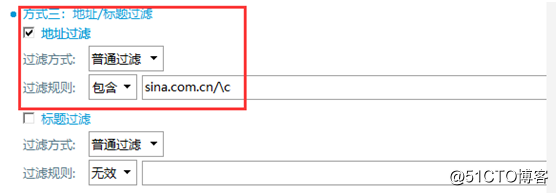
④点击采集预览确认链接是否过滤完全,如图7: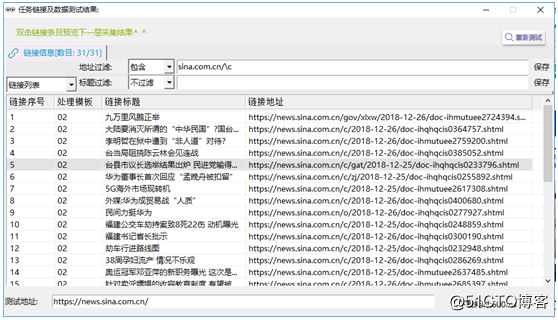
第三步:关联模板
在软件中模板的关联关系,与网页中链接跳转的关系相同。根据网页跳转规律,将“链接列表”关联模板二“链接列表:02”,此处由于我们开始就选择了创建列表链接,所以软件自动关联好了模板二。如果配置的时候发现关联有问题,可以自己进行更改,如图8: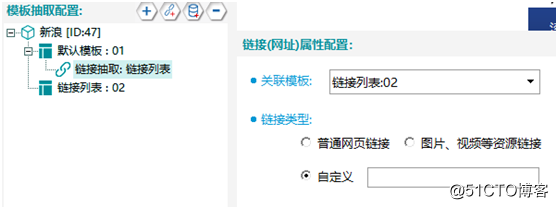
第四步:填写模板二示例地址并新建数据抽取
①?模板一过滤得到的任意一条链接,作为模板二的示例地址。如https://news.sina.com.cn/c/zj/2018-12-25/doc-ihqhqcis0255892.shtml, 见图9: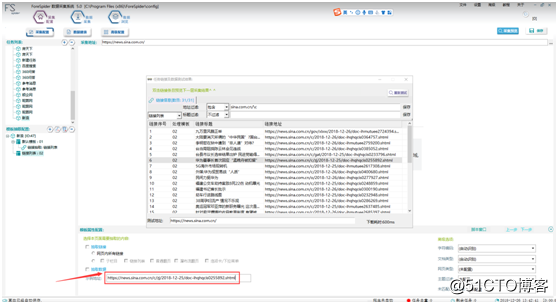
②新建数据抽取
方法一:通过点击“下一步”后勾选抽取数据,再次点击“下一步”得到数据抽取。
方法二:直接点击模板二,点击上面“新建数据抽取”按钮,得到数据抽取,重命名为新浪新闻,如图10:
第五步:创建/选择表单
在ForeSpider爬虫中,表单是可以复用的,所以可以在数据表单出直接选择之前建过的表单,也可以通过表单ID来进行查找并关联数据表单。此处使用的是之前建过的新浪网的表单。
方法一:通过下拉菜单或表单ID选择已有表单
方法二:点击创建表单进入快速建表页面,新建表单,如图11所示: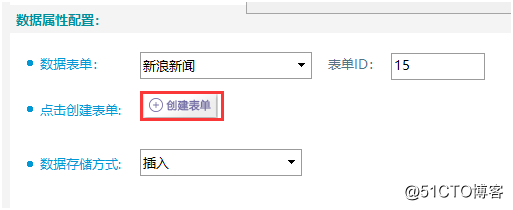
方法三:点击“采集配置”-“数据建表”,点击采“采集表单”后面的如图12:
第六步:配置表单
根据所需内容,配置表单字段(即表头),此处配置了包括网页主键、网页标题、网页地址、网页创建时间、内容、发布来源6个字段,表单如图13: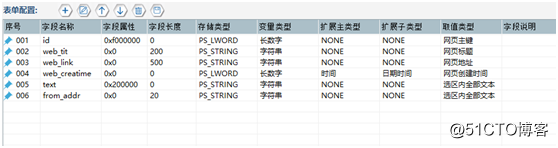
第七步:字段取值
取值方法:按住Ctrl+鼠标左键,进行区域选择,按住Shift+鼠标左键,扩大选择区域。点击“确认选区”按钮,确认操作。text、from_addr字段,如图14: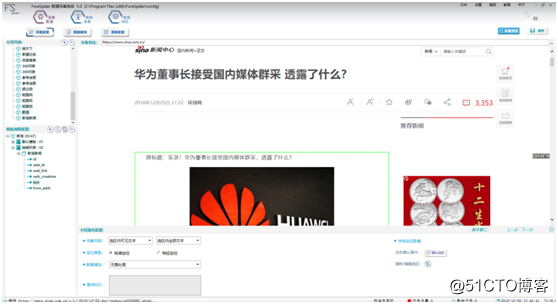
第八步:模板预览
①鼠标右键点击“数据抽取”,然后点击“模板预览”,如图15: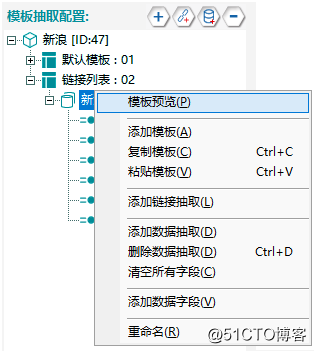
②预览结果如图16: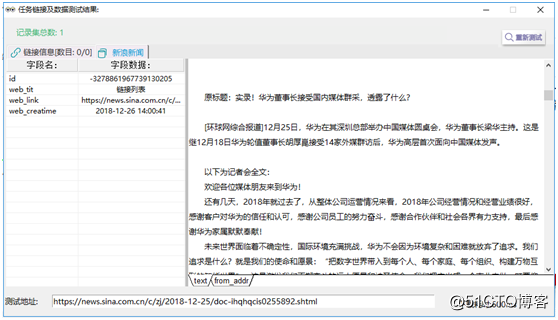
第九步:采集预览
①点击右上角采集预览,如图17: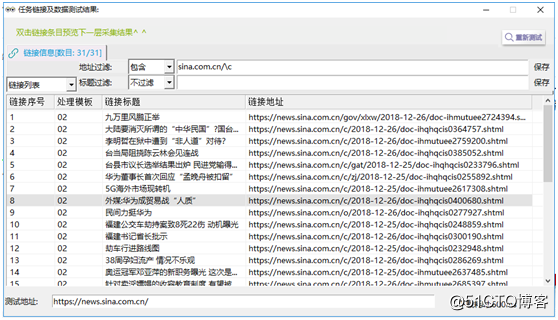
②双击任意一条链接,看看是否可以得到和网页对应的规整的数据,如图18: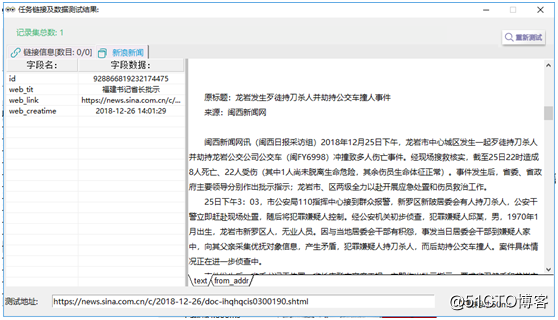
以上是关于前嗅ForeSpider教程:采集新浪新闻的主要内容,如果未能解决你的问题,请参考以下文章
前嗅ForeSpider教程:通过链接列表采集正文数据(不翻页)