程序相似性判断
Posted weimingai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序相似性判断相关的知识,希望对你有一定的参考价值。
一、问题分析
基本任务:
对于两个C语言的源程序清单,用哈希表的方法分别统计两程序中使用C语言关键字的情况,并最终按定量的计算结果,得出两份源程序清单的相似性。
任务要求:
C语言关键字的Hash表可以自建,也可以如实现提示中那样构建。此题的主要工作是扫描给定的源程序,累计在每个源程序中C语言关键字出现的频度。在扫描源程序过程中,每遇到关键字就查找Hash表,并累加相应关键字出现的频度。为保证查找效率,建议Hash表的平均查找长度ASL不大于2。
二、程序设计
解决方案:
本程序根据要求和实现提示设计思路,首先要实现在哈希表中的关键字查找和统计先要设计哈希表的结构以及使用到的操作并进行实现,其次要实现对C语言程序中所有字符串在哈希表中进行查找,会多余出大量的无效查找增加哈希表的查找次数和时间复杂度,所以根据实现提示,采用查找速度更快捷、占用空间更小的键树结构进行过滤,所以下一步设计C语言关键字的键树结构并实现过滤操作,程序一边读取C程序清单中的字符串,一边将字符串在键树结构中进行查找,如果存在则继续在哈希表中进行查找,查询成功一次则将哈希表结点中的nvalue值加一,记录频数,最后,实现主体函数的设计,即整个程序中主调程序的实现过程。
方案理论:
(1) 哈希表构建的具体理念
本程序哈希表结构的构造方法采用较为简单且常用的除留余数法,以除留余数法构造哈希函数并进行关键字寻址,采用较为简单且方便有效的二次探测再散列的方法处理哈希结点构造中的冲突。
C语言有32个关键字,假设以二次探测再散列处理冲突,为达到ASL≤2,则要求装载因子a≤0.795,因关键字个数n=32,应取表长m>40。对于二次探测再散列,应取4j+3型的素数,故设表长m=43。最后根据所设表长设计Hash函数。采用除留余数法,并取p=41,设
hash(key)=[(key的首字符序号)*100+(key的尾字符序号)] mod 41
冲突处理方法为
Hi+1, i+2 = ( H1± i2 ) mod 41 i = 1, 2, 3, …
(2)键树构建的具体理念
本题很大的工作量将是对源程序扫描,区分出C程序的每一关键字。可以为C语言关键字建一棵键树,扫描源程序和在键树中查找同步进行,以取得每一个关键字。使用查找速度较快的顺序数组存储结构建立Trie树,在键树结构中设置根节点并其中记录孩子结点数目和孩子结点的数组,分支结点的构造类似根节点,在叶子结点中设置指向存储关键字字符串的指针,从而构建起字典查询键树。
(3)程序相似性判断的具体理念
根据程序1和程序2中关键字出现的频度,可提取到两个程序的特征向量X1和X2。
一般情况下,可以通过计算向量Xi和Xj的相似值来判断相应的两个程序的相似性,相似值判别函数计算公式为
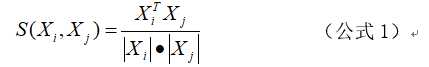
其中 。 的值介于[0, 1]之间,也称广义余弦,即 ,当 时,显见 ;当 和 差别很大时, 的值近似为0,θ就接近于∏/2。
尽管 和 的值是一样的,但直观上Xi与Xj更相似。因此当S值接近于1时,为避免误判相似性(可能是夹角很小,模值差很大的向量),应当再次计算Xi与Xj之间的“几何距离” 。其计算公式为
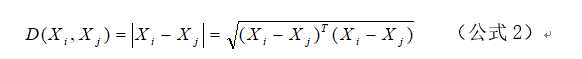
最后的相似性判别计算可分两步完成:
① 用公式1计算S,把接近1的保留,抛弃接近0的情况(即排除不相似者)
② 对保留下来的特征向量,再用公式2计算D,如D值也比较小,说明两者对应的程序确实可能相似。并根据实际经验给出S>0.9,D<10时说明两个程序的相似程度较高。
(4) 设计理论误差说明:
这种判断方法只是提供一种辅助手段,即便S=1也可能不是同一个程序,S的值很小,也可能算法完全是一样的。例如一个程序使用while语句,另一个使用for语句,但功能完全相同。事实上,当发现S的值接近于1且D又很小时,就应该以人工干预来区分。
抽象数据定义:
(1)Trie树:
