爬虫之selenium模块
Posted peng104
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫之selenium模块相关的知识,希望对你有一定的参考价值。
引入
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行javascript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
from selenium import webdriver browser=webdriver.Chrome() browser=webdriver.Firefox() browser=webdriver.PhantomJS() browser=webdriver.Safari() browser=webdriver.Edge()
官网:http://selenium-python.readthedocs.io
安装
安装selenium:pip install selenium
下载驱动浏览器驱动:
有界面浏览器:Chrome ,Firefox(geckodriver)
无界面浏览器:PhantomJS
验证:
from selenium import webdriver driver=webdriver.Chrome() # 弹出谷歌浏览器 driver.get(‘https://www.baidu.com‘) driver.page_source
基本使用
from selenium import webdriver from selenium.webdriver.common.by import By #按照什么方式查找 ID/CSS from selenium.webdriver.common.keys import Keys #键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 import time browser=webdriver.Chrome() try: browser.get(‘https://www.jd.com‘) input_tag=browser.find_element_by_id(‘key‘) input_tag.send_keys(‘电脑‘) input_tag.send_keys(Keys.ENTER) wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,‘J_goodsList‘))) #等到id为J_goodsList的元素加载完毕,最多等10秒 # time.sleep(3) finally: browser.close()
元素定位
寻找元素主要有两种:
find_element_ # 只匹配一个元素 find_elements_ # 匹配所有元素的列表
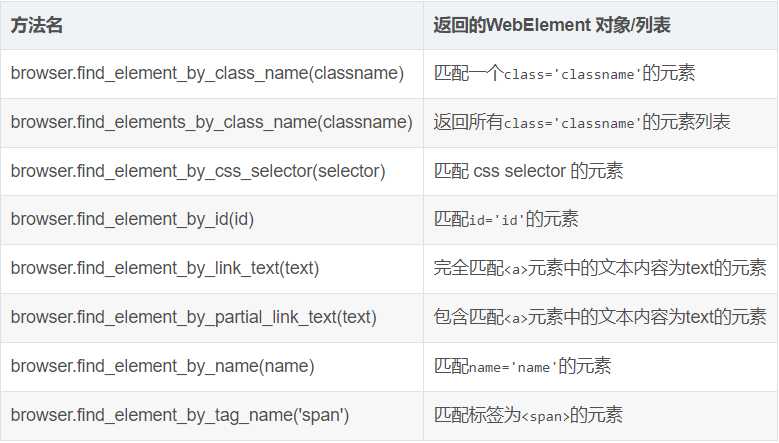
如果没有匹配到元素,selenium模块会抛出NoSuchElement异常
获取到了WebElement对象,则可以获取对象的属性
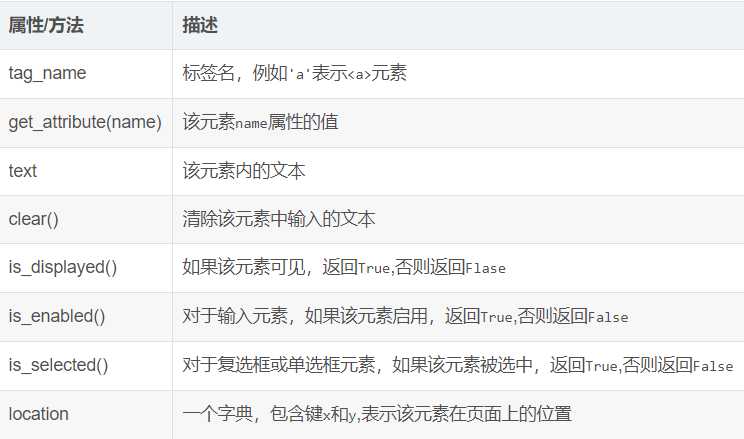
延时等待
selenium只是模拟浏览器的行为,而浏览器解析页面是需要时间的(执行css,js),一些元素可能需要过一段时间才能加载出来,为了保证能查找到元素,必须等待
等待的方式分两种:
隐式等待:在browser.get(‘xxx‘)前就设置,针对所有元素有效


from selenium import webdriver from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys #键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() #隐式等待:在查找所有元素时,如果尚未被加载,则等10秒 browser.implicitly_wait(10) browser.get(‘https://www.baidu.com‘) input_tag=browser.find_element_by_id(‘kw‘) input_tag.send_keys(‘美女‘) input_tag.send_keys(Keys.ENTER) contents=browser.find_element_by_id(‘content_left‘) #没有等待环节而直接查找,找不到则会报错 print(contents) browser.close()
显式等待:在browser.get(‘xxx‘)之后设置,只针对某个元素有效
from selenium import webdriver from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.common.keys import Keys #键盘按键操作 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() browser.get(‘https://www.baidu.com‘) input_tag=browser.find_element_by_id(‘kw‘) input_tag.send_keys(‘美女‘) input_tag.send_keys(Keys.ENTER) # 显式等待:显式地等待某个元素被加载 wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,‘content_left‘))) contents=browser.find_element(By.CSS_SELECTOR,‘#content_left‘) print(contents) browser.close()
元素交互操作
from selenium import webdriver import time browser = webdriver.Chrome() browser.get(‘https://www.taobao.com‘) input = browser.find_element_by_id(‘q‘) input.send_keys(‘诺基亚‘) time.sleep(1) input.clear() input.send_keys(‘IPhone‘) button = browser.find_element_by_class_name(‘btn-search‘) time.sleep(2) button.click()
