证明与计算: 从加密哈希函数到一致性哈希
Posted math
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了证明与计算: 从加密哈希函数到一致性哈希相关的知识,希望对你有一定的参考价值。
目录:
** 0x01 [哈希函数] vs [加密哈希函数]
** 0x02 [哈希碰撞] vs [生日问题]
** 0x03 [哈希表] vs [分布式哈希表]
** 0x04 [欧式距离] vs [三角不等式]
** 0x05 [异或距离] vs [前缀路由表]
0x01 [哈希函数] vs [加密哈希函数]
在哈希表计算索引的时候,我们需要一个哈希函数,通过hash(key)来计算key在哈希表里的index。这个地方的哈希函数只要尽量满足均匀分布,周期尽量大,计算速度又足够快等即可。而在密码学里用的比较多的,则是加密哈希函数。[加密哈希函数],它需要尽量满足三个安全性质:
- 原像防御(Pre-Image resistance):就是任意给一个hash值h,你很难破解出它的原像m,使得hash(m)=h,这个难度一般是NP难度的,也就是所谓的单向函数。
- 弱碰撞防御(Second pre-image resistance):就是给定一个m1,你很难找到另一个m2,使得h(m1)=h(m2)。
- 强碰撞防御(Collision resistance):就是你很难找到两个不同的m1和m2,使得h(m1)=h(m2)。
如果符合强碰撞防御,也就是会符合弱碰撞防御,但是不一定符合原像防御。如果只满足前2个,在密码学上是不安全的,一般加密哈希函数应该满足1,2,3。
常见的密码哈希函数有:
SHA1, SHA2(SHA-256,SHA-512), SHA3(SHA3-256, SHA3-512, Keccak-256, Keccak-512)MD5- RIPEMD-160
其中,SHA-1因为已经在2005年可以被暴力找出碰撞,就不满足性质3,从而已经不再推荐使用了,现在常用的SHA-256,SHA-512都是属于SHA-2这个大类的,最新的则是SHA-3系列。MD5也已经在2004年就不满足强碰撞防御了,也不推荐作为密码哈希函数来用了。
加密哈希函数的使用场景,典型的有在SSL(Secure Sockets Layer)和数字签名(Digital Signature)上使用。
[1] Cryptographic hash function
[2] SHA-1
[3] SHA-2
[4] SHA-3
[5] MD5
[6] RIPEMD
0x02 [哈希碰撞] vs [生日问题]
一个哈希函数的取值空间是有限的,那么所有可能的结果个数是固定的,假设为D。那么,如果你能计算D+1次,自然一定有两个值发生碰撞。好在一般情况下,D都是很大的,有限算力的计算机在有生之年是没希望通过这个方式直接暴力计算出碰撞值。但是,如果我们退而求其次,只关心能否有50%的概率暴力计算出碰撞值呢?那么,你需要计算多少次后,才会有50%的概率发生碰撞?
这个问题,实际上叫做“生日问题”。在一个班级里有n个同学,每个同学的生日都只能是D=365天中的一天,那么班级里有两个人生日相同的概率P是多少呢?我们可以很容易计算出班级里所有人概率都不相同的概率P‘。计算方法是,依次计算第i个同学与前面(i-1)个同学生日都不相同的概率。那么:
- 第1个人与第0个人生日不相同的概率是1。
- 第2个人与第1个人生日不相同的概率是 364/365。
- 同理,第3个人与第2个人生日不相同的概率是363/365。
- ...
- 第n个人与前面n-1个人生日不相同的概率是(365-n+1)/365
从而,P‘=1x{364/365}x{363/365}x...x {(365-n+1)/365},做一个简单变换后得到:
P‘= 1x{1-1/365}x{1-2/365}x...x {1-(n-1)/365}
这样,至少有2个人生日相同的概率P = 1-P‘。推广一下,把365替换为D,则有:
P‘= 1x{1-1/D}x{1-2/D}x...x {1- (n-1)/D }
对于哈希函数来说,一般D都是很大的,例如SHA-256,可能的D的取值有2^256个,那么这个时候1/D就很小,我们可以利用e^x的泰勒公式的性质来规约P‘。具体做法是:
- 做泰勒展开,e^x = 1+x+x^2/2+x^3/6+x^4/24+....