ADT List{
数据对象:D={}
数据关系:RI={,i=2,….n}
基本操作:
Node* CreateTrie();
操作结果:构造一个Trie树。
void insert_node(Trie_node root, char *str) ;
初始条件:Trie树已经存在。
操作结果:在Trie树中插入结点,结点字符串为str。
int search_str(Trie_node root, char *str);
初始条件:Trie树已经存在。
操作结果:在Trie树中查找字符串str,存在返回1,否则返回0。
void del(Trie_node root) ;
初始条件:Trie树已经存在。
操作结果:释放整个Trie树的内存空间。
}
(1)哈希表:
ADT List{
数据对象:D={}
数据关系:RI={,i=2,….n}
基本操作:
void hash_table_init();
操作结果:初始化哈希表,并为其分配内存空间。
int hash_table_hash_str(char* skey);
初始条件:哈希表已经存在。
操作结果:构造哈希函数,返回值为哈希函数计算的地址。
HashNode* hash_table_lookup(char* skey) ;;
初始条件:哈希表已经存在。
操作结果:在哈希表中查找字符串str 。如果查找成功则将字符串的nvalue值加1。
void hash_table_insert(char* skey);
初始条件:哈希表已经存在。
操作结果:向哈希表中插入字符串skey。
void hash_table_print();
初始条件:哈希表已经存在。
操作结果:打印哈希表中的结点。
void hash_table_release();
初始条件:哈希表已经存在。
操作结果:释放哈希表的存储空间。
void hash_table_revalue();
初始条件:哈希表已经存在。
操作结果:使哈希表中所有结点nvalue值为0。
void hash_table_nvalue();
初始条件:哈希表已经存在。
操作结果:将哈希表中的所有nvalue输入到value1.txt文件中。
}
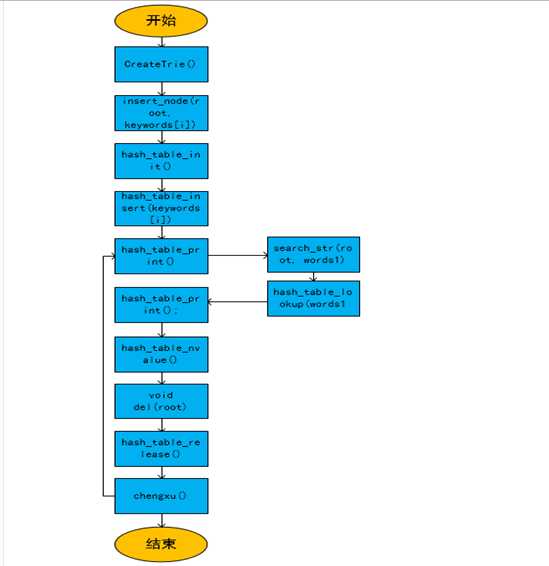
函数调用图:
三、程序源码(伪代码,具体代码实现可以参考github地址:)
Trie树:
#define定义分支结点的最大个数
typedef struct构建Trie树的模板
{
int 标记该节点是否可以形成一个单词
struct Tree *声明它的子树结点
}Node, *Trie_node;
Node* CreateTrie()创建Trie树
{
为Trie树的叶子结点分配空间
分配空间
返回叶子结点指针
}
//Trie树的结点插入
void insert_node(Trie_node root, char *str)
{
if根节点为NULL或者字符串为空
中断插入并返回
声明一个指向根结点的指针
声明一个指向字符串的指针
while被指向的字符不为结尾空字符
{
if根结点的孩子中这个字母为首的结点为空
{
创建一个结点
将孩子结点指向这个所建立的叶子结点
}
指针指向子节点
字符串指针后移
}
标记该结点为1,即存在指向字符串的指针
}
int search_str(Trie_node root, char *str)查找串是否在该trie树中
{
if如果Trie树为空或者待查找的字符串为空
{
中断并返回
}
否则声明指针指向字符串即首个字符
/声明指针指向Trie树根节点;
while 不到到字符串尾
// 依次逐层查找
}
void del(Trie_node root)释放整个Trie树占的堆空间
{
//循环不为空,直接释放
free(root);释放结点的空间
}
Hash表:
#define哈希表的数组总个数
typedef struct HashNode_Struct HashNode;/声明哈希表的结点结构
struct HashNode_Struct//写出哈希表的结点模板
{
哈希结点中的关键字
哈希结点中的权值
记录冲突的次数
};
//定义哈希表