from selenium import webdriver from selenium.webdriver import ActionChains import time browser = webdriver.Chrome() url = ‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘ browser.get(url) browser.switch_to.frame(‘iframeResult‘) source = browser.find_element_by_css_selector(‘#draggable‘) target = browser.find_element_by_css_selector(‘#droppable‘) actions = ActionChains(browser) # actions.drag_and_drop(source, target) actions.click_and_hold(source).perform() time.sleep(1) actions.move_to_element(target).perform() time.sleep(1) actions.move_by_offset(xoffset=50,yoffset=0).perform() actions.release()
from selenium import webdriver browser = webdriver.Chrome() browser.get(‘https://www.jd.com/‘) browser.execute_script(‘window.scrollTo(0, document.body.scrollHeight)‘) browser.execute_script(‘alert("123")‘)
from selenium import webdriver from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() browser.get(‘https://www.amazon.cn/‘) wait=WebDriverWait(browser,10) wait.until(EC.presence_of_element_located((By.ID,‘cc-lm-tcgShowImgContainer‘))) tag=browser.find_element(By.CSS_SELECTOR,‘#cc-lm-tcgShowImgContainer img‘) #获取标签属性, print(tag.get_attribute(‘src‘)) #获取标签ID,位置,名称,大小(了解) print(tag.id) print(tag.location) print(tag.tag_name) print(tag.size) browser.close()
其他操作
import time from selenium import webdriver browser=webdriver.Chrome() browser.get(‘https://www.baidu.com‘) browser.get(‘https://www.taobao.com‘) browser.get(‘http://www.peng104.xyz‘) browser.back() time.sleep(10) browser.forward() browser.close()
from selenium import webdriver browser=webdriver.Chrome() browser.get(‘https://www.zhihu.com/explore‘) print(browser.get_cookies()) browser.add_cookie({‘k1‘:‘xxx‘,‘k2‘:‘yyy‘}) print(browser.get_cookies()) # browser.delete_all_cookies()
import time from selenium import webdriver browser=webdriver.Chrome() browser.get(‘https://www.baidu.com‘) browser.execute_script(‘window.open()‘) print(browser.window_handles) #获取所有的选项卡 browser.switch_to_window(browser.window_handles[1]) browser.get(‘https://www.taobao.com‘) time.sleep(10) browser.switch_to_window(browser.window_handles[0]) browser.get(‘http://www.peng104.xyz‘) browser.close()
from selenium import webdriver from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException try: browser=webdriver.Chrome() browser.get(‘http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘) browser.switch_to.frame(‘iframssseResult‘) except TimeoutException as e: print(e) except NoSuchFrameException as e: print(e) finally: browser.close()
来个小栗子
from selenium import webdriver # 初始化driver driver = webdriver.Chrome() # 打开知乎登录页面 driver.get(‘https://www.zhihu.com/signup‘) # 默认是注册界面,这里需要先找到切换登录的按钮 signup_switch_bt = driver.find_element_by_xpath(‘//*[@id="root"]/div/main/div/div/div/div[2]/div[2]/span‘) # 如果内容显示登录,则证明在注册页面,需要点击一下切换到登录页面 if signup_switch_bt.text == ‘登录‘: signup_switch_bt.click() # 找到填写用户名的输入框 uname_textfield = driver.find_element_by_xpath( ‘//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/div[1]/div[2]/div[1]/input‘) # 找到填写密码的输入框 pwd_textfield = driver.find_element_by_xpath( ‘//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/div[2]/div/div[1]/input‘) # 找到登录按钮 signup_bt = driver.find_element_by_xpath(‘//*[@id="root"]/div/main/div/div/div/div[2]/div[1]/form/button‘) # 填写用户名,需要替换为你的用户名 uname_textfield.send_keys(‘user_name‘) # 填写密码,需要替换为你的密码 pwd_textfield.send_keys(‘your_password‘) # 点击登录 signup_bt.click()
以上是关于爬虫之selenium模块的主要内容,如果未能解决你的问题,请参考以下文章