- 因此,当x很小的时候,e^x就可以直接用1+x来近似计算。
- 则,如果x=-i/D,由于D很大,-i/D就很小,从而可以直接用 e^{-i/D}=1-i/D 替换。
那么,就得到了如下的公式:
P‘= 1 x e^{-1/D} x e^{-2/D} ... x e^{-(n-1)/D}
= e^{-(1+2+...+n-1)/D}
= e^{ - n x (n-1)/2D }
进一步近似,用n^2代替 n x (n-1) 则有
- P‘= e^{- n^2/2D }
- P = 1-P‘ = 1-e^{-n^2/2D}
再次利用当x很小时 e^x=1+x 的近似公式,就得到最后的近似值:
P = 1-e^{-n^2/2D} = 1 - (1-n^2/2D) = n^2/2D
有了这个公式,如果反算:“班级有多少人时,至少有两个人生日相同的概率是50%”,或者“哈希函数计算多少次后,有两个值碰撞的概率是50%”,我们只需要反求n即可:
n = sqrt(2D x P),把P=0.5带入,得 n = sqrt(D).
[1] Birthday problem
[2] 生日问题
[3] Birthday attack
[4] 生日攻击
[5] Collision attack
0x03 [哈希表] vs [分布式哈希表]
回头说两个跟哈希相关的数据结构。哈希表(Hash table)也称散列表,通过哈希函数把key映射到哈希表里的桶(bucket)的地址。由于哈希表的长度有限,通常哈希函数不可避免会发生碰撞,根据碰撞时的处理方式不同,哈希表分为两种:
- 开链法(Seperate Chaining)处理哈希碰撞。简单说把所有key碰撞的,用一个链表串起来,当然你也可以用二叉树串起来以进一步改进查询速度。
- 开放定址法(Open addressing, 又叫闭散列法,Closed hashing)。简单说遇到冲突时,直接通过规则在哈希表里找一个其他桶来用,例如使用线性探测法确定新位置:index=Hash(key)+ i
对于开链法哈希表,需要哈希函数满足均匀分布,也就是哈希函数会尽量把key均匀地映射到哈希桶上。而对于开放定址法,哈希函数还要尽量减少聚集(cluster)效应导致局部哈希桶太密集,因为这会导致插入和搜索到时间变大。
相对于只考虑单机程序的哈希表,分布式哈希表(Distrubuted hash table, DHT)则构建在P2P网络上。分布式哈希表由P2P网络的节点组成,每个节点都会维护好Key被映射到的节点信息,从而实现在P2P网络里对Key-Value进行添加、查找、删除的能力。一个好的DHT需要满足下面三个性质:
- 自治和去中心化(Autonomy and Decentralization)。节点之间的相互发现、加入、离开都不依赖于中心节点。
- 错误容忍性(Fault tolerance)。几点可以自由加入、离开、移除,而整个系统依然可用。
- 伸缩性(Scalability)。系统的效率不因节点的增加而减低,即使增加成千上万节点也是一样。
DHT的结构是怎样的呢?
首先从DHT的两个基本概念入手,是最佳的方式:
- keyspace。例如要存储一个资源,资源的名字通过SHA-160做1次哈希,得到160-bit的key,所有这样的key构成了keyspace。
- Overlay network。简单说就是一个P2P网络,但是这些P2P网络里的节点ID需要经过设计。
在理解DHT和通常的P2P网络有什么区别之前,先看下在DHT网络上会核心做的两个操作:
- put(key,value)。动态查找到应该持有该key的Node,通过P2P网络把该key-value写入到那个Node。
- get(key)。动态查找到应该持有该key到Node,通过P2P网络把那个key-value读出来。
上面,核心的两个动作是:
- 计算应该持有该key的Node
- 动态查找该Node
计算应该持有该key的Node有好多种算法,其中常见的一种做法就是使用一致性哈希。一致性哈希的核心做法是:
- 让Node的ID,和KeySpace中的Key,采用一致的格式和长度。
- 找到一种合适的距离计算函数D(distance)。
- 距离函数可以计算两个key之间的距离:D(key1,key2)。
- 距离函数也可以计算一个key和一个Node的ID之间的距离:D(key,ID)。
- 这种距离计算函数跟节点之间的物理距离没有关系。
- 根据距离,所有的key和所有ID之间就有一个排序关系: ...,ID(i),keyi1,...,keyim,ID(i+1)
- 所有排序在ID(i)和ID(i+1)之间的key,都归属于ID(i+1)。
而动态查找Node实际上就是一个贪心算法:
- 每个Node有一个路由表,路由表里包含了离自己从近到远的节点列表。
- 在路由表里查找key所在Node,
- 如果从路由表里直接到key所在的Node,就通过P2P网络与之通信。
- 否则从路由表里找到离key最近的Node,转发给那个离key最近的Node去查找。
具体关于如何“计算距离”,以及如何“设计路由表”,在Kademlia网络里有更具体的做法,下一次可以单独来讲。
[1] Hash table
[2] 哈希表
[2] Consistent hashing
[3] 一致性哈希
[4] Distributed hash table(DHT)
[5] Kademlia
[6] Overlay network
0x04 [欧式距离] vs [三角不等式]
理解分布式哈希表,首先需要理解分布式哈希表里是如何计算
- 两个Key之间的距离
- Key和Node之间的距离
在介绍DHT里的距离之前,我们先看看欧几里得空间中的点是如何计算距离的。
在三维空间中,计算两个点之间的距离,叫做欧几里得距离。给定P1(x1,y1),P2(x2,y2),那么P1,P2之间的距离是sqrt(|x1-x2|^2+|y1-y2|^2)。对坐标差绝对值求平方和再开方,这个叫做2-范数距离。
有2-范数距离,当然也就有1-范数距离,公式是|x1-x2|+|y1-y2|。实际上1-范数距离也叫做“曼哈顿距离(Manhattan distance)”或者“出租车距离(Taxicab distance)”,简单说一辆出租车在曼哈顿里从一个点到另一个点,需要一直绕着格子建筑物走格子才能到达另一个点。
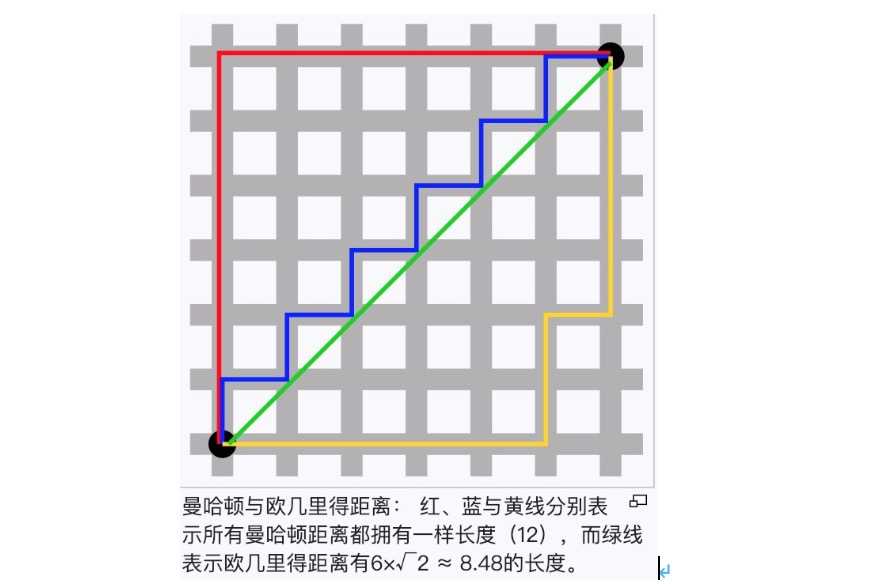
更一般的p-范数距离,对坐标差绝对值,先求p次方,再开p次方。也就是(|x1-x2|^p+|y1-y2|^p)^{1/p}。如果p趋向于无穷大,求极限就是无穷范数距离,也叫车比雪夫距离,国际象棋上王从一个位置要走到另一个位置所需要的步数就是车比雪夫距离。

进一步如果把P放在N维空间中,也可以用同样的方式求这些N维欧几里得空间中点的p-范数距离,此时它们统一被叫做明可夫斯基距离(Minkowski)。
有这么多种不同的距离,那么是不是两个点之间的任何函数都可以做为这两个点之间的一种“合法”的距离呢?显然不是,一个函数D要能做为欧式空间中两个点之间的距离,必须满足下面三个性质。