//定义哈希表中实际数组的大小
//初始化哈希表
void hash_table_init()
//构造哈希函数
int hash_table_hash_str(char* skey)
{
设置指针指向要传递的字符串
声明一个新的int值
循环算一下字符的长度并依次向后移动指针
if如果指针指向了空的地方
break;//跳出循环
计算哈希值
返回计算出的数组序号
}
//将结点插入哈希表
void hash_table_insert(char* skey)
{
if判断哈希表的实际元素数目是否已经超过了哈希表的规定数组长度
{
并中断返回
}
通过哈希函数计算出数组的序号
声明一个指针指向待插向的结点
while这个结点已经没被占用了
{
if这个结点的值与带插入的结点值相等
{ return;//中断并返回
}
else //继续进行二测探测
}
声明一个新的结点并为其分配向量空间
分配指针空间
为结点的关键字分配动态存储空间
复制待插入字符串到刚刚分配的结点的关键字
将待出入的value值付给刚刚建立的结点的value
hash_table_size++;//哈希表的实际长度加一
}
//在哈希表中查找一个关键字
HashNode* hash_table_lookup(char* skey)
{
通过哈希函数计算出数组的序号;
if对应结点存在值
{
声明一个新的结点指针指向该结点
while新的结点指针指向的结点的值存在
{
if
{//如果要查找的关键字与指向结点道德关键字相等
nvalue+1;
返回该节点
}
//继续进行二测探测
}
如果对应结点值不存在,则返回空值
}
//打印哈希表中的存在的结点
void hash_table_print()
{
for从头遍历哈希表的结点数组
{
声明新的结点指针指向该结点
if 结点1存在
{
/打印结点
}
}
}
//释放整个哈希表的内存空间
void hash_table_release()
{
for从头遍历哈希表的结点数组
{
if如果结点不为NULL
{
释放这个结点的空间吧
}
}
}
//使哈希表中的所有权值为0
void hash_table_revalue()
{ for//从头遍历哈希表的结点数组
{
//使结点的权值为0
}
}
void hash_table_nvalue()
{
//从头遍历哈希表的结点数组
{
输入文件中
}
主程序:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include "Hash.h" //调用哈希结构头文件
#include "Trie.h" //调用键树结构头文件
声明chengxu函数
int main()
{
声明一个存储关键字的二维数组
将keywords文件读入并打印
//对C语言中的关键字建立键树
声明字符数组存储字符串
声明一个键树的根节点
初始化一个键树
循环在键树中依次插入之前数组存储的关键字
//对C语言中的关键字建立哈希表
初始化哈希表
循环在哈希表中依次插入关键字
输出哈希表
//读取并计算第一个源程序
打印提示操作的字符
声明存储程序1文件名的数组
获取输入,并将其存储到chengxu1数组中
声明打开程序1文件的指针
声明一个char字符,用于读取传递
声明一个words数组,存储从chegxu1文件中读取的字符
while (循环到文件尾
{
if如果ch1是小写英文字母,words依次数组读取
else if ((如果ch1不是英文字母判断words首个字符是否为英文字符
{
if (如果是则查询键树
h键树存在则查询哈希
将i值重新赋值为0
将words字符数组重新赋值为‘ ‘
}
else如果words数组首字符不是英文字母,将words数组重新归为空字符串
}
关闭文件
打印第一次查询后的哈希表状态
//调用头文件中函数,将哈希表中的频数写入value1.txt文件
声明int数组
将value1.txt文件中的值读入value1数组
将哈希表中的所有频数归为0
将释放Trie树空间
释放哈希表的存储空间
//对C源程序2进行查询计算
调用函数读取下一个程序文件,并将频数写入value1.txt文件
