prometheus杂碎
Posted hopegi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了prometheus杂碎相关的知识,希望对你有一定的参考价值。
一个监控及告警的系统,内含一个TSDB(时序数据库)。在我而言是一个数采程序
重要成员分三块
- exploter:实际是外部接口,让各个程序实现这个接口,供普罗米修斯定时从此接口中取数
- alert:告警模块
- prometheus:实际上是数采模块+存储模块,但是它的存储不是持久化的
普罗米修斯的数据是一个值时间序列,例如
website_request_count{method="GET",path="/home/index",query="id=2"} 0.001
website_request_count是一个监控指标,花括号中的每个值是label标签,最后的是这次监控的值,还有一个未出现的量就是时间戳。
与熟悉的数据库相比起来,一个监控指标好比一个表,时间戳,值,与每个lebel的名称就是列。每一组label组成一个序列。一旦某个label不一致(包含label的数量,label的名称和值)都会被视为不同的序列
普罗米修斯的数据类型分四种
- count:计数器类型,只增不减
- gauge:仪表盘类型,数值可增可减
- Hisgram:直方图类型,按照一定区间给各个段分组统计值,每个段为一个bucket
- summary:摘要类型,按分位数统计各个分组结果
Hisgram与summary比较相似,应用场景也类似:主要源于数据分布不均的情况下(极值delta较大或出现利群值时),平均数已经无法准确反映数据的整体情况,故需要对数据进行分组,按各个分组的统计值反应数据的整体情况。其中Hisgram是按照一定的区间来给数据分段,默认范围是{.005, .01, .025, .05, .075, .1, .25, .5, .75, 1, 2.5, 5, 7.5, 10},它只能给数据分段,并不能得出这部分数据的中位数,4分位数等,若需要则要在服务端处理,而summary则可以在客户端已得出值。两种数据类型都带有_sum与_count两个指标。
从刮擦数据的结果中可以得出此数据的数据类型
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
每一组指标顶端都有两行注释,第一行是对于这个指标的描述,第二行则是指明了这个指标的数据类型
普罗米修斯的查询中输入监控指标则可以两种形式(图表和数据)展示结果,该结果会包含所有序列的值(即出现过的label和值的集合)
如果要对某些label进行筛选,则可以下面形式
up{instance="helloworld"}
此时会查出所有instance为helloworld的序列
Prometheus既然包含了一个TSDB,对这部分数据则提供了一个查询语言叫ProuQL,下面则简单提一些内置函数
sum,avg,按某个指标进行求和运算,如sum(up),avg(up);
有时候会出现类似这样的写法 sum by(job) (up)或者sum with out(job) (up) 这样的写法,与实际上都是类似于SQL的grouop by,by则针对job 这个label的值分组统计up的值,而with out则除了job lebel外所有label都拿来作分组条件。
up[5m]写法 方括号中代表5分钟,可以是1分钟1m或者1小时1h。此写法会得出一个向量集合,所谓向量实际是一个结果中带了两个值,本身指标的值和时间戳,中间以@作为分隔,这样的写法通常结合rate,irate和delta函数。
rate(up[5m]),求up指标5m钟内每两个量变化率的平均值,是一个平均变化率,假设一组数,[email protected],[email protected],[email protected],……[email protected]
rate=( ∑ (a2-a1)/(t2-t1)+(a3-a2)/(t3-t2))/n
irate(up[5m])则是求5m这批数据中,相邻最近的两个值之间的变化率,是一个瞬时变化率
delta(up[5m])则是求这5m这批数据中,收尾两个值的相差值
up{job=~"^123$"}此处job表示是按照正则匹配(出现了“=~”),而后面则跟着对应的正则表达式,^和$仅仅是正则中的开始与结束符号而已。
prometheus的配置采用yaml
scrape_config主要是配置各个刮擦任务,每个刮擦任务为一个job,每个job的可以有独立的刮擦周期,并有不同的刮擦类型,可以有普通的static_configs,还有其他针对不同exporter的配置,如azure_sd_config,kubernetes_sd_config等,此处要提的是relable这个配置项,relable的配置项的内容可以影响着跨擦结果,里面的label不属于刮擦数据的内容,但是它有可能会被增加到刮擦的结果中而存到库里面去。
每个relable配置项有以下几个属性
action:代表relable的行为,包含
replace:如果值匹配了regex,则把source_labels替换,替换的label值看replacement而定,替换的label名按target_label而定;
keep:如果label名匹配了 regex的,此条数据才保留
drop:如果label名匹配了regex的,此条数据则被舍弃掉,与上面的相反
hashmad:作用未明
labelmap:一般结果需要多个label经过正则运算后拼凑组合生成新的值的会用这种,label值结果会按replacement生成;
labeldrop:与drop类似,但它舍弃的只是label而已且是拿label值与regex匹配;
labelkeep:与labeldrop相反
regex:正则表达式,默认值是(.*);
source_labels:一个数组,用于处理的各个原始label;
spearetor:默认值是 ";"
target_label:处理后新的label名
replacement:默认值是$1,replace和labelmap按这个来生成结果,后面是数字表明第几个与regex匹配的结果
接下来谈的是prometheus的服务发现,在prometheus界面中有Target与Service Discovery两个菜单,这两个菜单内容与服务发现极有关系。回顾上述关于scrape的配置内容,我们配置的只有static_config,此处一般设置一个target则往一个节点处刮擦数据。由于他是静态,而对于动态的则是基于服务发现的,凡是刮擦类型中带sd的(service-discover)均有服务发现的功能,该job中的所有节点都无需通过手动配置而加入被刮擦的集合中,如kubernetes_sd_config,按照官网介绍,根据role属性的不同设置而对k8s的不同对象进行scrape,如设成service,则scrape回来的数据包含这些label:
__meta_kubernetes_namespace
__meta_kubernetes_service_name
__meta_kubernetes_service_label_
__meta_kubernetes_service_annotation_
__meta_kubernetes_service_port_name
__meta_kubernetes_service_port_protocol
__meta_kubernetes_service_port_number
通过service discover界面看出果真存在若干个被发现的服务(一行代表一个服务),
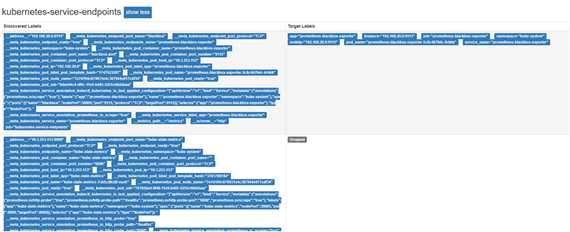
还记得relabel中的drop action,这里一个发现了7个服务,但是被drop掉的有6个,最终被保存下来的服务的数据仅有一个序列,这个在Taget页面中得到展示,Target就是展示被筛选过后剩余的需要真正监控的服务。
以上是关于prometheus杂碎的主要内容,如果未能解决你的问题,请参考以下文章