- 正性:D(P1,P2)>= 0,当且仅当P1=P2时才为0,重合的点距离为0,其他为正。
- 对称性:D(P1,P2) = D(P2,P1),距离和方向没有关系。
- 三角不等式:D(P1,P3) <= D(P1,P2) + D(P2,P3),两点之间直线最短。
其中最突出的是三角不等式。实际上p-范数距离里面,p不一定要求是整数,但是如果p<1,会导致三角不等式不成立,因此p-范数要求p>=1。
有了距离,我们关心的是,可以得到下面3个DHT需要的功能:
- 计算P与P1,P2,P3,...之间的距离
- 根据距离远近,判定P在哪个区间,例如P在P_i, P_{i+1}之间
- 那么,我们可以让P归P_{i+1}管理。
但是DHT并不是直接使用p-范数距离,而是巧妙使用了异或(XOR)这个位操作的能力。待续。
[1] distance
[2] Minkowski distance
[3] Manhattan distance
[4] 曼哈顿距离
[5] Chebyshev distance
[6] 车比雪夫距离
0x05 [异或距离] vs [前缀路由表]
编程中,在位上的操作实际上并不难理解。常见的位操作包括与(AND)、或(OR)、非(NOT)、异或(XOR),位移等。其中XOR的使用相对较少一些,但是如果理解了XOR的语义之后,就会发现XOR在操作数据方面有很大用途。
我们将一个黑白棋子保持原状看做0,将一个棋子翻转到另一面看做1,给你两次机会选择翻转或者不翻转。那么有下面几种组合:
- 不翻转,不翻转,结果等于不翻转。
- 不翻转,翻转,结果等于翻转。
- 翻转,不翻转,结果等于翻转。
- 翻转,翻转,结果等于不翻转(翻了两次,等于没翻转)。
把不翻转记为0,翻转记为1,这就是0和1的“异或”运算:
0 ⊕ 0 = 0, 0 ⊕ 1 = 1, 1 ⊕ 0 = 1, 1 ⊕ 1 = 0.
异或(XOR)在对称密码学中起着“基本操作”的作用。例如,假设明文是a,密钥是b,那么最简单的加密和解密操作分别是:
- 加密:c = a xor b,相当于对a的每个bit,用b对应的bit去做了一次翻转操作。
- 解密:a = c xor b = a xor b xor b,相当于对a的每个bit,用b对应的bit去做一次翻转,再用b的每个bit去做一次翻转,根据上面的翻转规则,两次翻转等于没有翻转,所以结果等于a。
理解到翻转这个意思后,就可以活学活用了。例如,考虑一个趣题:“如何不使用临时变量交换两个变量a和b?” 这个题目有不只一种做法,先看一个只用加减法的做法:
- a = a - b
- b = a + b
- a = b - a
现在,我们决定用“加解密”的方式来解决这个问题:
- a = a xor b,可以看作是:“使用b对a加密”或“使用a对b加密”,此时a等于密文
- b = a xor b,使用原始的b对密文解密,得到原始的a
- a = a xor b,此时b等于原来的a,则a xor b等于使用原始的a对密文解密,得到原始的b
通过上述的几个小步骤,我们对xor的妙用有了一定的理解。回过头来,我们看下异或距离(XOR distance)这个概念。简单说,两个长度相同的二进制数据之间的异或操作,可以构成一个距离函数。也就是异或操作满足距离函数的三个重要性质:
- 正性:a xor b >= 0,当且仅当a=b时取0。很好理解,
a xor a,每个bit上的值都相等,“翻转+翻转”或者“不翻转+不翻转”结果都等于0. - 对称性:a xor b = b xor a。