声明数组value2
将value1.txt文件中的频数写入value2数组中
//进行相似度计算求解
//第一步进行第一个公式计算
//第二步进行第二个公式计算
//给出结论
return 0;
}
四、程序分析
算法分析:
(1)程序算法的特性分析
本程序满足算法的基本特性要求,具备有穷性、确定性、可行性且输入输出合理。
(2)程序算法的设计要求分析
本程序满足程序算法的设计要求,具备正确性、可读性、健壮性和效率与低存储量需求。
(3)程序算法的时间复杂度分析。
Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的,假设字符的种数有m个,有若干个长度为n的字符串构成了一个Trie树,则每个节点的出度为m(即每个节点的可能子节点数量为m),Trie树的高度为n。很明显我们浪费了大量的空间来存储字符,此时Trie树的最坏空间复杂度为O(m^n)。也正由于每个节点的出度为m,所以我们能够沿着树的一个个分支高效的向下逐个字符的查询,而不是遍历所有的字符串来查询,此时Trie树的最坏时间复杂度为O(n)。这正是空间换时间的体现,也是利用公共前缀降低查询时间开销的体现。由于本程序中一共有C语言关键字32个,每个关键字长度不超过10,所以本程序中每次查询Trie树的时间复杂度最坏不超10,平均查找长度为5*26=130。
Hash表的时间复杂度较小可以达到常数级,在本程序中哈希表的装填因子为α,≈0.744,平均查找长度ASL≈1.84。查找速度较快,时间复杂度较低。
(4)程序算法的空间复杂度分析
本程序的算法中,通常来说Trie树的空间的复杂度较高,但是本程序为分支结点仅开辟一个标志字符的空间,利用指针指向字符串所在实际空间,所以本程序中的Trie树空间复杂度较为理想,而Hash表中开辟了等于表长个数的结点,即为43个结点空间,所以哈希表中的空间复杂度较Trie树大一些,但哈希表的查找时间效率更高。
改进设想:
本程序虽然能够准确统计两个C语言源程序的关键字出现频数,并根据公式计算得出对两个C语言程序相似度的判断,但是仍然存在着较大的改进空间。
(1)对于Trie树结构的改进设想:Trie树本身的结构就是一个较为理想的字典查询结构,但是由于分支结点的设置会造成较多的未利用空间,而之前在一片博客了解到了DAT(Double-Array Tire)双数组Trie树的存在,在DAT中用的就是双数组:base数组和check数组。双数组的分工是:base负责记录状态,用于状态转移;check负责检查各个字符串是否是从同一个状态转移而来,当check[i]为负值时,表示此状态为字符串的结束。这种结构能够较为有效的解决Trie树浪费空间的问题。
(2)对于哈希表结构的改进设想:当关键字的集合是一个不变的静态集合时,哈希技术还可以用来获取出色的最坏情况性能。如果某一种哈希技术在进行查找时,其最坏情况的内存访问次数为 O(1) 时,则称其为完美哈希(Perfect Hashing)。设计完美哈希的基本思想是利用两级的哈希策略,而每一级上都使用全域哈希。完美哈希的主要思想是提供一种避免哈希冲突的解决思路与方法。
(3)对于本程序中的主体程序函数以及算法思想的改进设想:本程序能够较为准确高效的完成对两个C语言程序代码相似性进行判断的任务,但仍然存在一定改进空间,我对本程序的主体程序提出了一下三点改进设想:
① 在解决进行两次源程序文件查询统计产生的冲突时,如果能够设计更理想的查询统计函数,即能够将文件名作为参数传递给求解函数能够大大减少代码的数。
② 而且如果能够舍去value1.txt文件的使用,直接将频数数据分别传入到value1和value2数组中,会省去写入与读取文件的函数操作,会使程序更为简洁。
③ 如果能够将对于相似性判断的S、D值求解过程重新设计外部函数,通过调用实现计算并给出合理结论,能够减轻主程序的代码量负担。使程序更为美观。
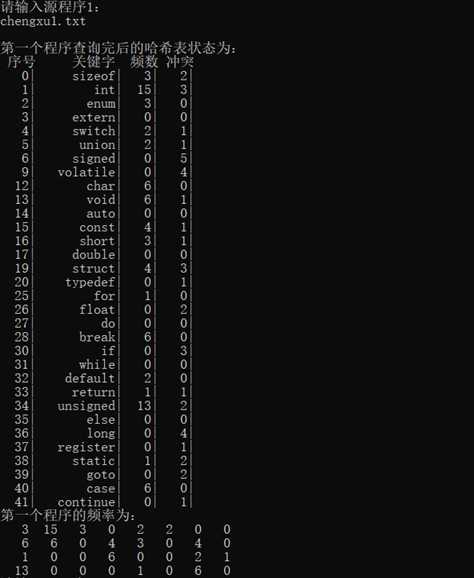
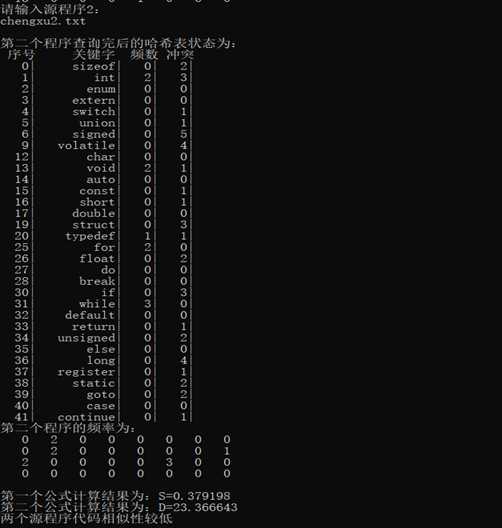
五、程序截图
以上是关于程序相似性判断的主要内容,如果未能解决你的问题,请参考以下文章