node爬虫(简版)
Posted yishifuping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了node爬虫(简版)相关的知识,希望对你有一定的参考价值。
做node爬虫,首先像如何的去做这个爬虫,首先先想下思路,我这里要爬取一个页面的数据,要调取网页的数据,转换成页面格式(html+div)格式,然后提取里面独特的属性值,再把你提取的值,传送给你的页面上,在你前端页面显示,或者让你的前端页面能够去调取这些返回的值。
首先要安装以下的依赖
// 调取 npm install --save request-promise // 转换成页面格式 npm install --save cheerio // 打开node使用 npm install --save express // 安装依赖 npm install --save request
然后在代码中去使用依赖东西,来转换页面格式调取页面值
// 把网址转换成页面格式
let result = await request(URI)
$ = cheerio.load(result)
// 获取表头文本
let name = $(‘#activity-name‘).text()
name = name.replace(/ +/g,"")
name = name.replace(/[
]/g,"");
name = `<h1>${name}</h1>`
// 获取内容文本
let test = $(‘#js_content‘).text()
test = test.replace(/[
]/g,"");
test = `<p>${test}</p>`
在页面中获取页面值上面的代码是没有问题的,重点事爬取图片
在普通的浏览器页面上爬取图片的时候,直接获取他的src就可以,但是有些很是特殊的,下面的代码爬取普通的浏览器图片
// 获取图片
let add = $(‘p img‘)
let att =[]
for ( let i=0;i<add.length;i++){
let imgPath = add.eq(i).attr("src")
att.push(imgPath)
}
在页面上显示(访问自己定的接口)
app.listen(3000, () => {//启动一个3000端口的server服务
console.log(‘Listening on port 3000‘)
})
打开localhost:3000查看效果

样式我这里没有调,只加了两个语义化标签。给上段完整代码吧
const request = require(‘request-promise‘)
const cheerio = require(‘cheerio‘)
let express = require(‘express‘)
let app = express()
const URI = ‘https://mp.weixin.qq.com/s/MWvlJHu7ptHQMLBpA0u9oA‘
app.get(‘/‘, async (req, res) => {
// 把网址转换成页面格式
let result = await request(URI)
$ = cheerio.load(result)
// 获取表头文本
let name = $(‘#activity-name‘).text()
name = name.replace(/ +/g,"")
name = name.replace(/[
]/g,"");
name = `<h1>${name}</h1>`
// 获取内容文本
let test = $(‘#js_content‘).text()
test = test.replace(/[
]/g,"");
test = `<p>${test}</p>`
// 获取图片
let add = $(‘p img‘)
let att =[]
for ( let i=0;i<add.length;i++){
let imgPath = add.eq(i).attr("data-src")
imgPath = imgPath.split(‘?‘)[0]
att.push(imgPath)
}
let img =att.map(el => {
let a = `<img src=‘${el}‘>`
console.log(a)
return a
})
// let data = []
// data.push(name,test,att)
let data = ‘‘
data = name + test + img
res.send(data)
})
app.listen(3000, () => {//启动一个3000端口的server服务
console.log(‘Listening on port 3000‘)
})
接下来说下获取图片的特殊情况,那就是获取微信公众号文章图片的时候
当你把微信公众号地址转换成代码的时候,他图片转化出来的是一个方法,导致你把页面加载完了,但是图片没有加载出来。(根本就没有src)
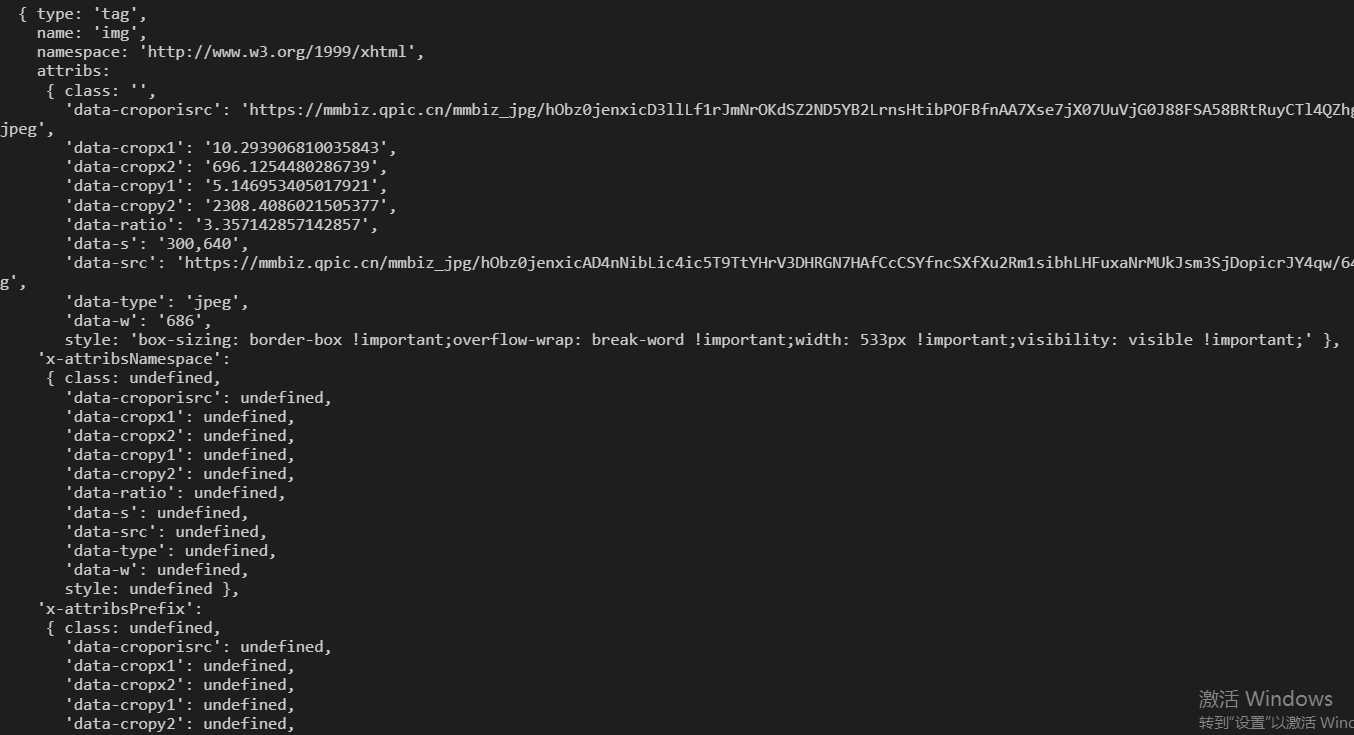
我们应该获取的事这个img的src但是他调取页面转换成代码的时候,这个加载图片的事件没有走完,导致src事underfunded

有谁能解决这个问题吗?帮忙解答一下,困扰我好长时间了!!!!
以上是关于node爬虫(简版)的主要内容,如果未能解决你的问题,请参考以下文章