- 三角不等式:a xor c <= a xor b + b xor c
有了异或距离,就可以解决P2P网络上如何把数据项(Key)存放到哪些节点(Node)的问题。一个简化的做法如下:
- 节点的ID,和数据的键Key,使用同样的格式和长度。
- 每个节点持有由远到近的一系列其他节点ID列表。
- 从其他节点列表里查找与Key最近的一些节点,计算当前最近距离min-d,把<key,min-d,sessionid>发送给距离最近的节点。
- 那些距离最近的节点收到后,在自己的节点列表里再次查找,如果不能找到比min-d更近的节点,就算查找成功。
- 读或者写入数据。sessioid用来做去重等。
Node和Key构成的一致性哈希结构如图所示:
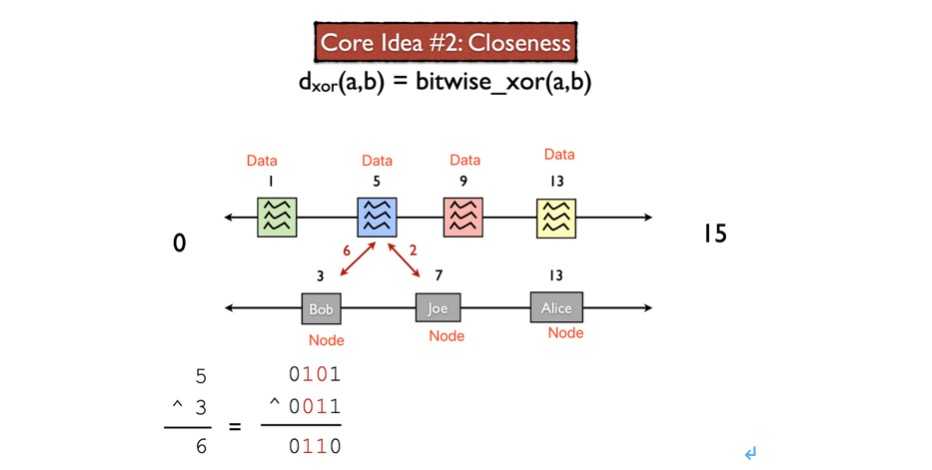
其中,比较关键的是“每个节点持有由远到近的一系列其他节点ID列表” 这个过程是如何做的。通过举例的方式,先假设节点ID如下:
- 假设Node的ID是3-bit的。
- 所有可能的节点ID有8个:000,001,010,011,100,101,110,111
- 假设011不是一个节点,剩下7个节点:000,001,010,100,101,110,111
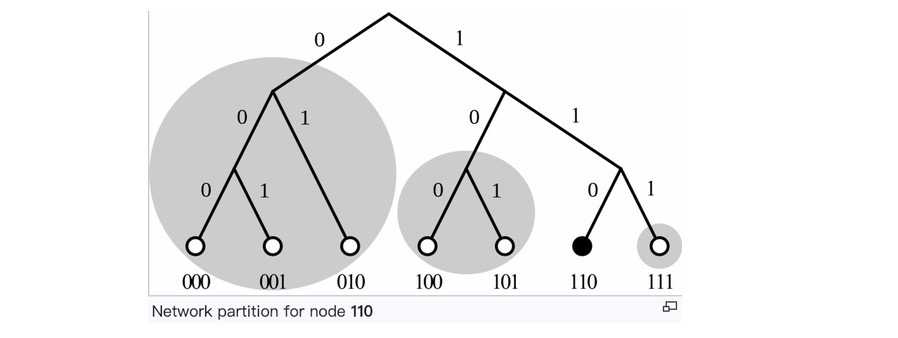
现在第6个节点是110,标记为Node(6),,我们观察110节点上是如何由近到远持有其他节点ID。
- 分配3个节点列表list1,list2,list3,之所以是3个是因为节点ID长度是3.
- 每个列表最多存3个ID。
- 第i个列表里的每个ID第i个比特和Node(6)的第i个比特必须不同。
- 第i个列表里的每个ID前i-1个比特和Node(6)的前i-1个比特必须相同。
根据规则3和规则4,Node(6)持有的三个list分别是:
- list1: [000, 001, 010]。可以看到第1个比特都是0,和110的第1个比特不同。
- list2: [100, 101]。可以看到第2个比特都是0,和110的第2个比特不同;同时,第1个比特都是1,和110的第1个比特相同。
- list3: [111]。可以看到第3个比特是1,和110的第3个比特不同;同时前2个比特都是11,和110的前2个比特相同。
这三个list如图中圆圈所示:
根据规则3和规则4,在计算异或距离的时候:
- list1里面的ID必须一个比特和当前ID不同,理论上可以存储1/2的其他节点ID。
- list2里面的ID第1个比特必须和当前ID的第1个比特相同,第2比特必须不同,异或距离计算出来的值第1个比特必然是0。理论上可以有1/4的其他节点ID。
- list3里面的ID前2个比特必须和当前ID的前2个比特相同,第3比特必须不同,异或距离计算出来的值前2个比特必然是0。理论上可以有1/8的其他节点ID。
- ...
可以看到,每个列表里存储到其他节点确实在异或距离上是越来越近。这就是异或距离在DHT一致性哈希里的妙用。当限制每个list的容量为k时,可以动态根据节点的连通性维持每个list里的k个节点。
观察每个listi里的节点都有i-1个前缀相同,它们构成了一个前缀路由表。
[1] XOR
[2] 异或
[3] Kademlia, A P2P DHT
[4] xor distance, js code
[5] xor distance and routing table
--end--
以上是关于证明与计算: 从加密哈希函数到一致性哈希的主要内容,如果未能解决你的问题,请参考以下文章